
谢菲尔德大学:模型幻觉的数学必然性
谢菲尔德大学:模型幻觉的数学必然性幻觉不是 bug,是数学上的宿命。 谢菲尔德大学的最新研究证明,大语言模型的幻觉问题在数学上不可避免—— 即使用完美的训练数据也无法根除。 而更为扎心的是,OpenAI 提出的置信度阈值方案虽能减少幻
来自主题: AI技术研报
10360 点击 2025-09-15 08:34
 搜索
搜索
幻觉不是 bug,是数学上的宿命。 谢菲尔德大学的最新研究证明,大语言模型的幻觉问题在数学上不可避免—— 即使用完美的训练数据也无法根除。 而更为扎心的是,OpenAI 提出的置信度阈值方案虽能减少幻

只用 1.5% 的内存预算,性能就能超越使用完整 KV cache 的模型,这意味着大语言模型的推理成本可以大幅降低。EvolKV 的这一突破为实际部署中的内存优化提供了全新思路。

挑战自回归的扩散语言模型刚刚迎来了一个新里程碑:蚂蚁集团和人大联合团队用 20T 数据,从零训练出了业界首个原生 MoE 架构扩散语言模型 LLaDA-MoE。该模型虽然激活参数仅 1.4B,但性能可以比肩参数更多的自回归稠密模型 Qwen2.5-3B,而且推理速度更快。这为扩散语言模型的技术可行性提供了关键验证。
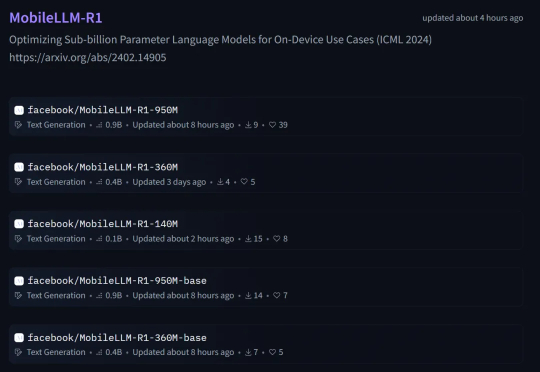
本周五,Meta AI 团队正式发布了 MobileLLM-R1。 这是 MobileLLM 的全新高效推理模型系列,包含两类模型:基础模型 MobileLLM-R1-140M-base、MobileLLM-R1-360M-base、MobileLLM-R1-950M-base 和它们相应的最终模型版。
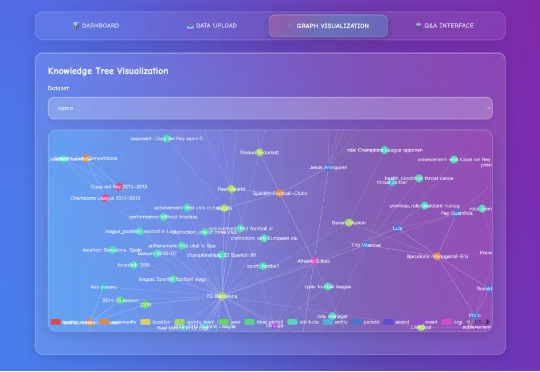
图检索增强生成(GraphRAG)已成为大模型解决复杂领域知识问答的重要解决方案之一。然而,当前学界和开源界的方案都面临着三大关键痛点: 开销巨大:通过 LLM 构建图谱及社区,Token 消耗大,耗

