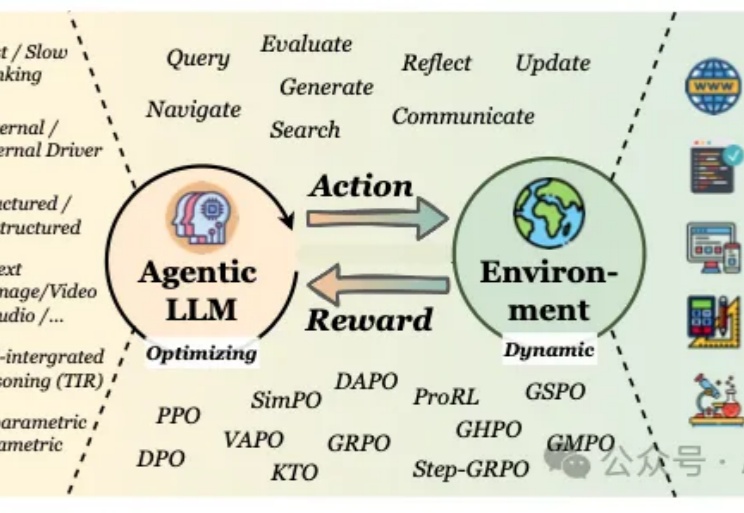
Agent的RL和LLM的RL是一回事吗?牛津用500+论文写成综述,一次说清Agentic RL
Agent的RL和LLM的RL是一回事吗?牛津用500+论文写成综述,一次说清Agentic RL当我们谈论大型语言模型(LLM)的"强化学习"(RL)时,我们在谈论什么?从去年至今,RL可以说是当前AI领域最炙手可热的词汇。
来自主题: AI技术研报
11234 点击 2025-11-18 15:11
 搜索
搜索
当我们谈论大型语言模型(LLM)的"强化学习"(RL)时,我们在谈论什么?从去年至今,RL可以说是当前AI领域最炙手可热的词汇。
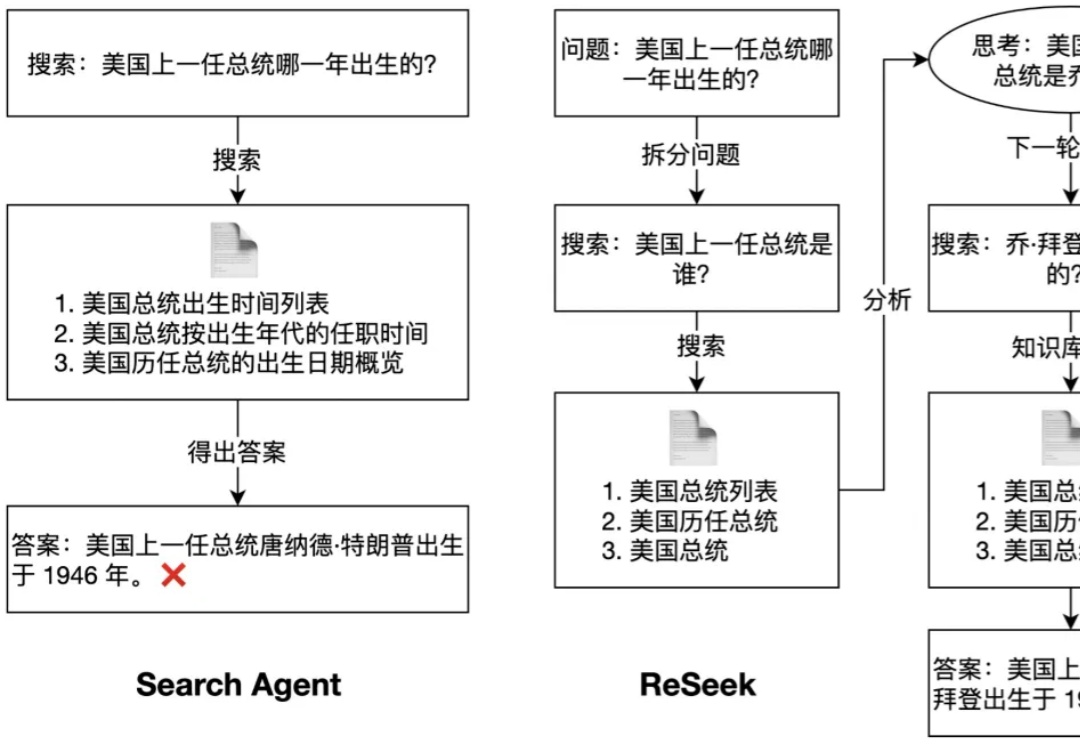
