# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
DeepSeek新注意力机制论文一出,再次引爆讨论热度。
依然是熟悉的画风,熟悉的味道——
那边马斯克疯狂烧了20万张卡训出Grok 3,这厢DeepSeek重点关注的依然是压缩计算和推理成本。
具体来说,新论文提出了一种可原生训练的稀疏注意力机制,名为NSA(Native Sparse Attention)。
目的很明确:解决大模型上下文建模中,标准注意力机制造成的计算成本高昂的问题。
效果也很明显:
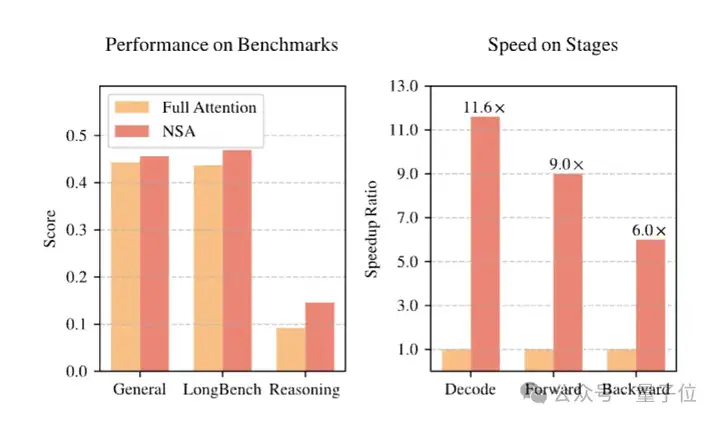
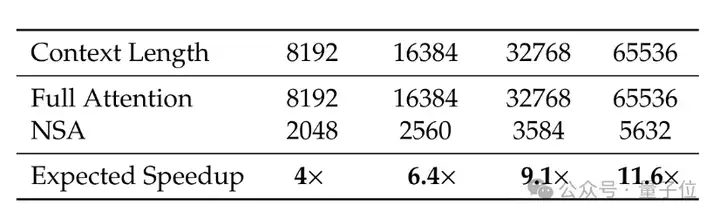
实验表明,在解码64k上下文时,基于softmax架构的注意力计算占到总延迟的70%-80%。而在不影响性能的前提下,NSA在64k上下文的解码、前向传播和反向传播中均实现了显著加速。
其中前向传播速度最高可提升9倍,反向传播速度最高可提升6倍,解码速度提升可达11.6倍。
正如不少网友提到的,NSA意味着DeepSeek找到了优化注意力的方法,可以用更少的算力更加高效地训练大模型,并且,他们还把这些“秘籍”公开了出来。

刚刚加入OpenAI不久的ViT核心作者Lucas Beyer也不禁开麦:粉了粉了。
另一点受到关注的是,这篇论文的作者可以说是DeepSeek系列大模型原班人马,梁文锋本人亦在其列——
论文还是梁文锋亲自传上arXiv的。

