告别「解码器饥饿」!中国科学院NeurIPS推SpaceServe,高并发克星
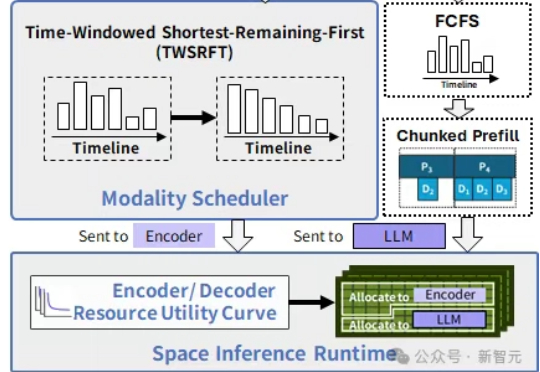
告别「解码器饥饿」!中国科学院NeurIPS推SpaceServe,高并发克星在中国科学院计算技术研究所入选NeurIPS 2025的新论文中,提出了SpaceServe的突破性架构,首次将LLM推理中的P/D分离扩展至多模态场景,通过EPD三阶解耦与「空分复用」,系统性地解决了MLLM推理中的行头阻塞难题。
来自主题: AI技术研报
9060 点击 2025-10-13 16:08
 搜索
搜索
在中国科学院计算技术研究所入选NeurIPS 2025的新论文中,提出了SpaceServe的突破性架构,首次将LLM推理中的P/D分离扩展至多模态场景,通过EPD三阶解耦与「空分复用」,系统性地解决了MLLM推理中的行头阻塞难题。
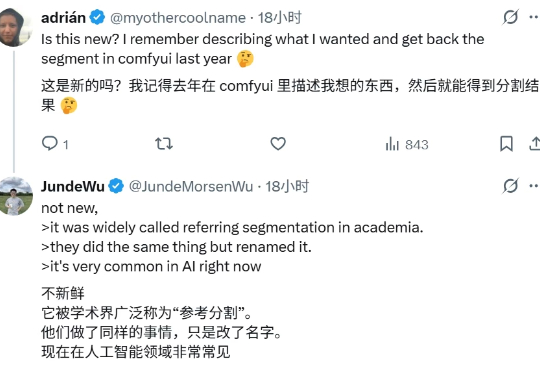
说出概念,SAM 3 就明白你在说什么,并在所有出现的位置精确描绘出边界。 Meta 的「分割一切」再上新? 9 月 12 日,一篇匿名论文「SAM 3: SEGMENT ANYTHING WITH CONCEPTS」登陆 ICLR 2026,引发网友广泛关注。

扩散模型本该只是复制机器,却一次次画出「六指人像」甚至是陌生场景。最新研究发现,AI的「创造力」其实是架构里的副作用。有学者大胆推测人类的灵感或许也是如此。当灵感成了固定公式,人类和AI的差别还有多少?
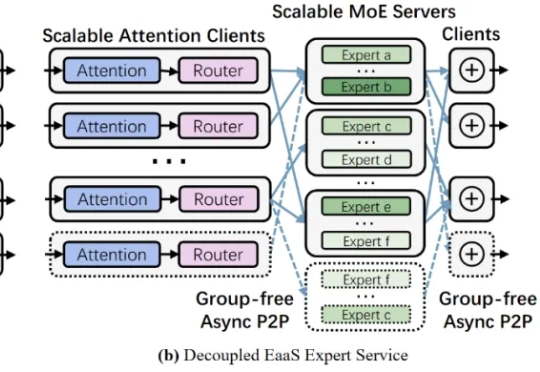
近年来,大型语言模型的参数规模屡创新高,随之而来的推理开销也呈指数级增长。如何降低超大模型的推理成本,成为业界关注的焦点之一。Mixture-of-Experts (MoE,混合专家) 架构通过引入大量 “专家” 子模型,让每个输入仅激活少数专家,从而在参数规模激增的同时避免推理计算量同比增长。
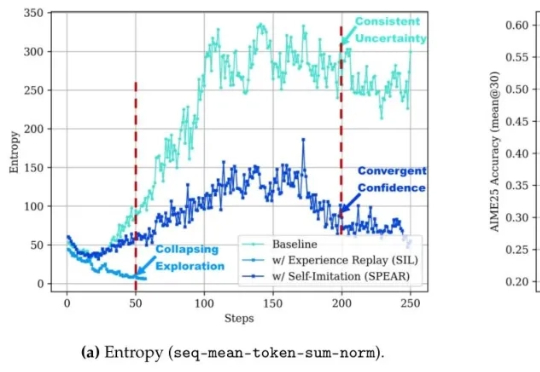
让智能体自己摸索新方法,还模仿自己的成功经验。腾讯优图实验室开源强化学习算法——SPEAR(Self-imitation with Progressive Exploration for Agentic Reinforcement Learning)。
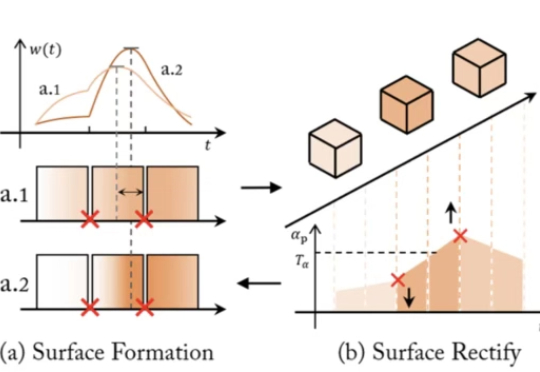
近年来,NeRF、SDF 与 3D Gaussian Splatting 等方法大放异彩,让 AI 能从图像中恢复出三维世界。但随着相关技术路线的发展与完善,瓶颈问题也随之浮现:
AI自己讲明白论文,还能生成更美观的幻灯片。加州大学圣塔芭芭拉(UCSB)与圣克鲁兹(UCSC)的研究者提出EvoPresent,一个能够自我进化的学术演讲智能体框架,让AI不仅能“讲清楚论文”,还能“讲得好看”。

