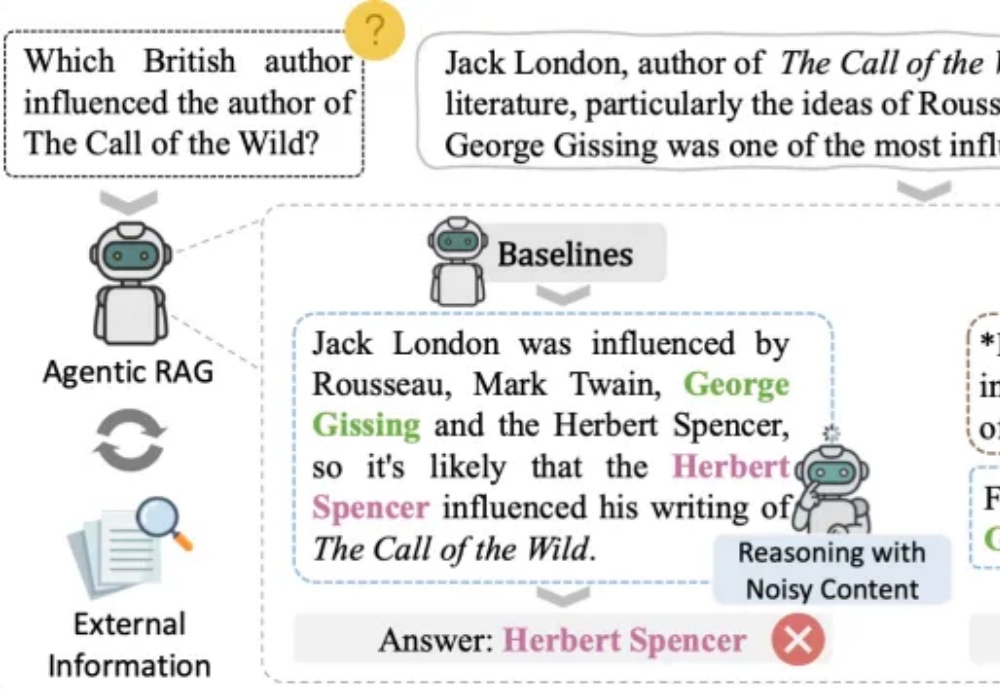
告别错误累计与噪声干扰,EviNote-RAG 开启 RAG 新范式
告别错误累计与噪声干扰,EviNote-RAG 开启 RAG 新范式在检索增强生成(RAG)飞速发展的当下,研究者们面临的最大困境并非「生成」,而是「稳定」。
来自主题: AI技术研报
8961 点击 2025-09-12 11:05
 搜索
搜索
在检索增强生成(RAG)飞速发展的当下,研究者们面临的最大困境并非「生成」,而是「稳定」。
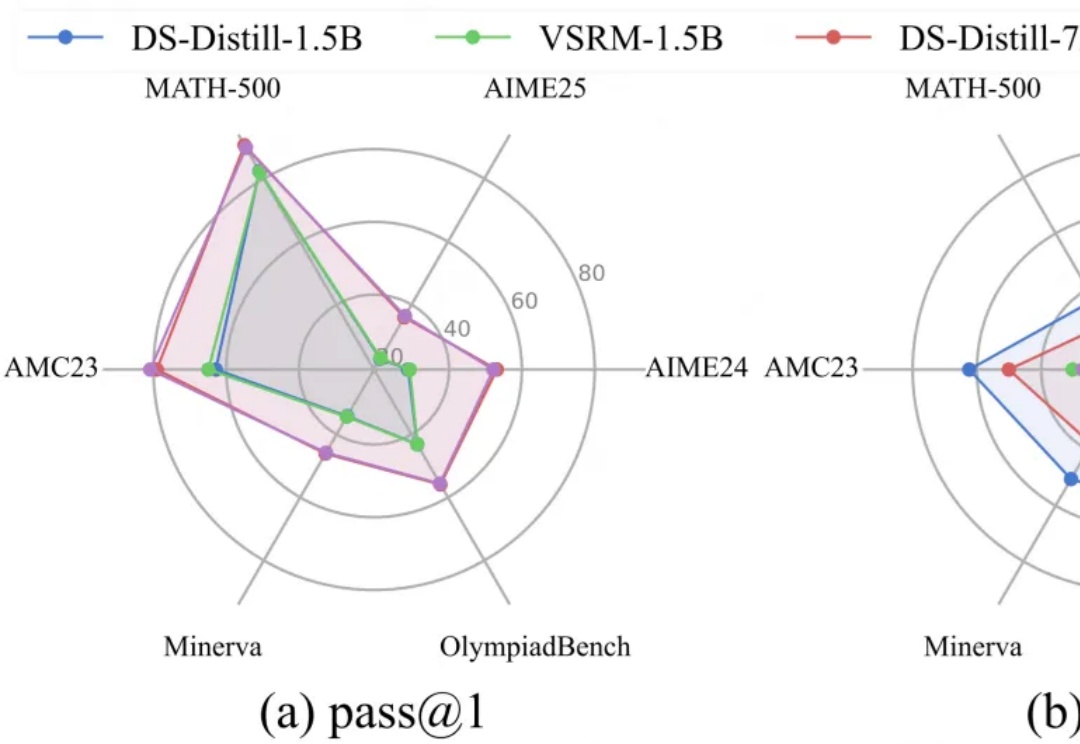
LRM通过简单却有效的RLVR范式,培养了强大的CoT推理能力,但伴随而来的冗长的输出内容,不仅显著增加推理开销,还会影响服务的吞吐量,这种消磨用户耐心的现象被称为“过度思考”问题。