为了同时解决知识的实时性和推理的复杂性这两大挑战,搜索智能体(Search Agent)应运而生。它与 RAG 的核心区别在于,Search Agent 能够通过与实时搜索引擎进行多轮交互来分解并执行复杂任务。这种能力在人物画像构建,偏好搜索等任务中至关重要,因为它能模拟人类专家进行深度、实时的资料挖掘。
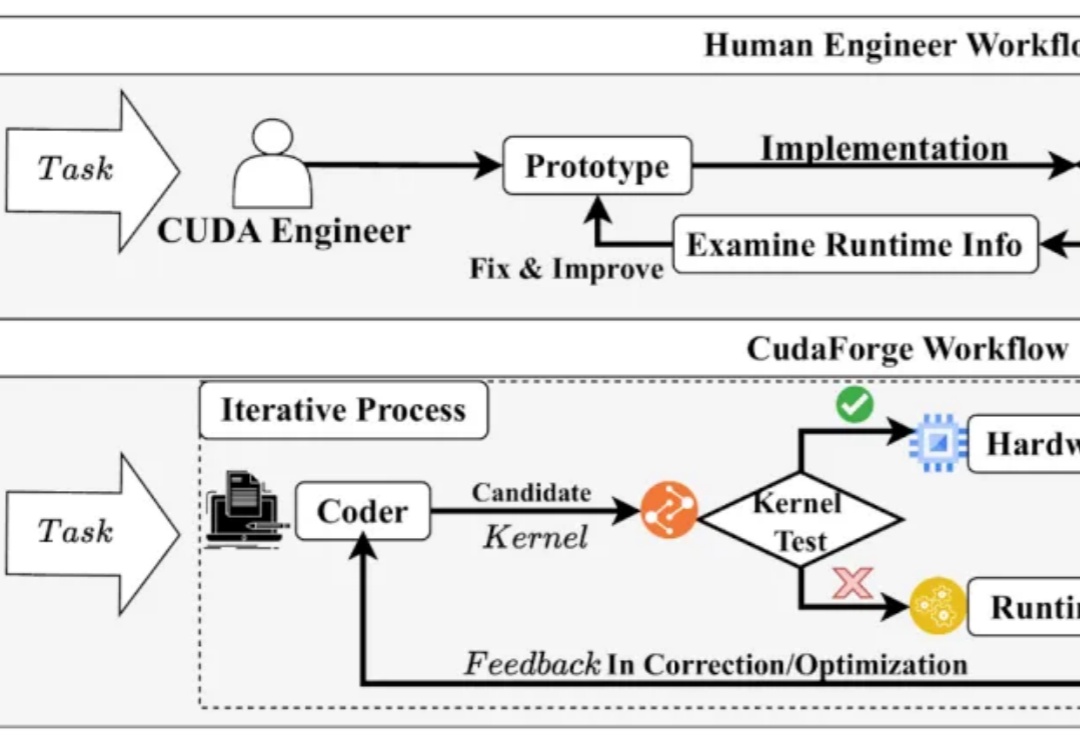
CUDA 代码的性能对于当今的模型训练与推理至关重要,然而手动编写优化 CUDA Kernel 需要很高的知识门槛和时间成本。与此同时,近年来 LLM 在 Code 领域获得了诸多成功。

