只需1/4预算,性能反超基线:阿里高德提出Tree-GRPO,高效破解智能体RL难题
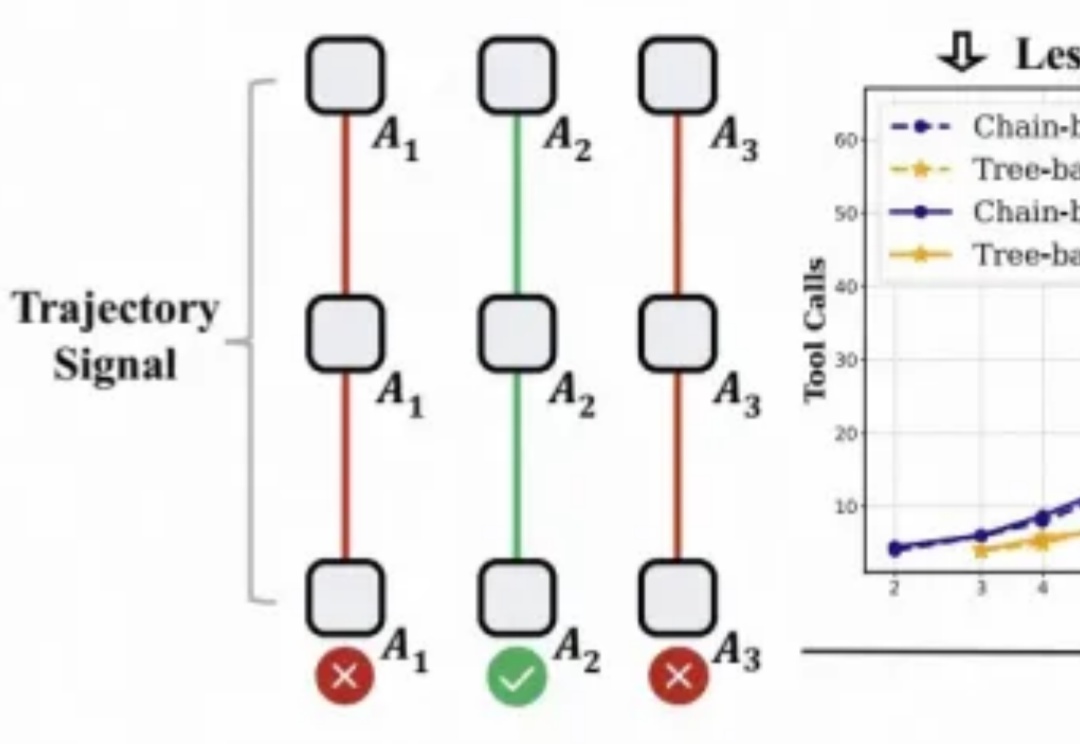
只需1/4预算,性能反超基线:阿里高德提出Tree-GRPO,高效破解智能体RL难题对于大模型的强化学习已在数学推理、代码生成等静态任务中展现出不俗实力,而在需要与开放世界交互的智能体任务中,仍面临「两朵乌云」:高昂的 Rollout 预算(成千上万的 Token 与高成本的工具调用)和极其稀疏的「只看结果」的奖励信号。
来自主题: AI技术研报
9015 点击 2025-10-15 12:07
 搜索
搜索
对于大模型的强化学习已在数学推理、代码生成等静态任务中展现出不俗实力,而在需要与开放世界交互的智能体任务中,仍面临「两朵乌云」:高昂的 Rollout 预算(成千上万的 Token 与高成本的工具调用)和极其稀疏的「只看结果」的奖励信号。

写给正在落地 AI 产品的工程师。一些代码直接可改造复用;另一些,是我踩坑后的经验之谈。
