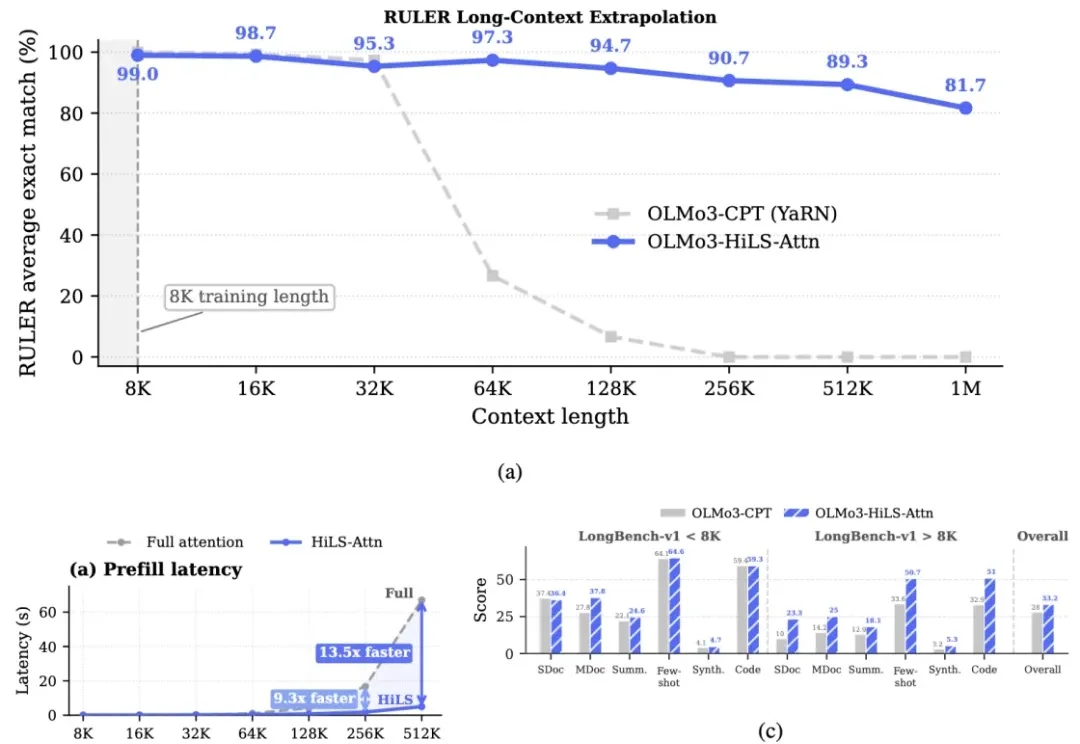
在数学上把稀疏注意力做对!腾讯Hy开源HiLS-Attention: 计算更少效果更好, 外推512倍
在数学上把稀疏注意力做对!腾讯Hy开源HiLS-Attention: 计算更少效果更好, 外推512倍让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。
来自主题: AI技术研报
9088 点击 2026-07-20 15:19
 搜索
搜索
让大模型 "读得更长" 一直是 Agent、深度推理和海量资料整合等场景的刚需,但标准全注意力机制的计算量随序列长度呈平方级增长,始终是横亘在长上下文建模面前的三座大山。

Kimi K3 是一个 2.8 万亿参数模型,基于 KDA 混合线性注意力机制(Kimi Delta Attention)和注意力残差(Attention Residuals)技术构建,原生支持视觉理解,并拥有 100 万 token 上下文窗口。它是全球首个开源的 3 万亿级别模型,面向长程编程、知识工作和推理等前沿智能场景而设计。

独家获悉,字节跳动日前低调公布全球首个25B级、基于混合专家 (MoE) -扩散自注意力机制(DiT) 的开源增强统一多模态模型Mamoda2.5。Mamoda2.5依托Qwen3-VL-8B、128 个专家,Top-8 路由的MoE+DiT架构搭建,最终模型参数高达250亿,而每次仅激活约30亿参数(约12%)。

就在大家都急头白脸地等待DeepSeek-V4的时候,冷不丁一篇新论文引起了网友们的注意—— 提出新稀疏注意力机制HISA(分层索引稀疏注意力),突破64K上下文的索引瓶颈,相比DeepSeek正在用的DSA(DeepSeek Sparse Attention)提速2-4倍。

南京大学与北京大学提出MorphAny3D,无需训练即可让三维生成模型实现跨类别平滑变形。通过创新注意力机制融合源与目标特征,精准控制结构与时序,轻松完成复杂变形,效果远超传统方法。

近日,深度学习领域重要底层优化技术 FlashAttention 迎来大版本更新。FlashAttention 核心作者、普林斯顿大学助理教授 Tri Dao 表示,在 Blackwell GPU 上,即使瓶颈截然不同,注意力机制的执行速度现在也几乎与矩阵乘法一样快了!

清华大学团队推出的Dolphin模型突破了「高性能必高能耗」的瓶颈:仅用6M参数(较主流模型减半),通过离散化视觉编码和物理启发的热扩散注意力机制,实现单次推理即可精准分离语音,速度提升6倍以上,在多项基准测试中刷新纪录,为智能助听器、手机等端侧设备部署高清语音分离开辟新路。
不管Pony Alpha是不是智谱的,下一代旗舰大模型GLM-5都要来了。GLM-5采用了DeepSeek-V3/V3.2架构,包括稀疏注意力机制(DSA)和多Token预测(MTP),总参数量745B,是上一代GLM-4.7的2倍。

256K文本预加载提速超50%,还解锁了1M上下文窗口。

Transformer 已经改变了世界,但也并非完美,依然还是有竞争者,比如线性递归(Linear Recurrences)或状态空间模型(SSM)。这些新方法希望能够在保持模型质量的同时显著提升计算性能和效率。