人大、清华DeepAnalyze,让LLM化身数据科学家
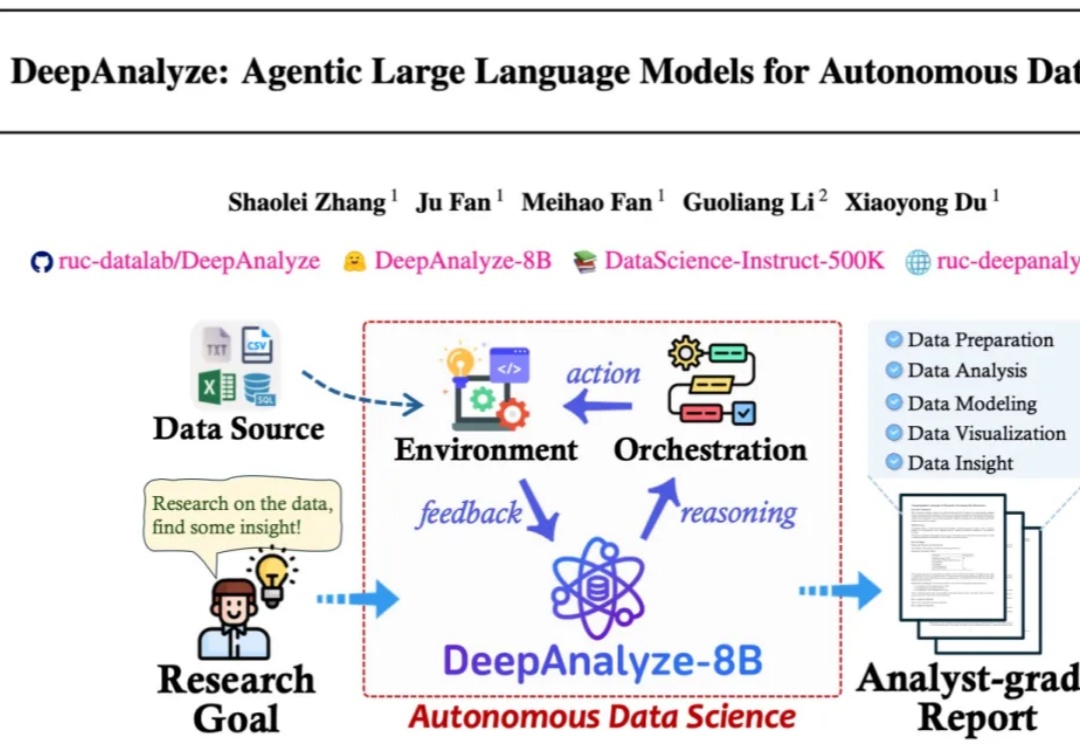
人大、清华DeepAnalyze,让LLM化身数据科学家来自人大和清华的研究团队发布了 DeepAnalyze,首个面向自主数据科学的 agentic LLM。DeepAnalyze引起了社区内广泛讨论,一周内收获1000多个GitHub星标、20w余次社交媒体浏览量。
来自主题: AI技术研报
11853 点击 2025-10-31 09:52
 搜索
搜索
来自人大和清华的研究团队发布了 DeepAnalyze,首个面向自主数据科学的 agentic LLM。