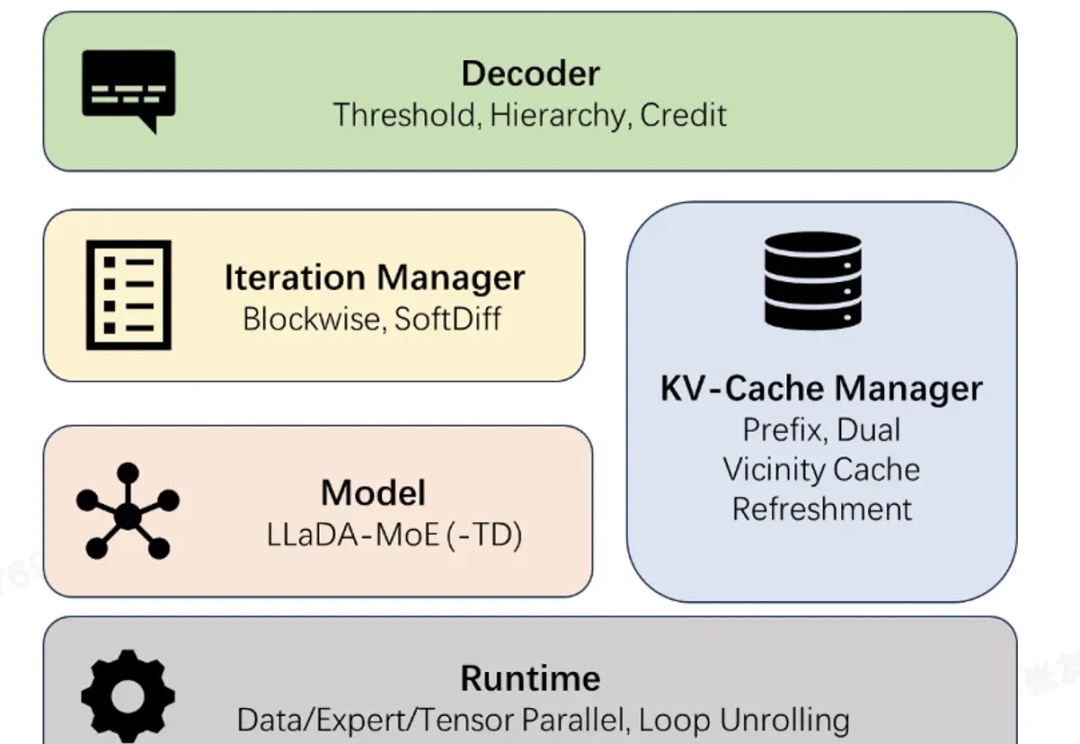
近日,蚂蚁集团正式开源业界首个高性能扩散语言模型(Diffusion Large Language Model,dLLM)推理框架 dInfer。
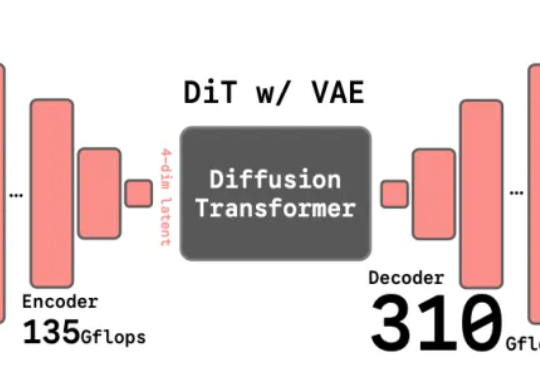
谢赛宁团队最新研究给出了答案——VAE的时代结束,RAE将接力前行。其中表征自编码器RAE(Representation Autoencoders)是一种用于扩散Transformer(DiT)训练的新型自动编码器,其核心设计是用预训练的表征编码器(如DINO、SigLIP、MAE 等)与训练后的轻量级解码器配对,从而替代传统扩散模型中依赖的VAE(变分自动编码器)。

AI传奇人物、前特斯拉AI总监Karpathy重磅推出全新开源项目「nanochat」,以不到8000行代码复现ChatGPT全流程,只需一台GPU、约4小时、成本仅百美元。该项目在GitHub上线不到12小时即获4.2k星标!
