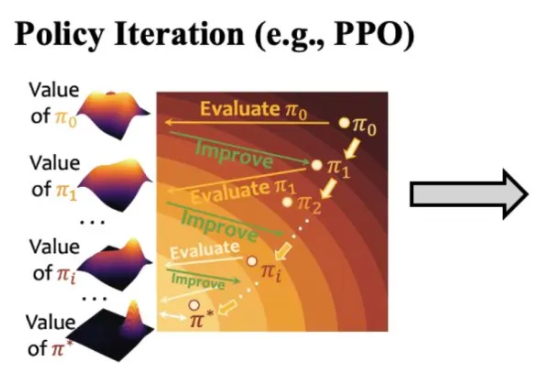
港科提出新算法革新大模型推理范式:随机策略估值竟成LLM数学推理「神操作」
港科提出新算法革新大模型推理范式:随机策略估值竟成LLM数学推理「神操作」论文第一作者何浩然是香港科技大学博士生,研究方向包括强化学习和基础模型等,研究目标是通过经验和奖励激发超级智能。共同第一作者叶语霄是香港科技大学一年级博士。通讯作者为香港科技大学电子及计算机工程系、计
来自主题: AI技术研报
9197 点击 2025-11-01 09:24
 搜索
搜索
论文第一作者何浩然是香港科技大学博士生,研究方向包括强化学习和基础模型等,研究目标是通过经验和奖励激发超级智能。共同第一作者叶语霄是香港科技大学一年级博士。通讯作者为香港科技大学电子及计算机工程系、计

在NeurIPS 2025论文中,来自「南京理工大学、中南大学、南京林业大学」的研究团队提出了一个极具突破性的框架——VIST(Vision-centric Token Compression in LLM),为大语言模型的长文本高效推理提供了全新的「视觉解决方案」。值得注意的是,这一思路与近期引起广泛关注的DeepSeek-OCR的核心理念不谋而合。
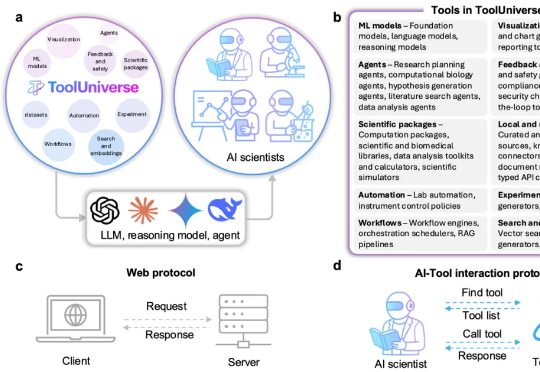
近日,OpenAI 宣称要在 2028 年实现让 AI 完全自主做研究,一下子又把焦点聚在了AI 科学家。 过去,AI 只是作为“助理”辅助研究者们进行科学研究。现在,美国哈佛大学与美国麻省理工学院联

月之暗面最新发布的开源Kimi Linear架构,用一种全新的注意力机制,在相同训练条件下首次超越了全注意力模型。在长上下文任务中,它不仅减少了75%的KV缓存需求,还实现了高达6倍的推理加速。
在多模态生成领域,由视频生成音频(Video-to-Audio,V2A)的任务要求模型理解视频语义,还要在时间维度上精准对齐声音与动态。早期的 V2A 方法采用自回归(Auto-Regressive)的方式将视频特征作为前缀来逐个生成音频 token,或者以掩码预测(Mask-Prediction)的方式并行地预测音频 token,逐步生成完整音频。
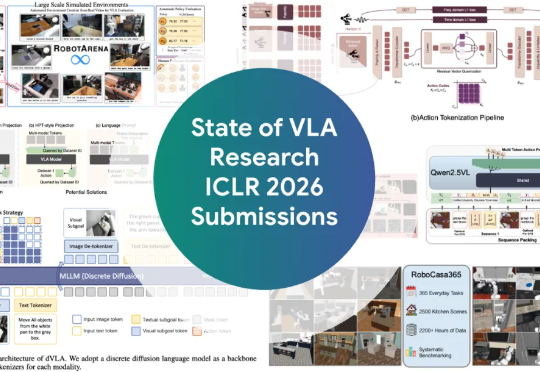
ICLR 2026爆火领域VLA(Vision-Language-Action,视觉-语言-动作)全面综述来了! 如果你还不了解VLA是什么,以及这个让机器人学者集体兴奋的领域进展如何,看这一篇就够了。

AI已经不止会写代码、画图、做PPT,它也开始「上班」了!CMU与斯坦福的研究团队首次完整追踪了AI的工作过程,发现一个惊人事实:它并不是在模仿人类,而是在用编程的方式重写工作的定义。这场关于「谁在工作」的实验,正在重构未来职场的逻辑。

月之暗面在这一方向有所突破。在一篇新的技术报告中,他们提出了一种新的混合线性注意力架构 ——Kimi Linear。该架构在各种场景中都优于传统的全注意力方法,包括短文本、长文本以及强化学习的 scaling 机制。

厦门大学和腾讯合作的最新论文《FlashWorld: High-quality 3D Scene Generation within Seconds》获得了海内外的广泛关注,在当日 Huggingface Daily Paper 榜单位列第一,并在 X 上获得 AK、Midjourney 创始人、SuperSplat 创始人等 AI 大佬点赞转发。
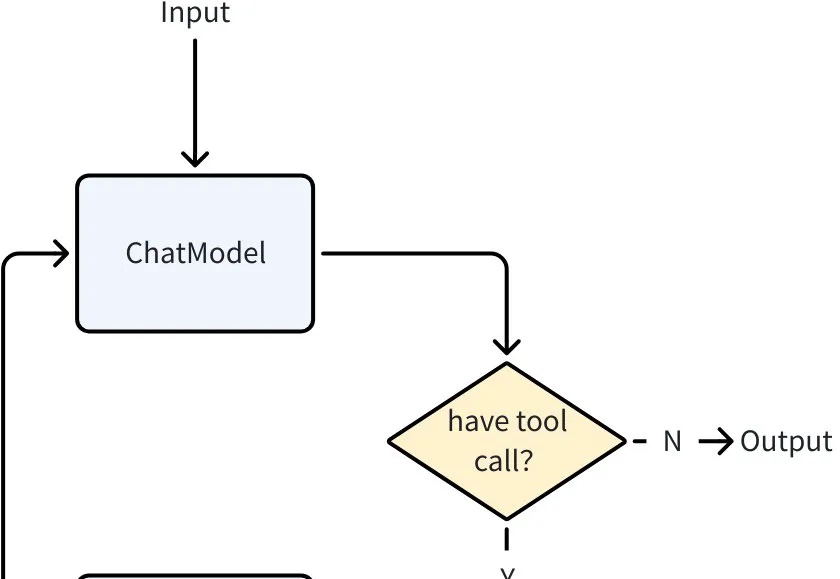
当大语言模型突破了 “理解与生成” 的瓶颈,Agent 迅速成为 AI 落地的主流形态。从智能客服到自动化办公,几乎所有场景都需要 Agent 来承接 LLM 能力、执行具体任务。