幻觉并非什么神秘现象,而是现代语言模型训练和评估方式下必然的统计结果。它是一种无意的、因不确定而产生的错误。根据OpenAI9月4号论文的证明,模型产生幻觉(Hallucination),是一种系统性缺陷。

唱衰人工智能不会带来更好的明天 —— 构建于人工智能之上的未来世界既非乌托邦,也非反乌托邦,而是充满无限奇幻可能的。
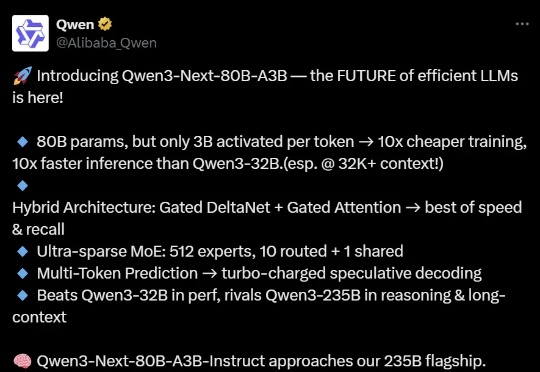
训练、推理性价比创新高。 大语言模型(LLM),正在进入 Next Level。 周五凌晨,阿里通义团队正式发布、开源了下一代基础模型架构 Qwen3-Next。总参数 80B 的模型仅激活 3B ,性能就可媲美千问 3 旗舰版 235B 模型,也超越了 Gemini-2.5-Flash-Thinking,实现了模型计算效率的重大突破。
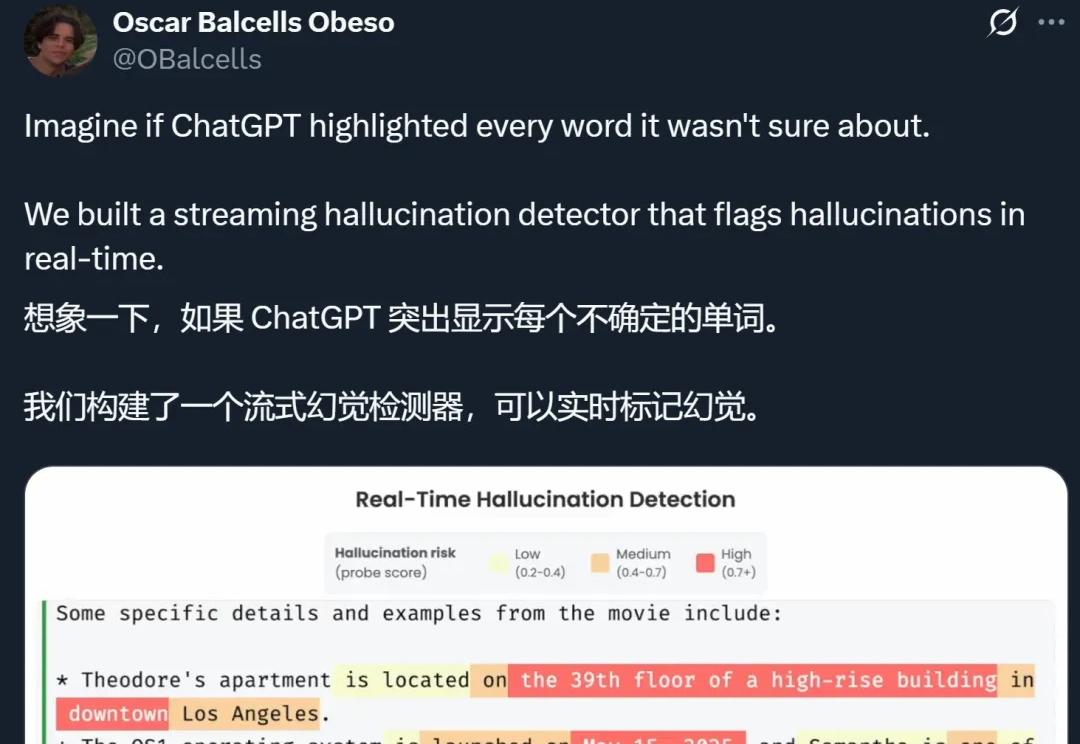
想象一下,如果 ChatGPT 等 AI 大模型在生成的时候,能把自己不确定的地方都标记出来,你会不会对它们生成的答案放心很多?

