
全球首个:隐空间世界模型,打通长时序双向物理因果链了!
全球首个:隐空间世界模型,打通长时序双向物理因果链了!你从桌上端起一杯水,大脑用了不到一秒,同时完成三件事: 估算杯子的重量,预判水面晃动的幅度,顺便绕开了旁边那个玻璃杯。
来自主题: AI技术研报
8767 点击 2026-06-30 09:53
 搜索
搜索
你从桌上端起一杯水,大脑用了不到一秒,同时完成三件事: 估算杯子的重量,预判水面晃动的幅度,顺便绕开了旁边那个玻璃杯。

在世界模型这条路上,行业一直卡在一个几乎无解的矛盾里:想要更真实的长程模拟,就必须给模型更深的计算;可一旦把模型做得更深,部署成本、参数规模和误差累积又会迅速抬头。结果就是,大家都知道世界模型要 “想得更久”,却很难让它在现实系统里 “算得起、跑得稳”。
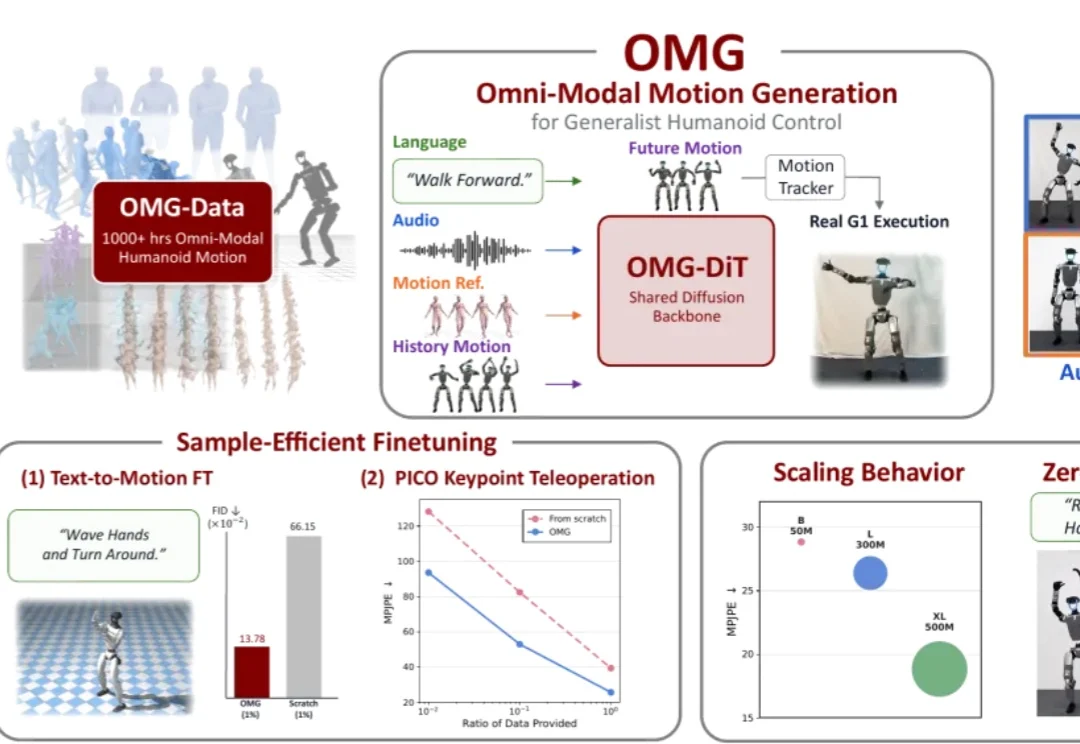
现阶段大多数人形机器人的运动控制还局限于 “有参考才能动” 的被动跟踪模式。

