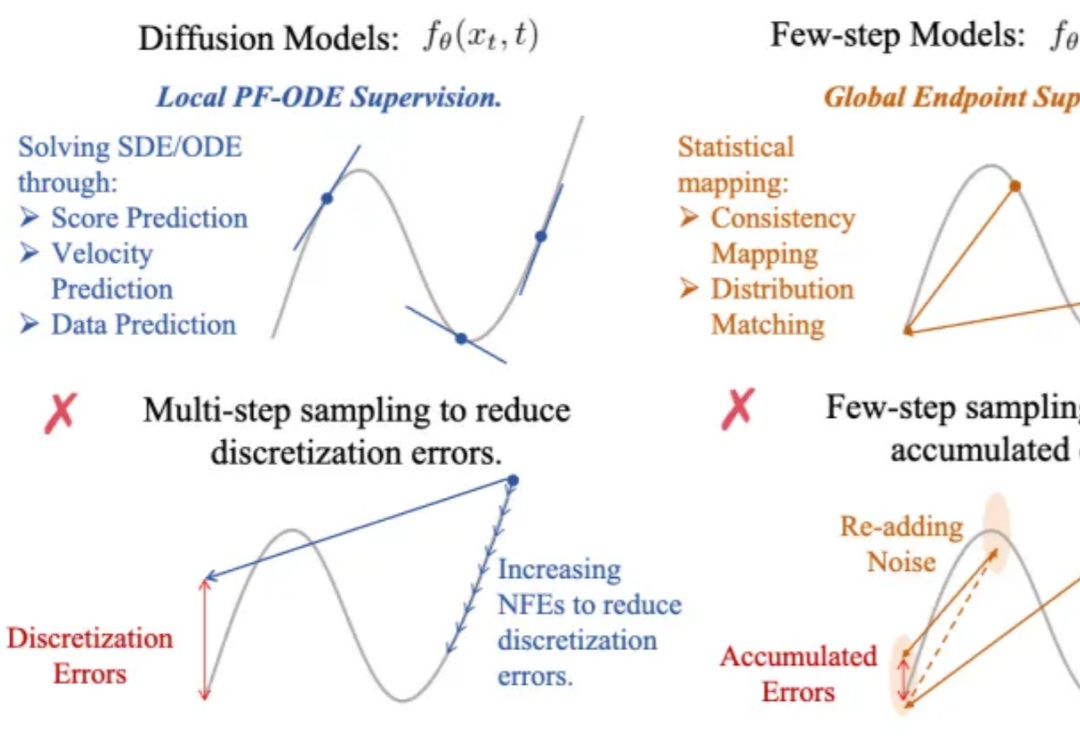
兼得快与好!训练新范式TiM,原生支持FSDP+Flash Attention
兼得快与好!训练新范式TiM,原生支持FSDP+Flash Attention生成式AI的快与好,终于能兼得了?
来自主题: AI技术研报
9361 点击 2025-09-16 10:43
 搜索
搜索
生成式AI的快与好,终于能兼得了?

随着Agent的爆发,大型语言模型(LLM)的应用不再局限于生成日常对话,而是越来越多地被要求输出像JSON或XML这样的结构化数据。这种结构化输出对于确保安全性、与其他软件系统互操作以及执行下游自动化任务至关重要。
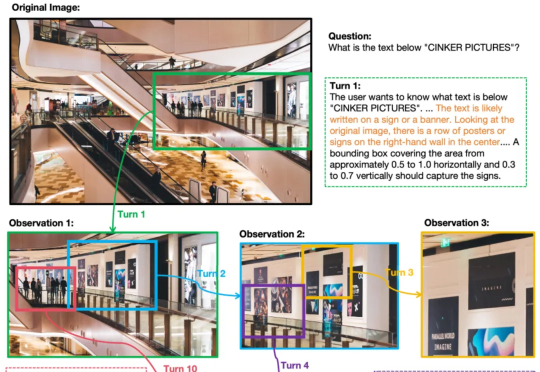
OpenAI o3的多轮视觉推理,有开源平替版了。并且,与先前局限于1-2轮对话的视觉语言模型(VLM)不同,它在训练限制轮数只有6轮的情况下,测试阶段能将思考轮数扩展到数十轮。

