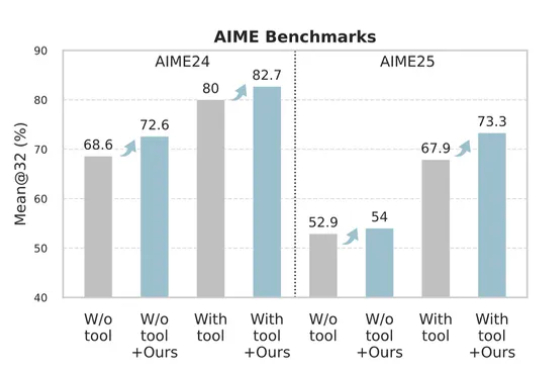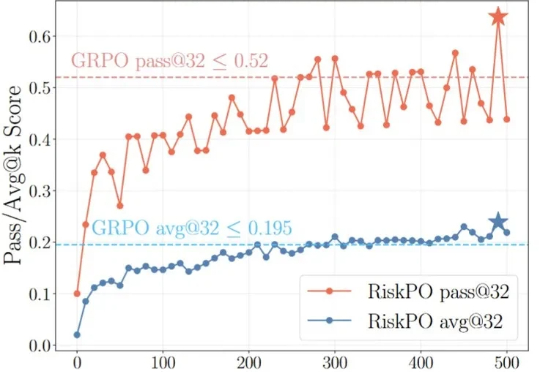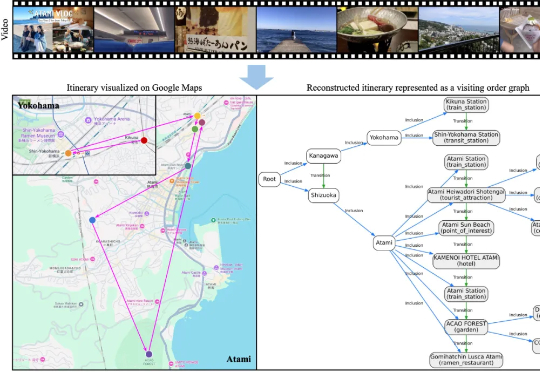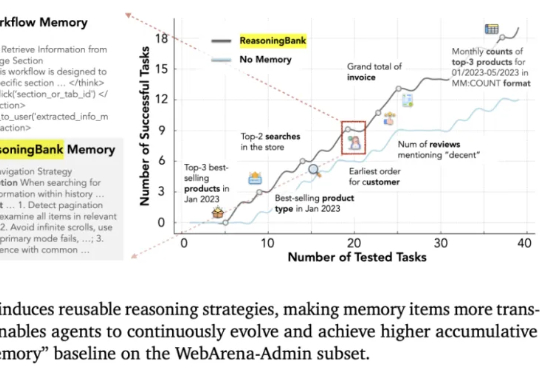
NeurIPS 25 | 中大&UC Merced等开源RAPID Hand,重新定义多指灵巧手数据采集
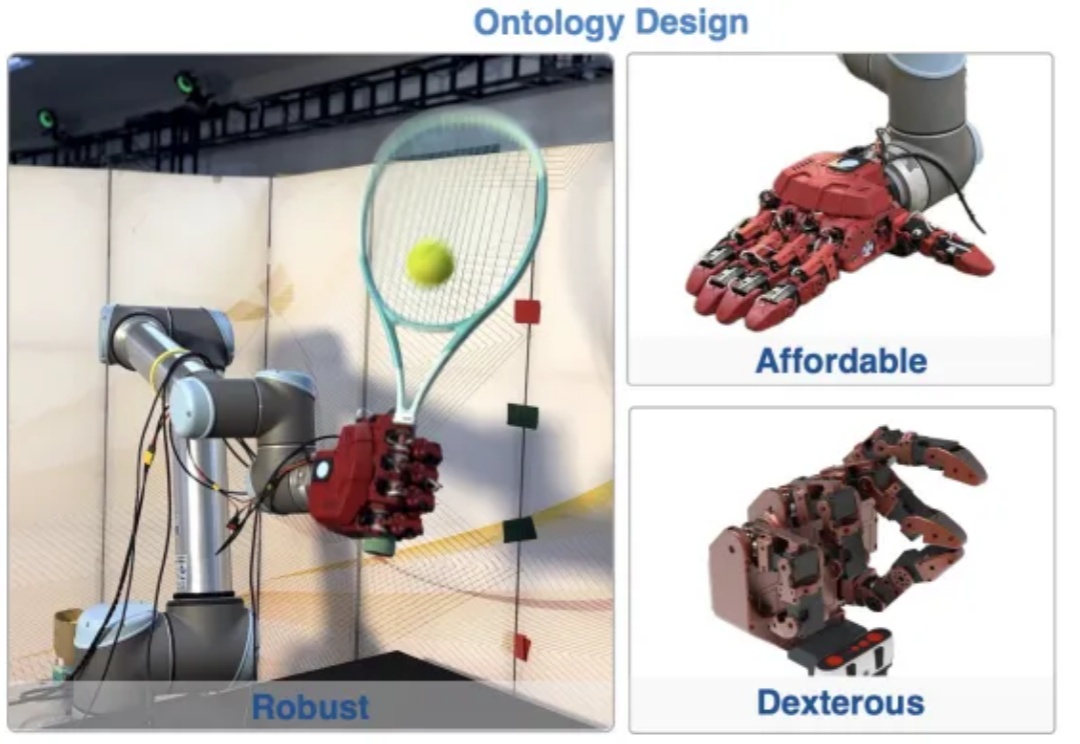
NeurIPS 25 | 中大&UC Merced等开源RAPID Hand,重新定义多指灵巧手数据采集在最近的一篇 NeurIPS 25 中稿论文中,来自中山大学、加州大学 Merced 分校、中科院自动化研究所、诚橙动力的研究者联合提出了一个全新开源的高自由度灵巧手平台 — RAPID Hand (Robust, Affordable, Perception-Integrated, Dexterous Hand)。
来自主题: AI技术研报
10049 点击 2025-10-16 10:52