中科大 LDS 实验室何向南、王翔团队与 Alpha Lab 张岸团队联合开源 MiniOneRec,推出生成式推荐首个完整的端到端开源框架,不仅在开源场景验证了生成式推荐 Scaling Law,还可轻量复现「OneRec」,为社区提供一站式的生成式推荐训练与研究平台。
「Voice Image」创始人 Nick Lahoika 出生在白俄罗斯,后来移民到爱沙尼亚才开始学习英语,跨语言的生活环境让他在很长一段时间内都对表达缺乏自信,直到遇到了一位专业声音教练。他才意识到表达是可以训练的,这也成为其创业的起点。
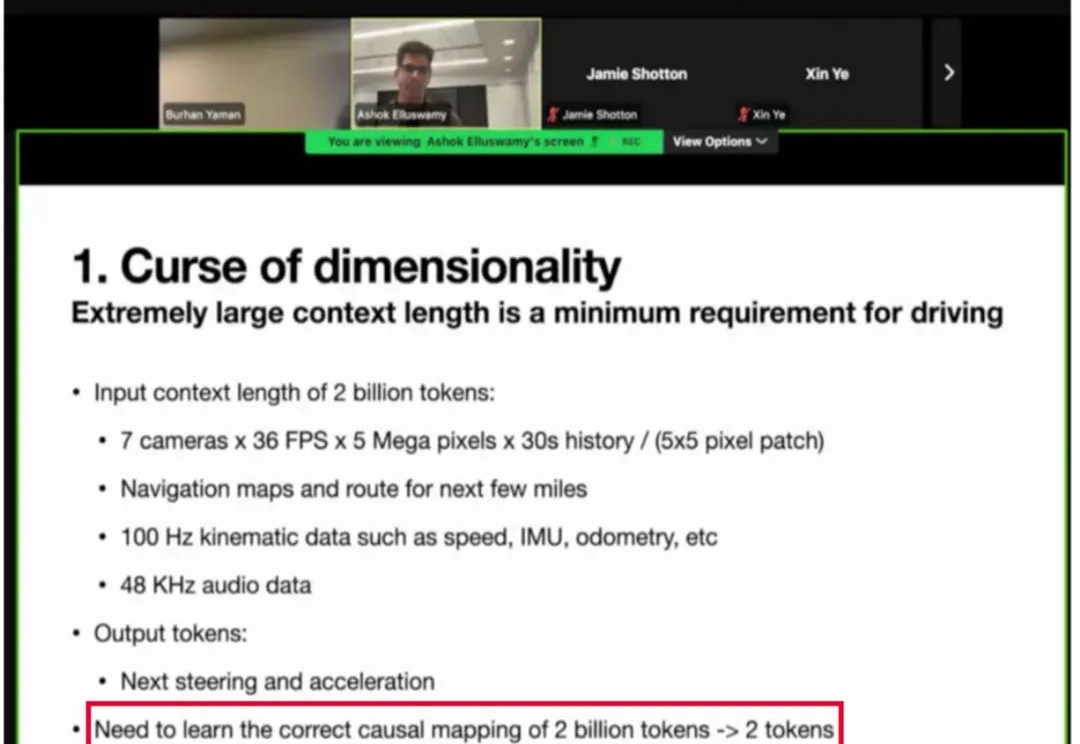
在自动驾驶领域,VLA 大模型正从学术前沿走向产业落地的 “深水区”。近日,特斯拉(Tesla)在 ICCV 的分享中,就将其面临的核心挑战之一公之于众 ——“监督稀疏”。