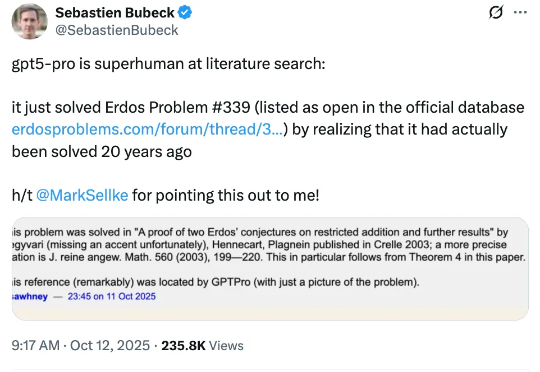
人类遗忘的难题解法,被GPT-5 Pro重新找出来了!这事儿聚焦于埃尔德什问题#339,这是著名数学家保罗・埃尔德什提出或转述的近千道问题之一,收录于erdosproblems.com网站。该网站记录了每道题目的当前状态,其中约三分之一已解决,大部分仍待解。

为什么大模型,在执行长时任务时容易翻车?这让一些专家,开始质疑大模型的推理能力,认为它们是否只是提供了「思考的幻觉」。近日,剑桥大学等机构的一项研究证明:问题不是出现在推理上,而是出在大模型的执行能力上。
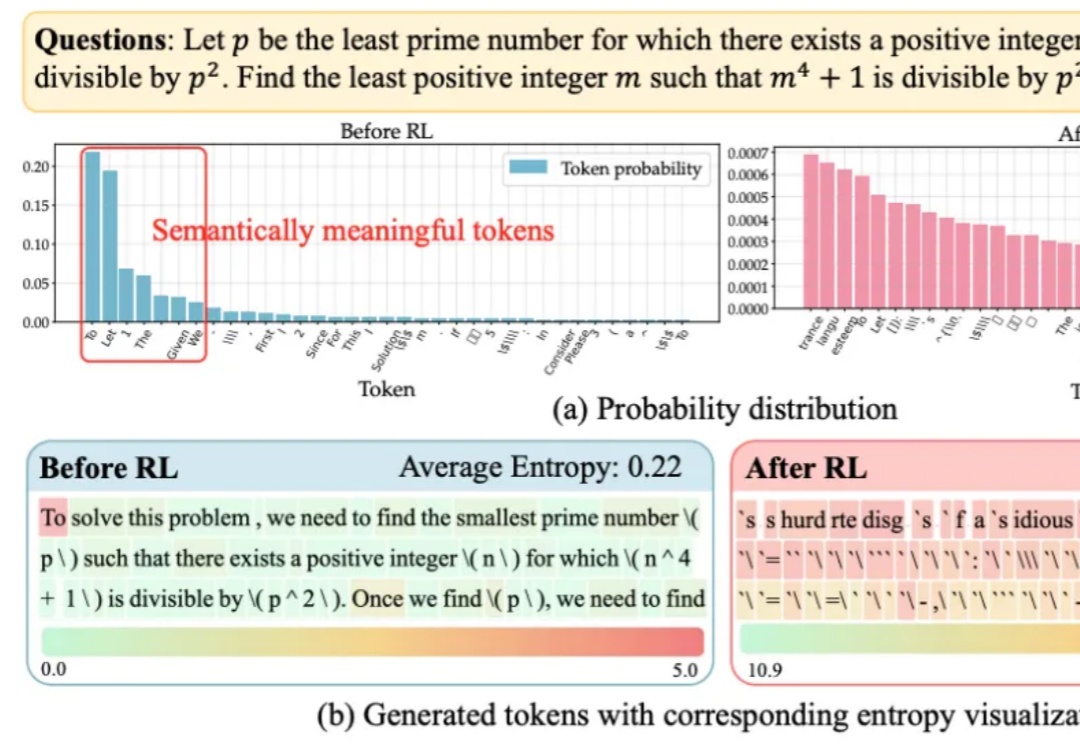
大语言模型在RLVR训练中面临的“熵困境”,有解了!

当全球的目光还在聚焦基座模型的参数竞赛时,一场更为深刻的变革正在悄然发生——后训练(Post-Training)。
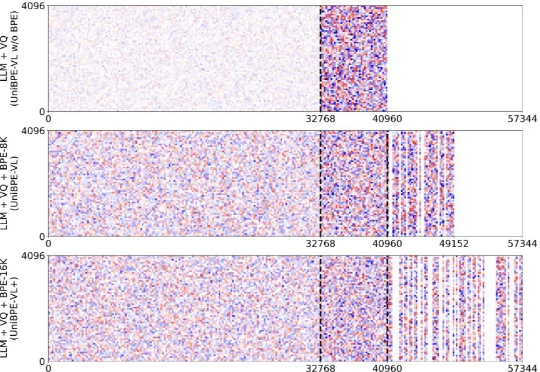
为此,北大、UC San Diego 和 BeingBeyond 联合提出一种新的方法——Being-VL 的视觉 BPE 路线。Being-VL 的出发点是把这一步后置:先在纯自监督、无 language condition 的设定下,把图像离散化并「分词」,再与文本在同一词表、同一序列中由同一 Transformer 统一建模,从源头缩短跨模态链路并保留视觉结构先验。