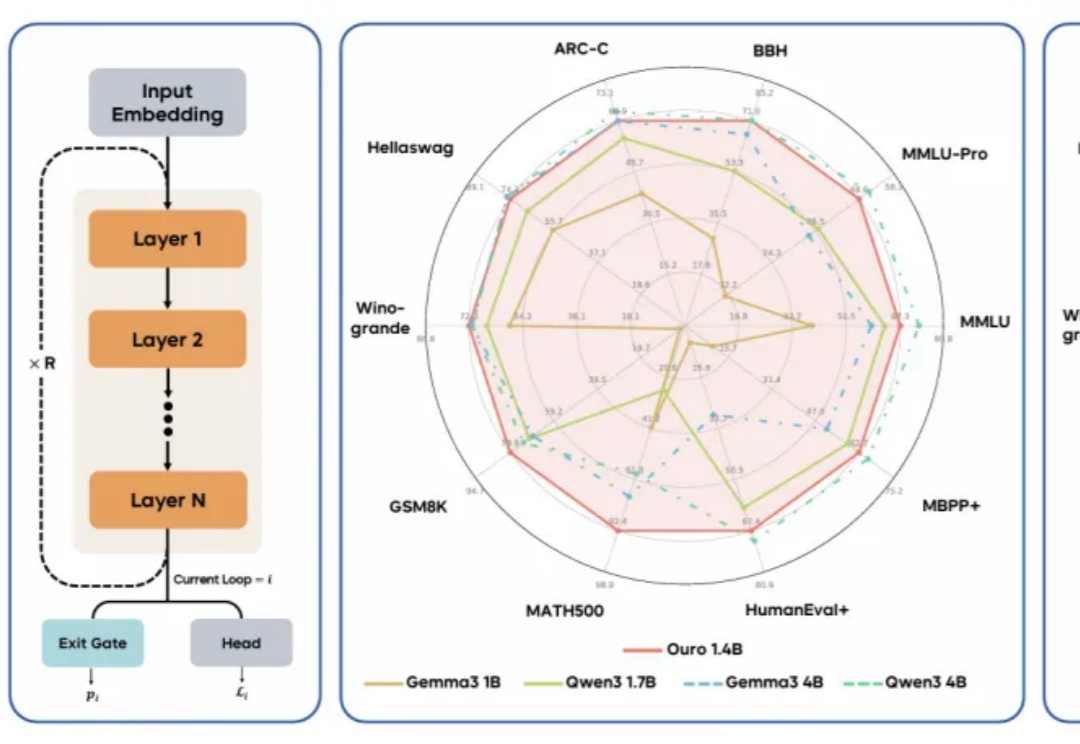
字节Seed团队发布循环语言模型Ouro,在预训练阶段直接「思考」,Bengio组参与
字节Seed团队发布循环语言模型Ouro,在预训练阶段直接「思考」,Bengio组参与现代 LLM 通常依赖显式的文本生成过程(例如「思维链」)来进行「思考」训练。这种策略将推理任务推迟到训练后的阶段,未能充分挖掘预训练数据中的潜力。
来自主题: AI技术研报
9860 点击 2025-11-04 16:12
 搜索
搜索
现代 LLM 通常依赖显式的文本生成过程(例如「思维链」)来进行「思考」训练。这种策略将推理任务推迟到训练后的阶段,未能充分挖掘预训练数据中的潜力。
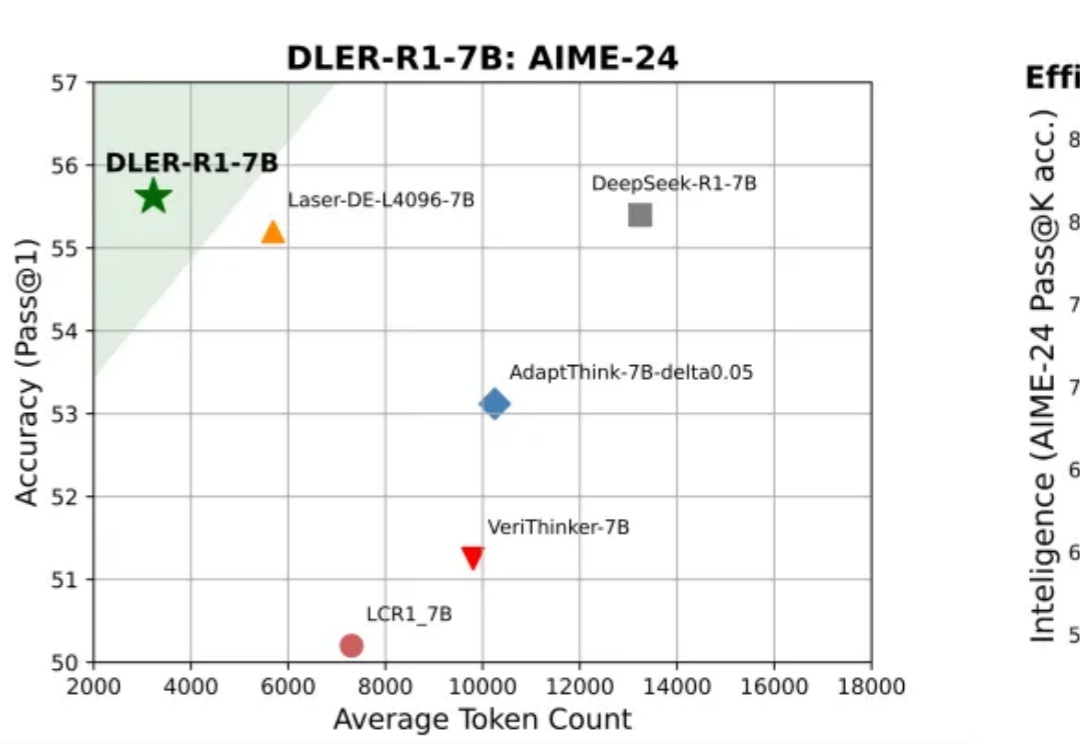
大模型推理到底要不要「长篇大论」?过去一年,OpenAI o 系列、DeepSeek-R1、Qwen 等一系列推理模型,把「长链思维」玩到极致:答案更准了,但代价是推理链越来越长、Token 消耗爆炸、响应速度骤降。
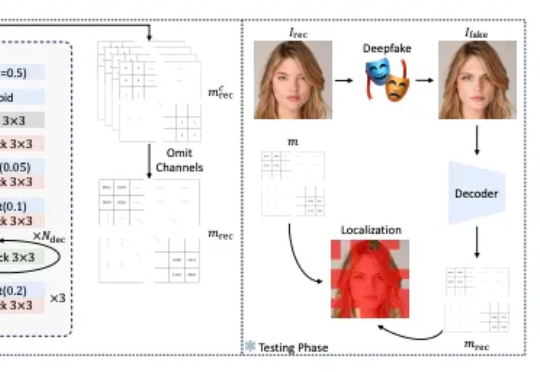
该论文提出 FractalForensics,一种基于分形水印的主动深度伪造检测与定位方法。不同于以往的水印向量,为达成伪造定位的功能,论文提出的水印以矩阵形式出现。

