扩展外部测试时Scaling Law,中关村学院新发现:轻量级验证器可解锁LLM推理最优选择
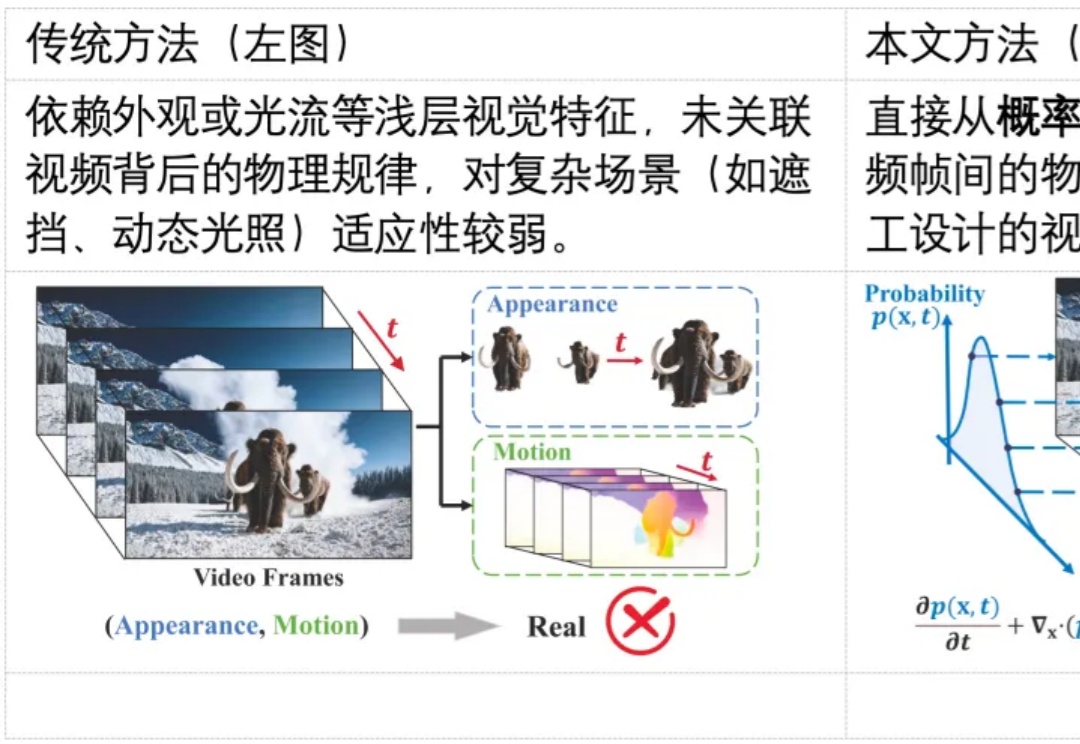
扩展外部测试时Scaling Law,中关村学院新发现:轻量级验证器可解锁LLM推理最优选择在大语言模型(LLM)席卷各类复杂任务的今天,“测试时扩展”(Test-Time Scaling,TTS)已成为提升模型推理能力的核心思路 —— 简单来说,就是在模型 “答题” 时分配更多的计算资源来让它表现更好。严格来说,Test-Time Scaling 分成两类:
来自主题: AI技术研报
8412 点击 2025-11-06 14:59