硅谷著名科技播客主持人 Dwarkesh Patel 最近抛出了一个问题:AI 的下一代训练范式会是什么?
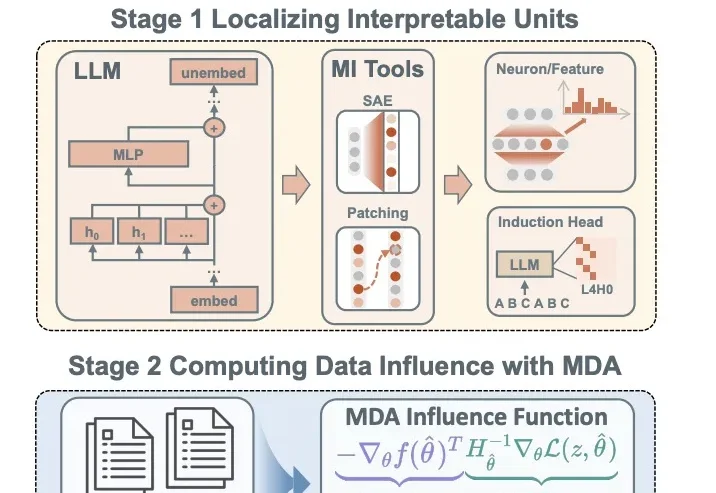
近年来,大语言模型展现出了越来越强的能力,从上下文学习(In-Context Learning, ICL)到复杂推理、代码生成,这些能力不断刷新人们对模型能力边界的认知。
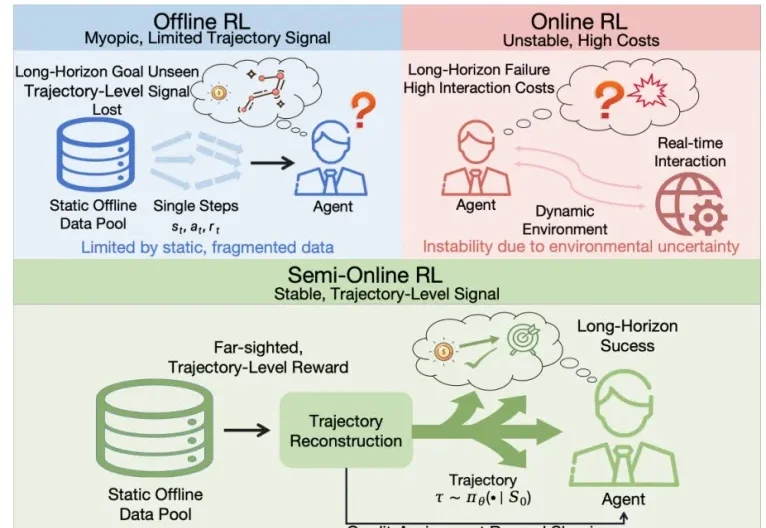
想训练能自动操作手机的GUI(图形用户界面)智能体,总会遇到两难困境:

这篇来自 Interlatent(一家聚焦具身智能后训练与部署的早期创业公司) 的文章,试图从第一性原理出发,把现代 AI 机器人技术重新讲清楚:一个机器人到底如何理解世界,如何生成动作,又为什么会在数据、延迟和泛化上遇到如此多的困难。
清华系物理AI企业「清研精准」已于近日完成数亿元B3轮融资,本轮融资由北京市绿色能源基金、北汽产投领投,裕隆集团跟投。据悉,该轮资金将会用于核心人才招募、多模态数采设备的研发与规模化部署,以及算力采购与模型训练基础设施建设等方向。
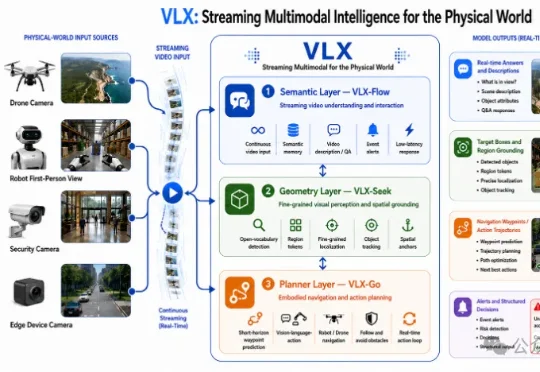
刚刚,Om AI发布全球首个面向物理世界的端侧流式多模态模型系列——VLX。VLX主打真实世界的端侧与具身场景,总共三款模型,三天连发:这三款模型连起来,不仅构成了多模态模型持续感知、精准定位、行动决策的能力闭环。
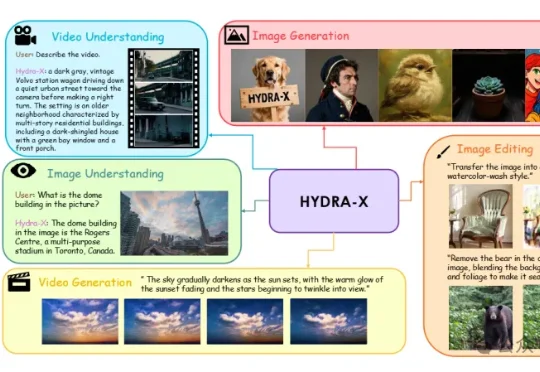
南大王利民团队&腾讯混元的HYDRA系列(HYDRA,HYDRA-X)工作挑战了这个惯例,用一个基于ViT的统一视觉Tokenizer,帮助原生多模态模型更好地“看懂”和“创作”。训练一个基于ViT的Unified Tokenizer,使其同时具有理解和生成的能力,进而同时作为理解和生成的Autoencoder,来支持原生多模态模型(Unified Multimodal Models)的训练。