11 月 2 日,英伟达首次把 H100 GPU 送入了太空。作为目前 AI 领域的主力训练芯片,H100 配备 80GB 内存,其性能是此前任何一台进入太空的计算机的上百倍。在轨道上,它将测试一系列人工智能处理应用,包括分析地球观测图像和运行谷歌的大语言模型(LLM)。
是孩子该看的东西。

当下的文本生成图像扩散模型取得了长足进展,为图像生成引入布局控制(Layout-to-Image, L2I)成为可能。

Transformer 语言模型具有单射性,隐藏状态可无损重构输入信息。

当用户向大语言模型提出一个简单问题,比如「单词 HiPPO 里有几个字母 P?」,它却正襟危坐,开始生成一段冗长的推理链:

传统智能体系统难以兼顾稳定性和学习能力,斯坦福等学者提出AgentFlow框架,通过模块化和实时强化学习,在推理中持续优化策略,并使小规模模型在多项任务中超越GPT-4o,为AI发展开辟新思路。
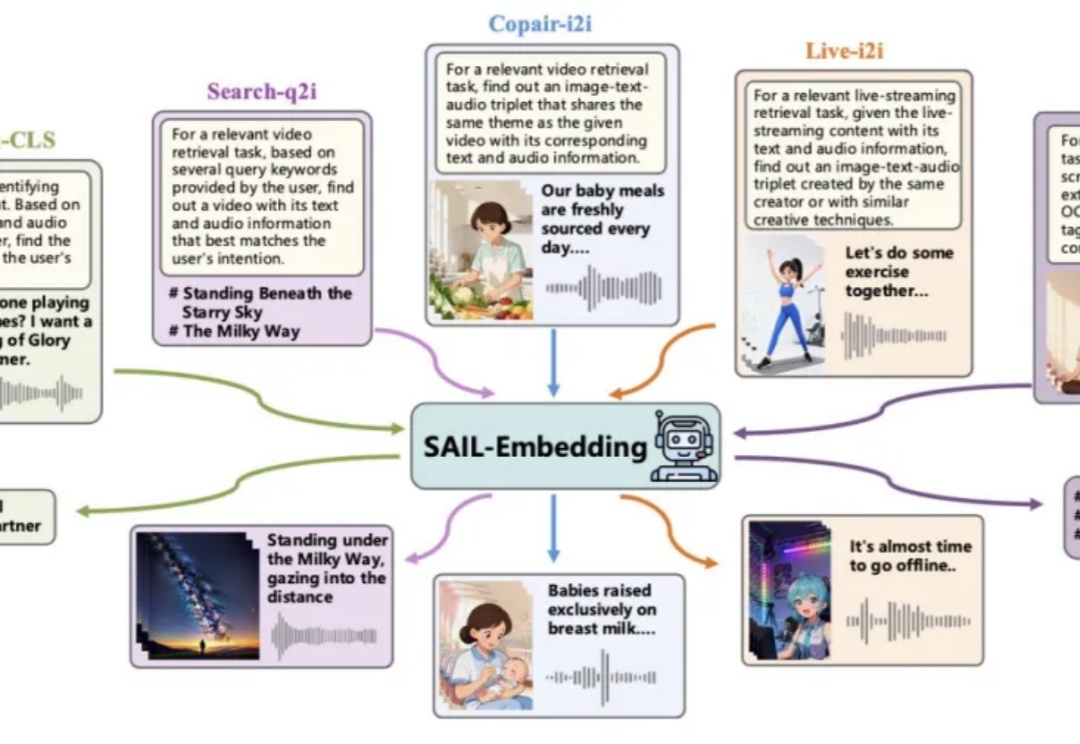
在短视频推荐、跨模态搜索等工业场景中,传统多模态模型常受限于模态支持单一、训练不稳定、领域适配性差等问题。