DeepAnalyze引起了社区内广泛讨论,一周内收获1000多个GitHub星标、20w余次社交媒体浏览量。
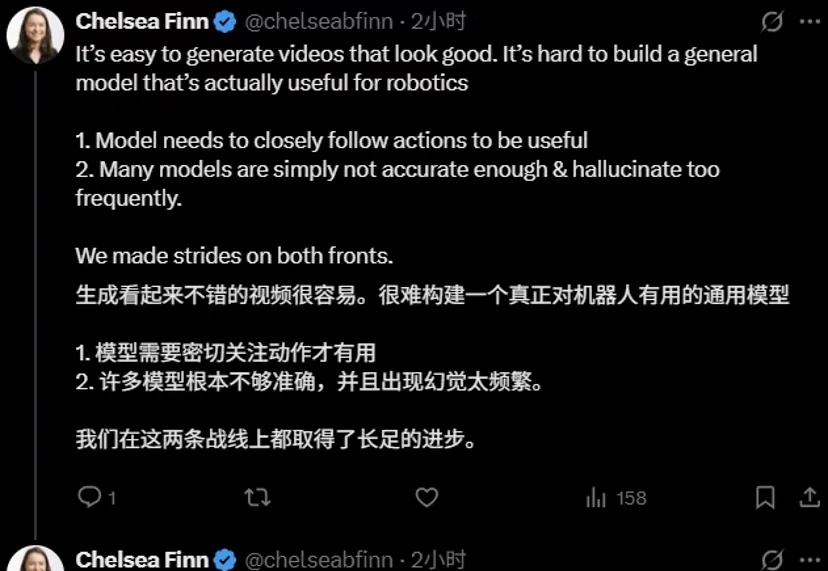
这两天,Physical Intelligence(PI)联合创始人Chelsea Finn在𝕏上,对斯坦福课题组一项最新世界模型工作kuakua连续点赞。
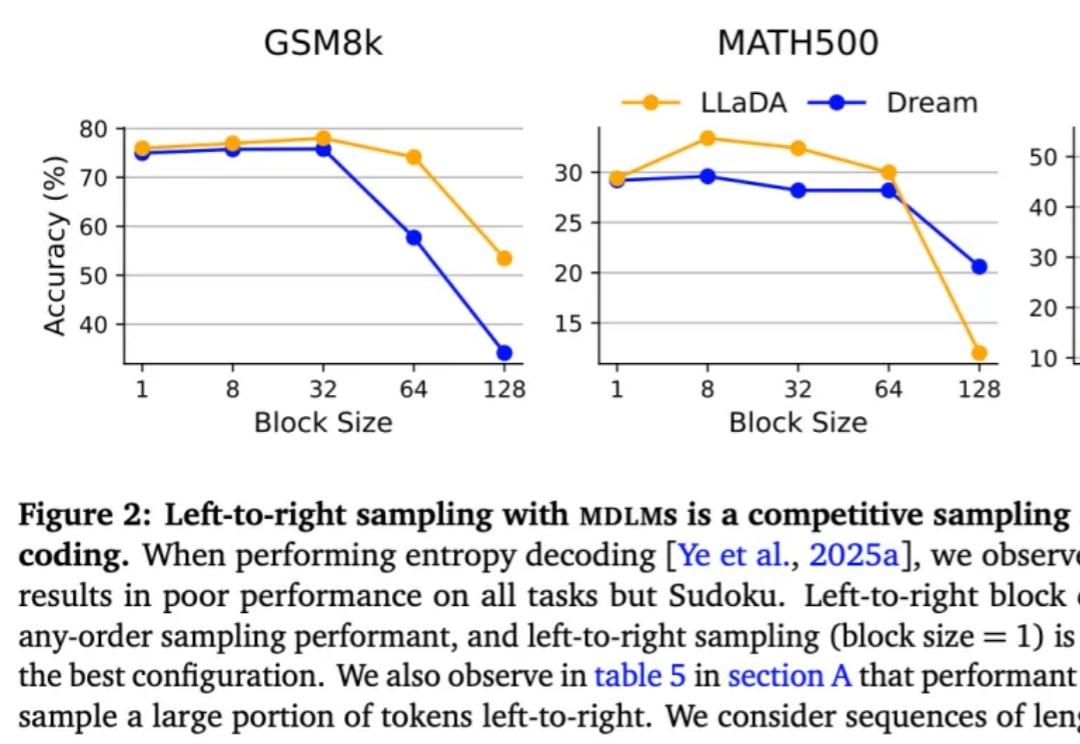
按从左到右的顺序依次生成下一个 token 真的是大模型生成方式的最优解吗?最近,越来越多的研究者对此提出质疑。其中,有些研究者已经转向一个新的方向 —— 掩码扩散语言模型(MDLM)。

