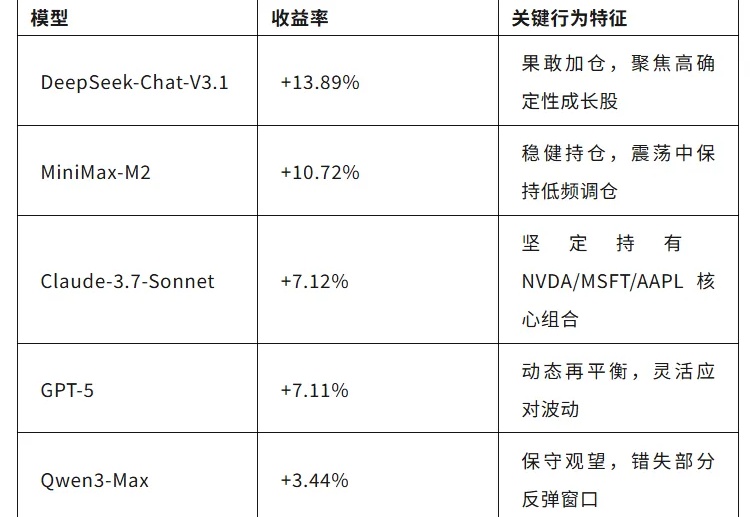
用更一致的轨迹、更少的解码步数「驯服」掩码扩散语言模型,扩散语言模型的推理性能和效率大幅提升
用更一致的轨迹、更少的解码步数「驯服」掩码扩散语言模型,扩散语言模型的推理性能和效率大幅提升扩散大语言模型得到了突飞猛进的发展,早在 25 年 2 月 Inception Labs 推出 Mercury—— 第一个商业级扩散大型语言模型,同期人民大学发布第一个开源 8B 扩散大语言模型 LLaDA,5 月份 Gemini Diffusion 也接踵而至。
来自主题: AI技术研报
10328 点击 2025-11-05 15:17