来看论文细节。
NSA的核心方法包括:
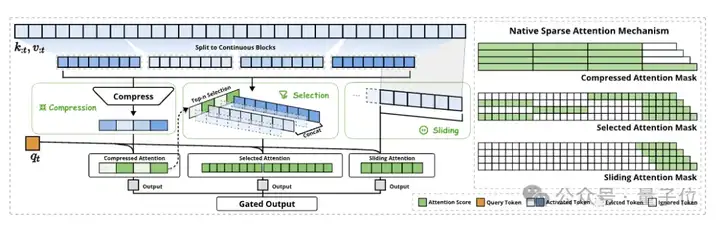
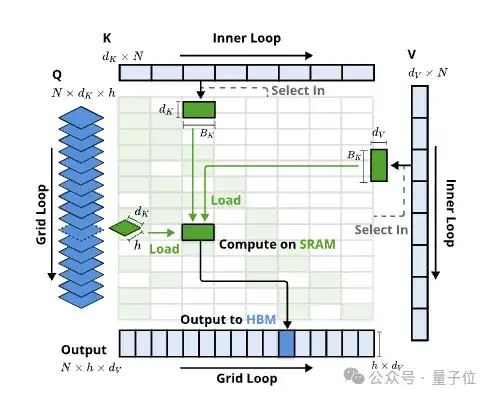
整体框架上,NSA是用更紧凑的键值对替代原始注意力中的键值对,通过压缩、选择和滑动窗口(sliding window)三种映射策略得到优化注意力输出,保持高稀疏率。
采取分层设计的好处是:
具体到算法设计上,粗粒度Token压缩通过将连续的Token聚合成块级表示,可以捕获全局语义信息,同时减少注意力的计算负担。
细粒度Token选择从序列中选择最重要的Token,保留关键的局部信息。
滑动窗口则避免了局部模式的过度优势——在注意力机制中,局部模式往往会主导学习过程,阻止模型有效地从压缩和选择Token中学习。
为了实现以上创新,DeepSeek官方还强调了两方面的关键工作:
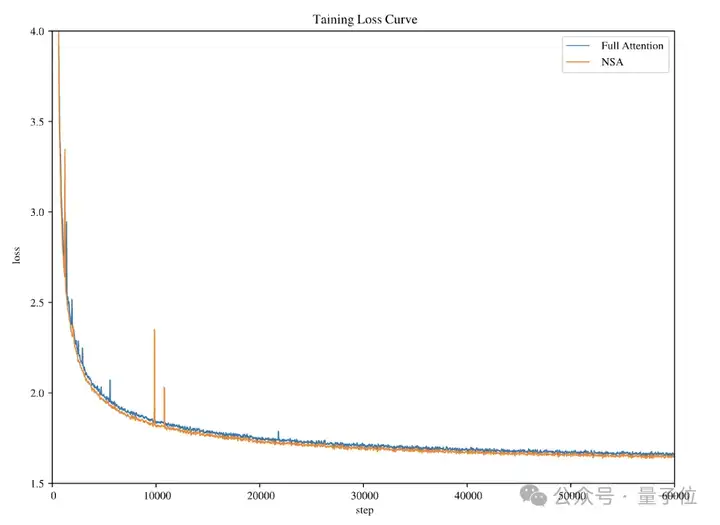
研究人员用27B参数规模的模型进行了实验,结果显示,全注意力机制和NSA在预训练损失方面,都表现出了稳定的收敛性,并且NSA实现了更低的损失值。
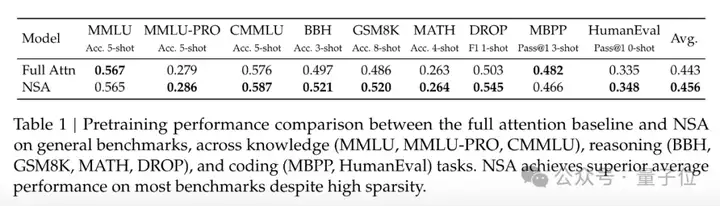
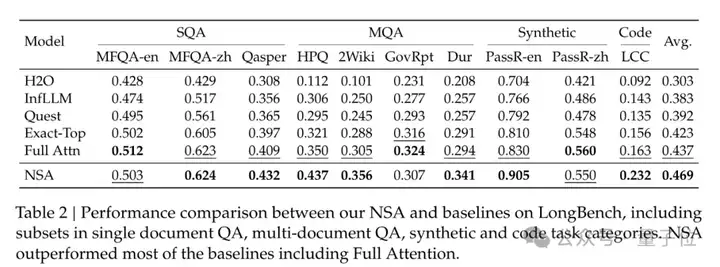
在包含知识、推理和编码能力的多个通用基准测试中,与全注意力模型相比,NSA模型性能不降反超,在推理任务DROP中提升尤为明显。
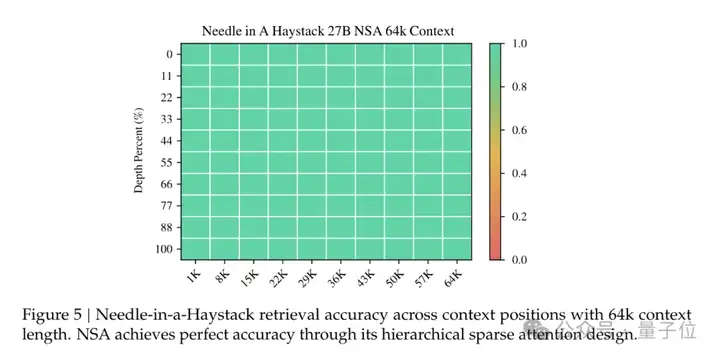
长上下文方面,64k上下文的“大海捞针”测试里,NSA完美过关。
在需要复杂长下文推理的各项任务中,NSA的表现也基本超过了包括全注意力模型在内的基线模型。
而在思维链推理评估中,通过知识蒸馏和监督微调,在8k和16k上下文设置下,AIME任务中NSA-R的得分均超过了全注意力模型。
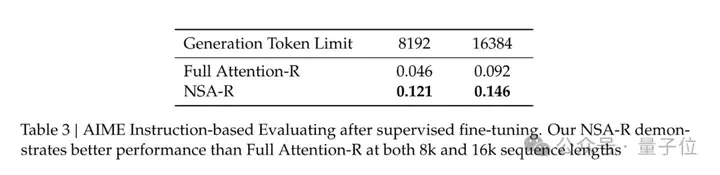
这表明,NSA预训练的稀疏注意力模式能有效捕捉长距离逻辑依赖,且其硬件对齐设计可支持不断增加的推理深度。
效率方面,在8-GPU A100系统上,NSA的训练加速效果会随上下文长度的增加而增强。在64k上下文长度时,前向传播速度最高可提升9倍,反向传播速度最高可提升6倍,解码速度提升可达11.6倍。
有意思的是,在马斯克推出Grok 3炸场之时,不少人感慨:“大力出奇迹”在大模型训练里仍然奏效——
在Grok 3成为大模型竞技场首个突破1400分模型的背后,是惊人的10万卡(后来扩展到20万)H100集群。
但现在,DeepSeek为代表的效率派们显然在引发另一种方向上的思考:通往AGI的路,可以更高效,更本地化,更人人可用。
论文地址:
https://arxiv.org/abs/2502.11089
文章来自于“量子位”,作者“鱼羊”。




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