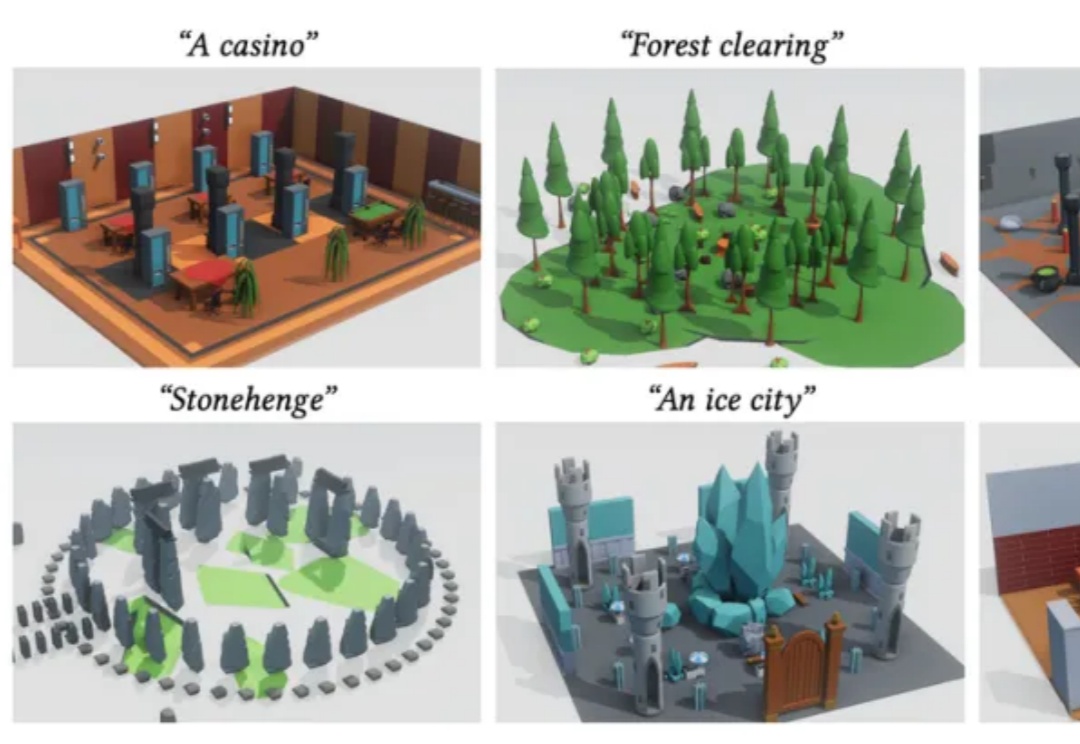
随着生成式 AI 的快速发展,从文本生成图像、视频,到构建完整的三维世界,AI “创造空间” 的能力正以前所未有的速度突破边界。然而,现有 3D 场景生成方法仍存在明显局限:模型往往直接输出每个物体的几何参数(位置、大小、方向等),结果容易出现漂浮、重叠、穿模等问题;场景结构缺乏逻辑一致性,难以编辑或复用,更无法像程序那样精确控制空间关系与生成逻辑。
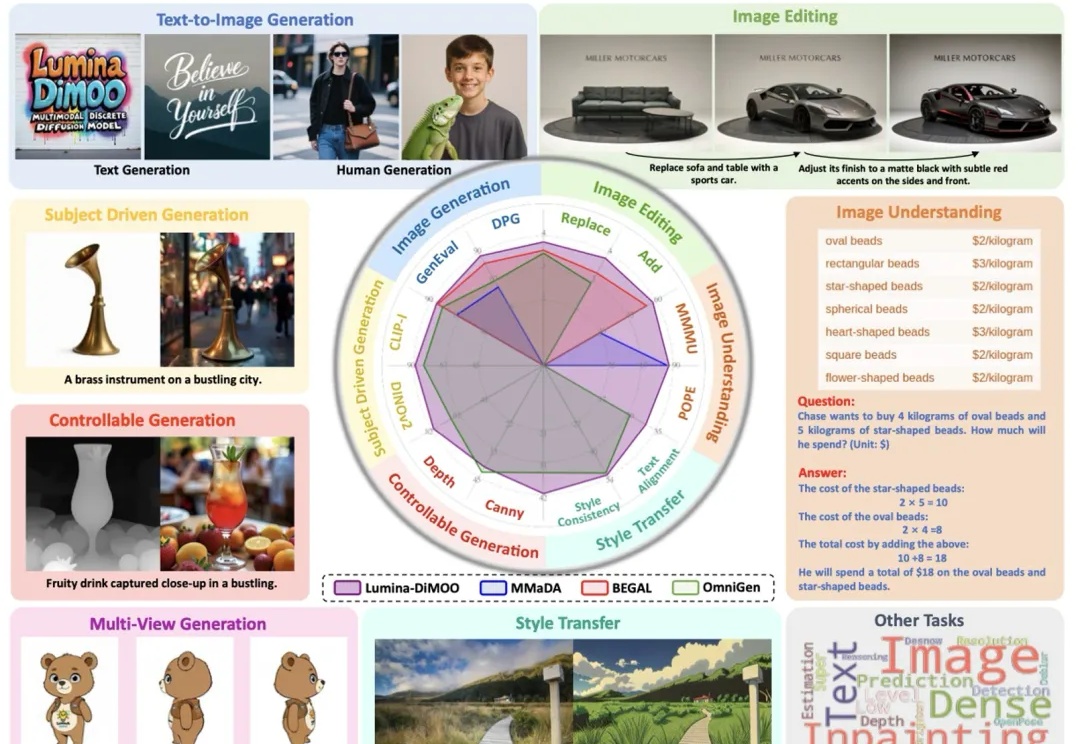
上海人工智能实验室推出了一款革新的多模态生成理解一体化的扩散语言模型 ——Lumina-DiMOO。