InfLLM-V2是一种可高效处理长文本的稀疏注意力模型,仅需少量长文本数据即可训练,且性能接近传统稠密模型。通过动态切换短长文本处理模式,显著提升长上下文任务的效率与质量。从短到长低成本「无缝切换」,预填充与解码双阶段加速,释放长上下文的真正生产力。

3D 生成正从纯虚拟走向物理真实,现有的 3D 生成方法主要侧重于几何结构与纹理信息,而忽略了基于物理属性的建模。
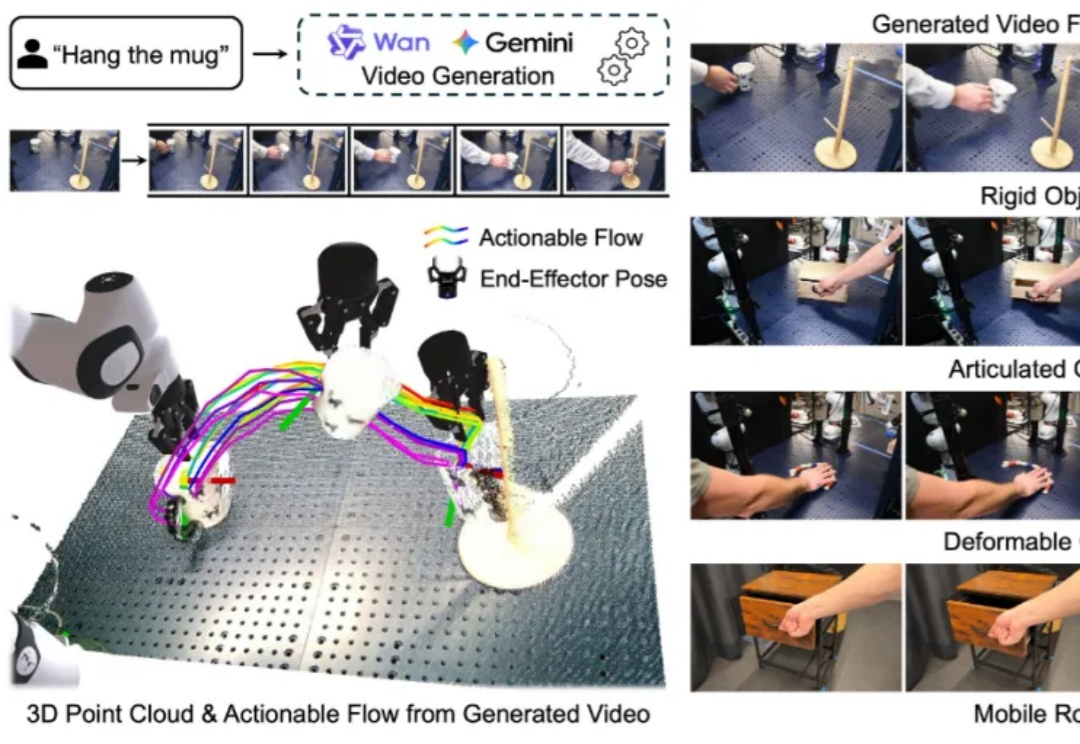
构建能够在新环境中、无需任何针对性训练就能执行多样化任务的通用机器人,是机器人学领域一个长期追逐的圣杯。近年来,随着大型语言模型(LLMs)和视觉语言模型(VLMs)的飞速发展,许多研究者将希望寄托于视觉 - 语言 - 动作(VLA)模型,期望它们能复刻 LLM 和 VLM 在泛化性上取得的辉煌。