
强化学习之父给LLM判死刑!站队LeCun:我们全搞错了
强化学习之父给LLM判死刑!站队LeCun:我们全搞错了当全世界都在狂热追逐大模型时,强化学习之父、图灵奖得主Richard Sutton却直言:大语言模型是「死胡同」。在他看来,真正的智能必须源于经验学习,而不是模仿人类语言的「预测游戏」。这番话无异于当头一棒,让人重新思考:我们追逐的所谓智能,究竟是幻影,还是通向未来的歧路?
来自主题: AI资讯
9347 点击 2025-09-30 15:40
 搜索
搜索
当全世界都在狂热追逐大模型时,强化学习之父、图灵奖得主Richard Sutton却直言:大语言模型是「死胡同」。在他看来,真正的智能必须源于经验学习,而不是模仿人类语言的「预测游戏」。这番话无异于当头一棒,让人重新思考:我们追逐的所谓智能,究竟是幻影,还是通向未来的歧路?
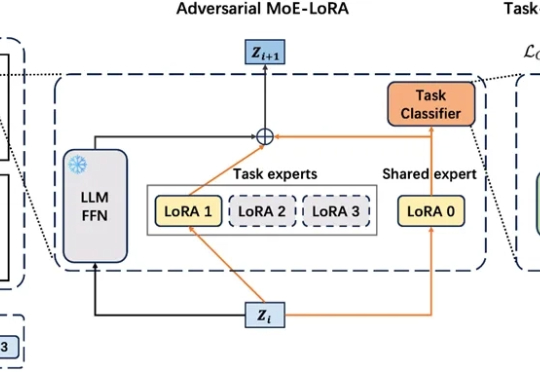
在工业级大语言模型(LLM)应用中,动态适配任务与保留既有能力的 “自进化” 需求日益迫切。真实场景中,不同领域语言模式差异显著,LLM 需在学习新场景合规规则的同时,不丢失旧场景的判断能力。这正是大模型自进化核心诉求,即 “自主优化跨任务知识整合,适应动态环境而无需大量外部干预”。

为破解机器人产业「一机一调」的开发困境,智源研究院开源了通用「小脑基座」RoboBrain-X0。它创新地学习任务「做什么」而非「怎么动」,让一个预训练模型无需微调,即可驱动多种不同构造的真实机器人,真正实现了零样本跨本体泛化。

全新一代 video-SALMONN 2/2+、首个开源推理增强型音视频理解大模型 video-SALMONN-o1(ICML 2025)、首个高帧率视频理解大模型 F-16(ICML 2025),以及无文本泄漏基准测试 AVUT(EMNLP 2025) 正式发布。新阵容在视频理解能力与评测体系全线突破,全面巩固 SALMONN 家族在开源音视频理解大模型赛道的领先地位。

DeepSeek v3.2有一个新改动,在论文里完全没提,只在官方公告中出现一次,却引起墙裂关注。开源TileLang版本算子,其受关注程度甚至超过新稀疏注意力机制DSA,从画线转发的数量就可以看出来。

原文作者:David Adam 本篇《自然》长文共3702字,干货满满,预计阅读时间12分钟,时间不够建议可以先“浮窗”或者收藏哦。 研究表明,电子伙伴类应用有利有弊——但科学家们担心长期依赖性。 绘

DeepMind公开了有关Veo 3视频模型最新论文!论文提出了「帧链」(Chain-of-Frames,CoF),认为视频模型也可能像通用大模型一样具备推理能力。零样本能力的涌现,表明视频模型的「GPT-3时刻」来了。
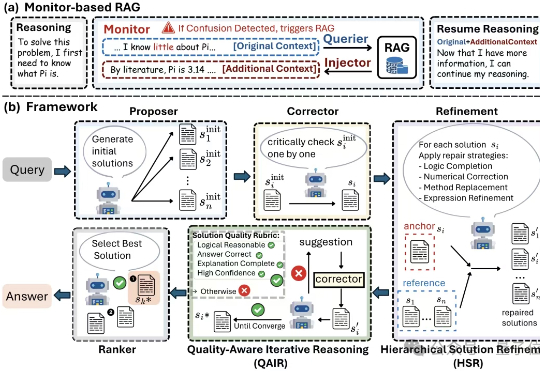
就在最近,由耶鲁大学唐相儒、王昱婕,上海交通大学徐望瀚,UCLA万冠呈,牛津大学尹榛菲,Eigen AI金帝、王瀚锐等团队联合开发的Eigen-1多智能体系统实现了历史性突破

人们感到AI理解自己,因为AI提供优于人类的倾听和理性建议,如认知共情总结混乱想法或询问需求。形象如语音和触觉增强情感连接,但过度依赖AI可能加剧孤独感。心理学角度区分情绪与认知共情,未来需身体互动和共同成长建立真实关系。
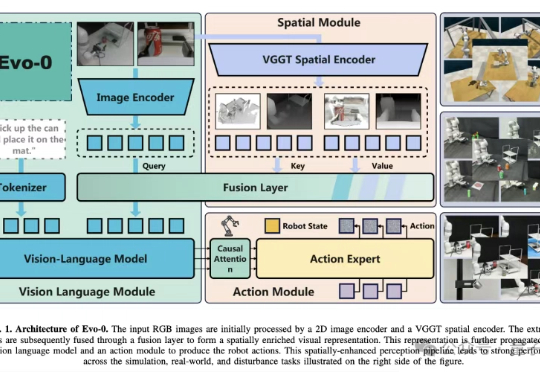
VLA模型通常建立在预训练视觉语言模型(VLM)之上,仅基于2D图像-文本数据训练,缺乏真实世界操作所需的3D空间理解能力。