基于离散扩散建模(Discrete Diffusion Modeling),Lumina-DiMOO 打破了多模态任务之间的壁垒,在同一离散扩散框架下,完成从 文本→图像、图像→图像、图像→文本的全栈能力闭环。

长期以来,多模态代码生成(Multimodal Code Generation)的训练严重依赖于特定任务的监督微调(SFT)。尽管这种范式在 Chart-to-code 等单一任务上取得了显著成功 ,但其 “狭隘的训练范围” 从根本上限制了模型的泛化能力,阻碍了通用视觉代码智能(Generalized VIsioN Code Intelligence)的发展 。
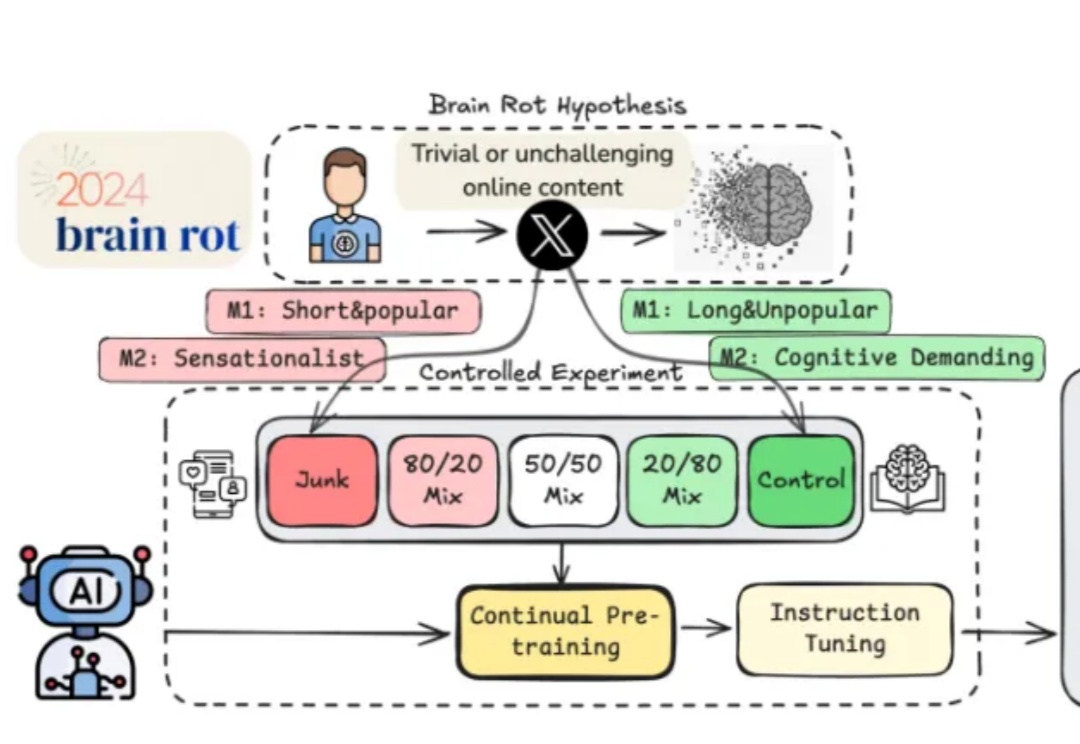
你知道有个全球年度词汇叫“脑损伤”(Brain Rot)吗?