大语言模型的局限在哪里?
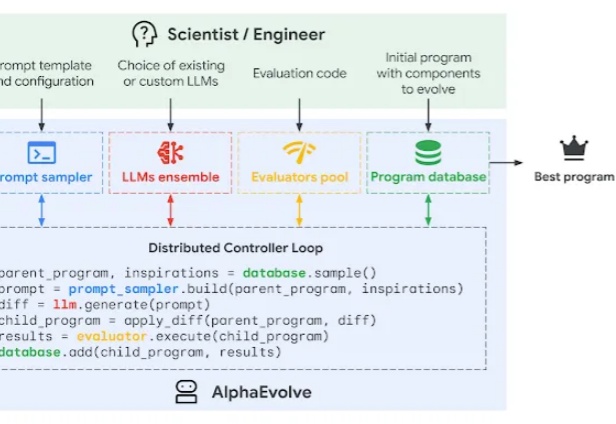
AI 开发复杂软件的时代即将到来?
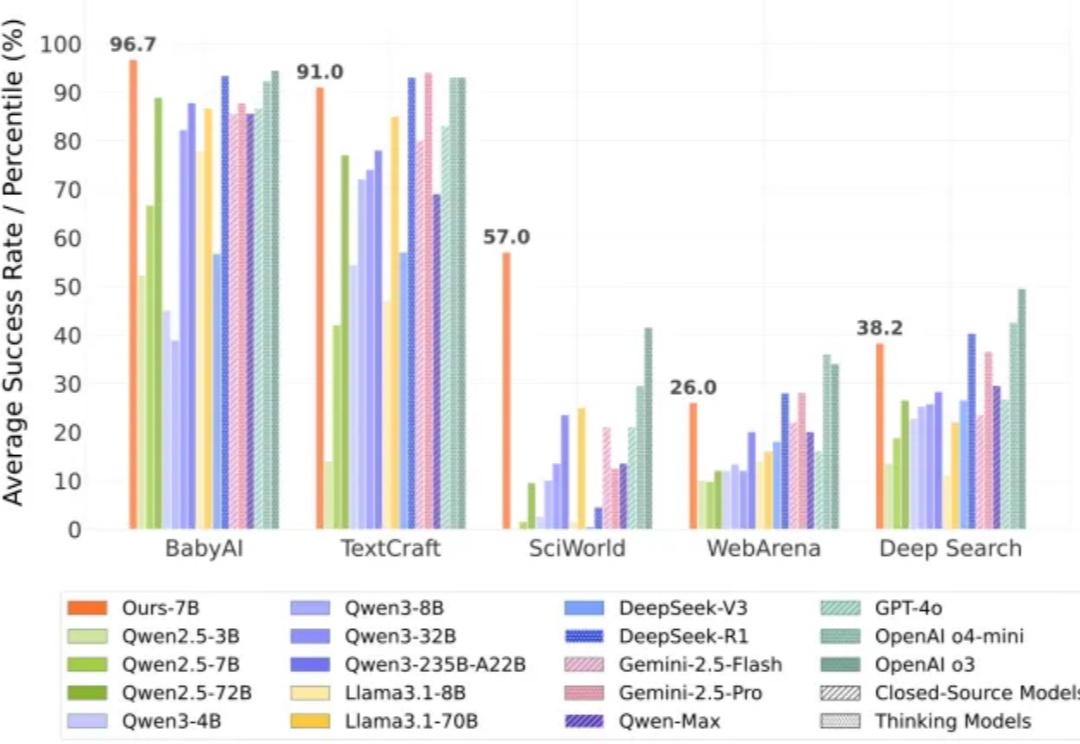
强化学习之父、2024 年 ACM 图灵奖得主 Richard Sutton 曾指出,人工智能正在迈入「经验时代」—— 在这个时代,真正的智能不再仅仅依赖大量标注数据的监督学习,而是来源于在真实环境中主动探索、不断积累经验的能力。

我们今天正式开源 jina-code-embeddings,一套全新的代码向量模型。包含 0.5B 和 1.5B 两种参数规模,并同步推出了 1-4 bit 的 GGUF 量化版本,方便在各类端侧硬件上部署。