# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Transformer 架构在过去几年中通过注意力机制在多个领域(如计算机视觉、自然语言处理和长序列任务)中取得了非凡的成就。然而,其核心组件「自注意力机制」 的计算复杂度随输入 token 数量呈二次方增长,导致资源消耗巨大,难以扩展到更长的序列或更大的模型。
Token Statistics Transformer (ToST) 提出了一种新的注意力机制,它的时间复杂度是线性的。通过对序列特征的统计建模,ToST 提高了序列处理任务中的效率。文章探讨了基于变分编码率缩减(Variational Rate Reduction, VRR)的框架,并通过实验验证了其在不同任务中的性能,通过革新传统注意力机制,解决了这些长期困扰 Transformer 架构的效率瓶颈。
ToST 也作为 Spotlight 论文,入选了 ICLR 2025 大会。

一直以来,自注意力机制依赖于对输入 token 两两相似性的计算,这一过程虽然有效,但其资源开销显著;尤其当输入 token 数量极大时,传统注意力机制(如 Transformer 中的全局注意力)在计算复杂度和内存使用上的瓶颈问题愈发显著。
为了应对这一挑战,本文提出了一种基于统计学特征的注意力机制:Token Statistics Self-Attention (TSSA)。它通过避免两两相似性的计算,仅依赖于 token 特征的统计量,显著降低了计算复杂度。
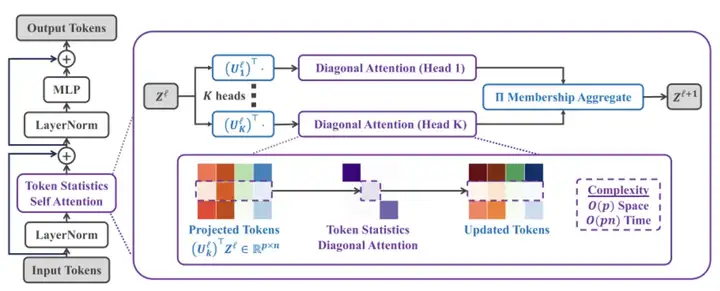
Token Statistics Transformer (ToST) 的架构。Token Statistics Self-Attention (TSSA) 运算符通过对投影后的 token 进行行标量化变换,从而实现了线性复杂度。
ToST 的核心方法是通过特定的概率分布函数对输入序列进行建模,减少冗余信息并提取关键特征。具体包括:
1. 统计特征提取:对序列中的每个 token 提取其统计特征。
2. 变分编码率缩减:利用 VRR 框架对特征进行压缩,减少信息冗余。
3. 线性复杂度实现:通过一系列优化,其计算复杂度从 O (n²) 降低为 O (n)。
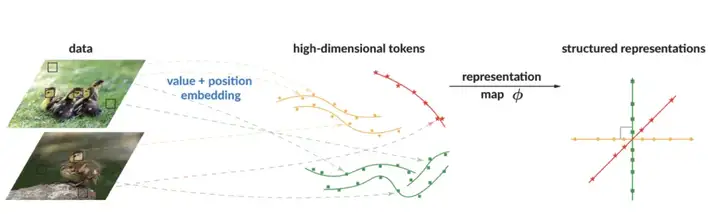
ToST 的方法概述。在 CRATE 的理论基础上,ToST 通过几何空间的结构化特征实现 token 分组和映射。
网络架构的推导
该团队通过扩展先前的 CRATE 工作推导出网络架构。CRATE 显示,一种 Transformer 风格的架构可以通过 "白盒" 架构设计自然生成,其中网络的每一层都旨在实现最大编码率缩减目标 (MCR²) 的增量优化步骤。