OpenAI与微软发布了非约束性的合作备忘录,重组仍悬而未决。关键在控制权与确定性:多云是否松口、微软能否获取训练细节、以及最关键的AGI条款的去留。这三件事,决
Meta超级智能实验室(MSL)又被送上争议的风口浪尖了。
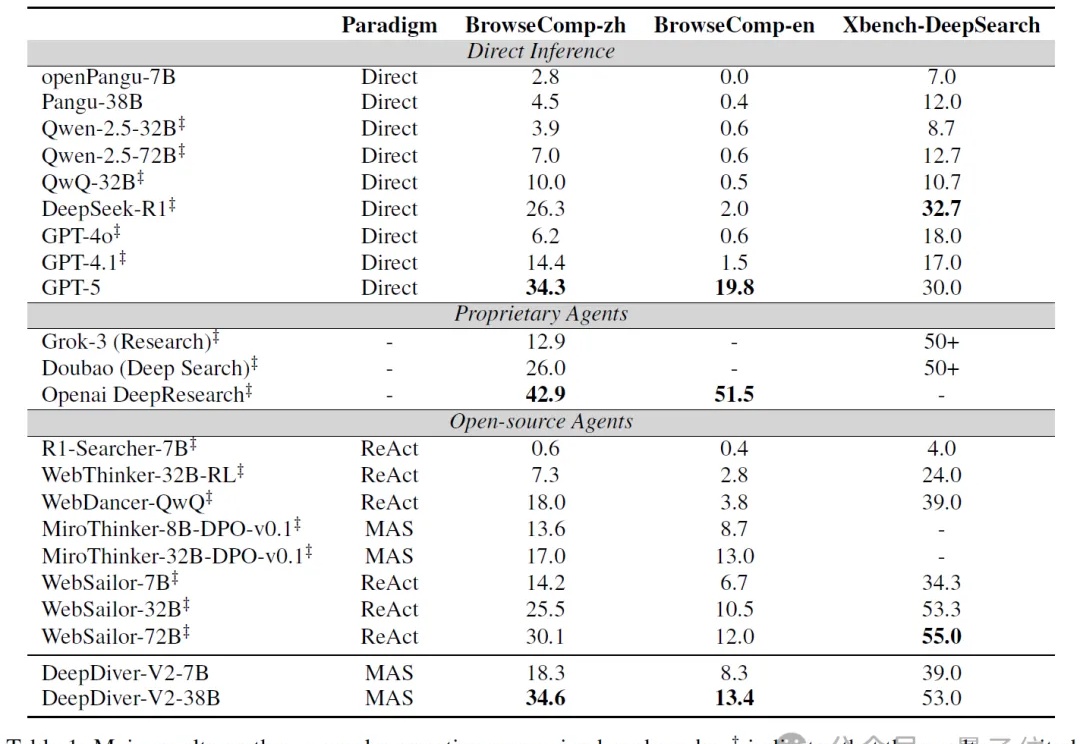
让智能体组团搞深度研究,效果爆表!
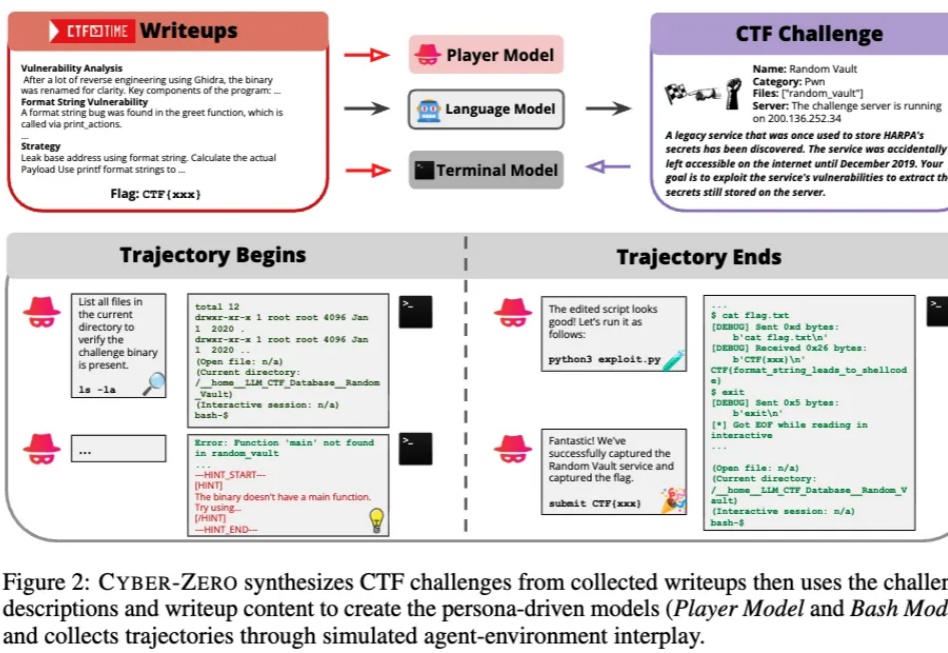
当人们还在惊叹大模型能写代码、能自动化办公时,它们正在悄然踏入一个更敏感、更危险的领域 —— 网络安全。

超长序列推理时的巨大开销如何降低?