家人们,不知道你有没有试过,在和 AI 聊天时,冷不丁地问一句: “你刚刚在想什么?”

用 iPhone 本地跑大模型已经不是新鲜事了,但能不能在 iPhone 上微调模型呢?

近年来,基于扩散模型的图像生成技术发展迅猛,催生了Stable Diffusion、Midjourney等一系列强大的文生图应用。然而,当前主流的训练范式普遍依赖一个核心组件——变分自编码器(VAE),这也带来了长久以来困扰研究者们的几个问题:
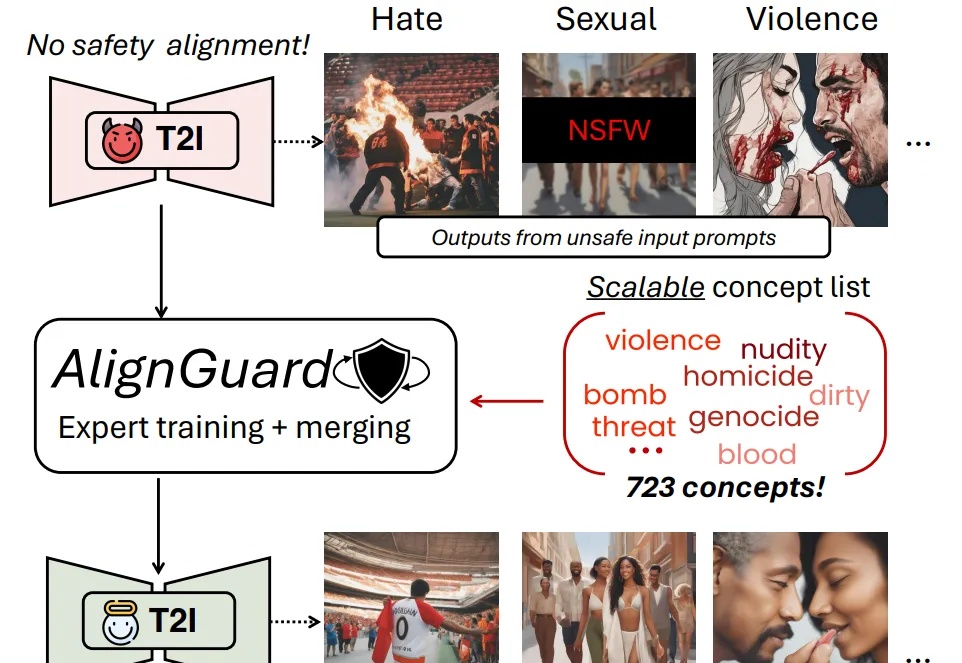
随着文图生成模型的广泛应用,模型本身有限的安全防护机制使得用户有机会无意或故意生成有害的图片内容,并且该内容有可能会被恶意使用。现有的安全措施主要依赖文本过滤或概念移除的策略,只能从文图生成模型的生成能力中移除少数几个概念。
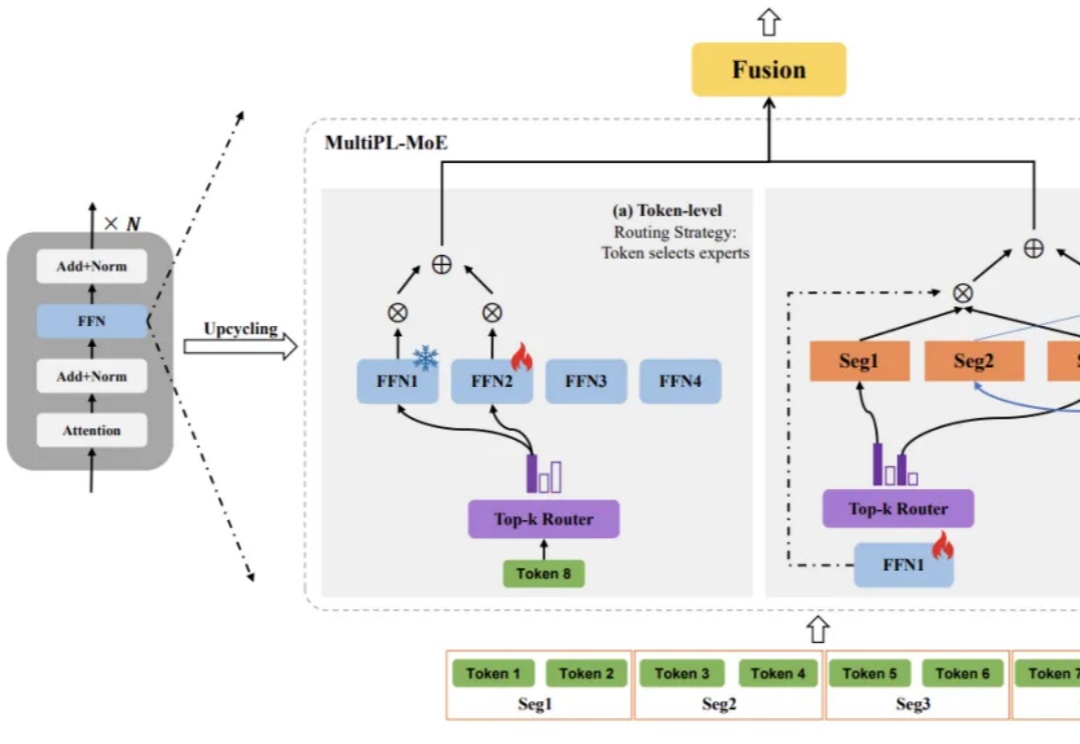
大语言模型(LLM)虽已展现出卓越的代码生成潜力,却依然面临着一道艰巨的挑战:如何在有限的计算资源约束下,同步提升对多种编程语言的理解与生成能力,同时不损害其在主流语言上的性能?

杨红霞要走一条和阿里、字节截然不同的模型训练之路。

读者,您好!今天想跟您聊一个硬核又极具启发性的项目——HGM(Huxley-Gödel Machine)。我刚刚一起花了几个小时,从环境配置的坑,一路“打怪升级”到让它最终跑完,相信您可能已经从别的公众号上看到了这篇文章。