具体来说,该团队推导了 MCR² 目标的一个新颖的变分形式,并表明通过对该变分目标进行展开梯度下降所得到的架构会引入一种新的注意力模块,称为 Token Statistics Self-Attention (TSSA)。TSSA 拥有线性的计算和内存复杂度,并从根本上不同于典型的注意力架构,其后者通过计算 token 之间的两两相似性来实现。

关键公式 MCR² 目标函数定义
1. 线性时间注意力机制:Token Statistics Self-Attention (TSSA)
通过白盒设计方法(algorithmic unrolling),TSSA 从最大编码率减少(Maximal Coding Rate Reduction, MCR² )的变分形式中推导而来。
传统 Transformer 依赖于 pairwise 相似度计算,而 TSSA 则基于 token 特征的统计量构建注意力机制,其计算复杂度从 O (n²) 降低为 O (n),内存占用同样显著减少。
2. 创新性的网络结构:Token Statistics Transformer (ToST)
ToST 通过将 TSSA 替代标准的自注意力模块,不仅实现了显著的效率提升,还增强了模型的可解释性。
与传统模型不同,ToST 架构中的注意力操作基于统计量的低秩投影,通过减少不必要的计算路径,大幅优化了资源使用。
3. 理论支撑与数学推导
基于 MCR² 的变分形式,提出了一种新颖的压缩项公式,可对大型矩阵进行有效的特征提取。
通过设计数据相关的低秩投影,TSSA 在保留关键信息的同时,消除了冗余方向。
实验覆盖了自然言语处理(NLP)、计算机视觉(CV)等多个领域的任务,包括文本分类、机器翻译、图像识别等。结果表明,ToST 在保证模型性能的同时,大幅降低了计算资源消耗。
实验结果显示,与现有的注意力机制相比,TSSA 的时间和内存复杂度更低。具体而言,TSSA 的复杂度为 O (pn),显著优于传统 Transformer 的 O (n²)。
ToST 在计算时间和内存使用上均随序列长度实现线性扩展,使其显著优于标准 Transformer 的效率。如下:
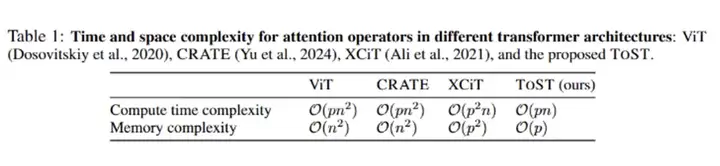
复杂度分析对比
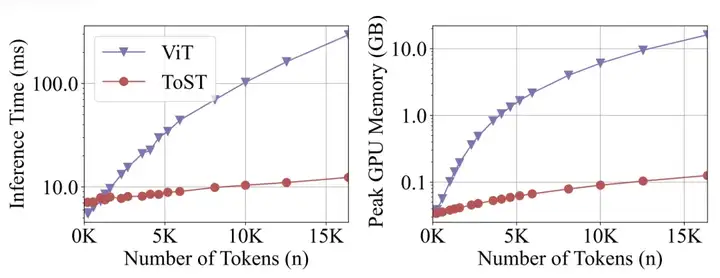
在 GPU 上评估的速度和内存使用对比
在 ImageNet-1k 等主流视觉数据集上的实验表明,ToST 的性能可与传统 Transformer 架构(如 ViT 和 XCiT)相媲美,同时显著减少了模型参数量和计算开销。
迁移学习实验中,ToST 在 CIFAR、Oxford Flowers 等数据集上的表现进一步验证了其在多种视觉任务中的适应性。