自动化修复真实世界的软件缺陷问题是自动化程序修复研究社区的长期目标。然而,如何自动化解决视觉软件缺陷仍然是一个尚未充分探索的领域。最近,随着 SWE-bench 团队发布最新的多模态 Issue 修复
最近,来自加州大学圣克鲁兹分校、乔治·梅森大学和Datadog的研究人员发现:在心算任务中,几乎所有实际的数学计算都集中在序列的最后一个token上完成,而不是分散在所有token中。
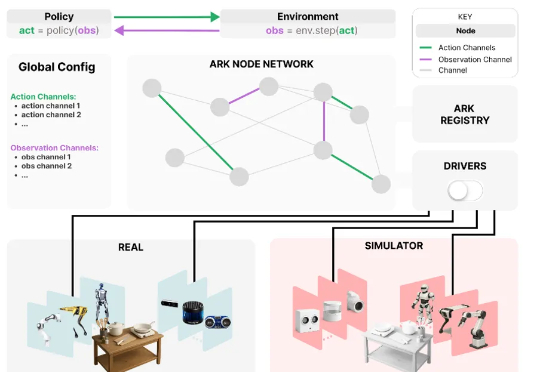
为应对这些挑战,来自华为诺亚方舟实验室,德国达姆施塔特工业大学,英国伦敦大学学院,帝国理工学院和牛津大学的研究者们联合推出了 Ark —— 一个基于 Python 的机器人开发框架,支持快速原型构建,并可便捷地在仿真和真实机器人系统上部署新算法。
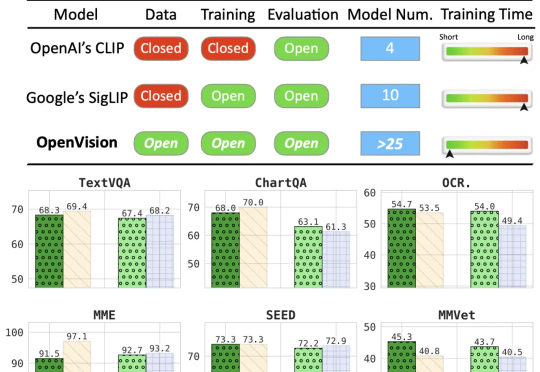
本文来自加州大学圣克鲁兹分校(UCSC)、苹果公司(Apple)与加州大学伯克利分校(UCB)的合作研究。第一作者刘彦青,本科毕业于浙江大学,现为UCSC博士生,研究方向包括多模态理解、视觉-语言预训
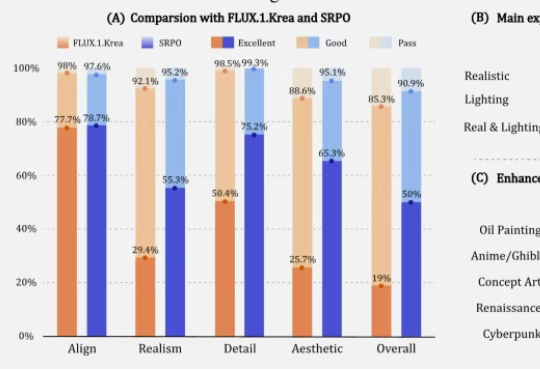
让AI生成的图像更符合人类精细偏好,在32块H20上训练10分钟就能收敛。腾讯混元新方法让微调的FLUX1.dev模型人工评估的真实感和美学评分提高3倍以上。

见过省电的模型,但这么省电的,还是第一次见。 在 《自然》 杂志发表的一篇论文中,加州大学洛杉矶分校 Shiqi Chen 等人描述了一种几乎不消耗电量的 AI 图像生成器的开发。

北京深度逻辑智能科技有限公司推出了 LLaSO—— 首个完全开放、端到端的语音语言模型研究框架。LLaSO 旨在为整个社区提供一个统一、透明且可复现的基础设施,其贡献是 “全家桶” 式的,包含了一整套开源的数据、基准和模型,希望以此加速 LSLM 领域的社区驱动式创新。