结果展示了与传统 Transformer 相当的性能,同时在计算效率上显著更高。
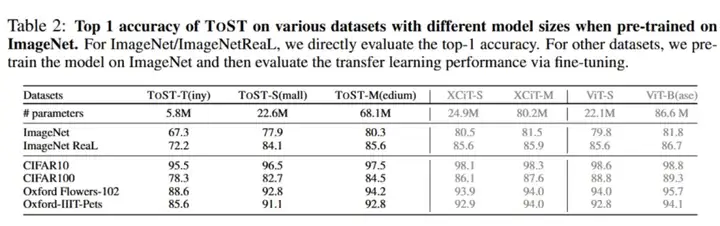
在长序列任务基准测试(如 Long-Range Arena)中,ToST 展现出优异的长距离建模能力,其性能超越了现有 Transformer 变体。
ToST 可以扩展并适用于多种任务场景,包括因果语言建模。针对语言建模,ToST 采用了一种因果版本的 TSSA,在多个数据集上实现了高效的预测能力。此外,即使在参数规模扩大的情况下,ToST 依然保持了优异的时间和内存效率。
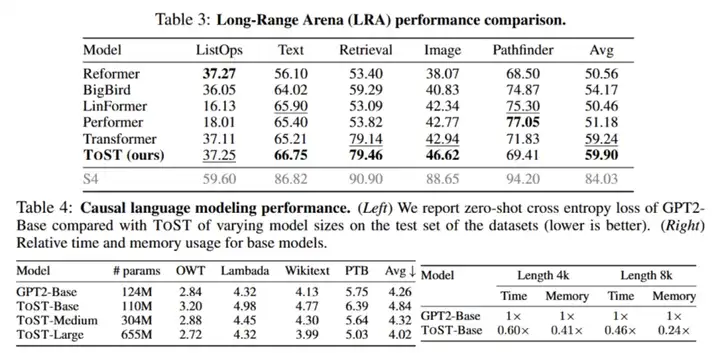
NLP 任务中的表现
由于 ToST 是通过展开从学习目标中推导出来的,我们可以以有原理支持的方式逐层分析学习到的模型行为。
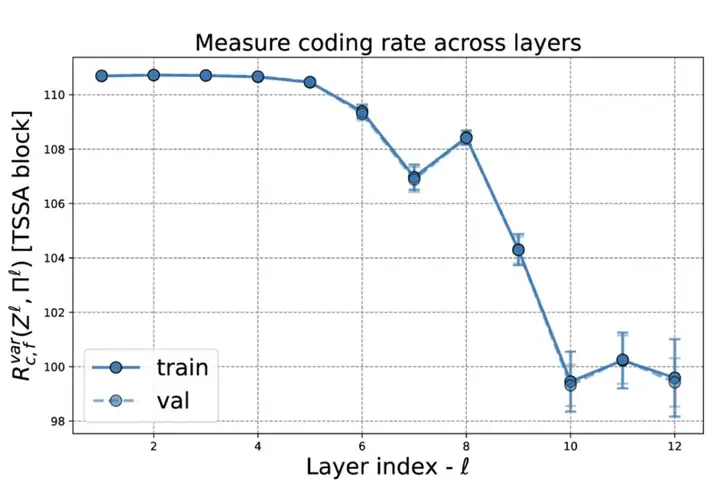
ToST 模型不同层次的 TSSA 输出的变分压缩项
ToST 通过统计量驱动的注意力机制,使每一层的注意力操作更加透明,便于解释和分析。其分组机制展现了 token 特征在低维空间中的聚类效果,直观反映了模型的决策过程。
ToST 在无需复杂的自监督训练的情况下,自然生成了可解释的注意力模式。

倒数第二个全局类注意力层中最后一个头部的 [CLS] token 注意力图的比较

在 TSSA 层中,可视化估计的隶属矩阵 Π 的每一行(经过重塑后)
1. 大模型的高效化
随着语言模型、生成模型和多模态模型规模的持续扩展,计算效率成为核心瓶颈。ToST 展示的统计量驱动注意力机制,为实现线性复杂度的大模型提供了可能性。
2. 推动 Transformer 的普适化应用
高效的注意力机制使得 ToST 能够更广泛地应用于资源受限场景,如边缘计算、实时系统、嵌入式设备等。这为人工智能技术从中心化计算向分布式、边缘化方向的发展奠定了基础。
3. 多模态融合的可能性
ToST 的低复杂度机制为处理多模态长序列任务提供了新的技术框架,使未来多模态大模型在生成、分析和交互中的效率显著提升。
4. 促进跨学科应用
ToST 对数学理论与工程实现的有机结合,不仅在传统 AI 任务中表现突出,还可能推动其在新兴领域(如量子计算、生物信息学和材料设计)中的应用。
Token Statistics Transformer (ToST) 重塑了注意力机制,它不需要计算 token 之间的两两交互,而是基于投影后 token 特征的二阶矩统计量构建,其基于数据压缩和表示学习的理论原则目标,为 Transformer 的发展开辟了新路径。其基于统计特性的低复杂度设计,不仅优化了现有架构的性能,还为未来大模型的高效化、多模态融合和跨学科应用提供了启示。
文章来自于“机器之心”,作者“吴梓阳”。



