
破解遥感目标的形状与尺度难题,PKINet二代推理提速近4倍!
破解遥感目标的形状与尺度难题,PKINet二代推理提速近4倍!卫星和航空影像里的目标,不仅大小相差悬殊,还可能朝向任意方向:一边是细长的桥梁、船舶,一边是密集的小车和大面积运动场。PKINet-v2是一种改进的遥感目标检测模型,能同时处理复杂形状和尺度变化的问题。
来自主题: AI技术研报
6609 点击 2026-07-01 09:50
 搜索
搜索
卫星和航空影像里的目标,不仅大小相差悬殊,还可能朝向任意方向:一边是细长的桥梁、船舶,一边是密集的小车和大面积运动场。PKINet-v2是一种改进的遥感目标检测模型,能同时处理复杂形状和尺度变化的问题。

如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?
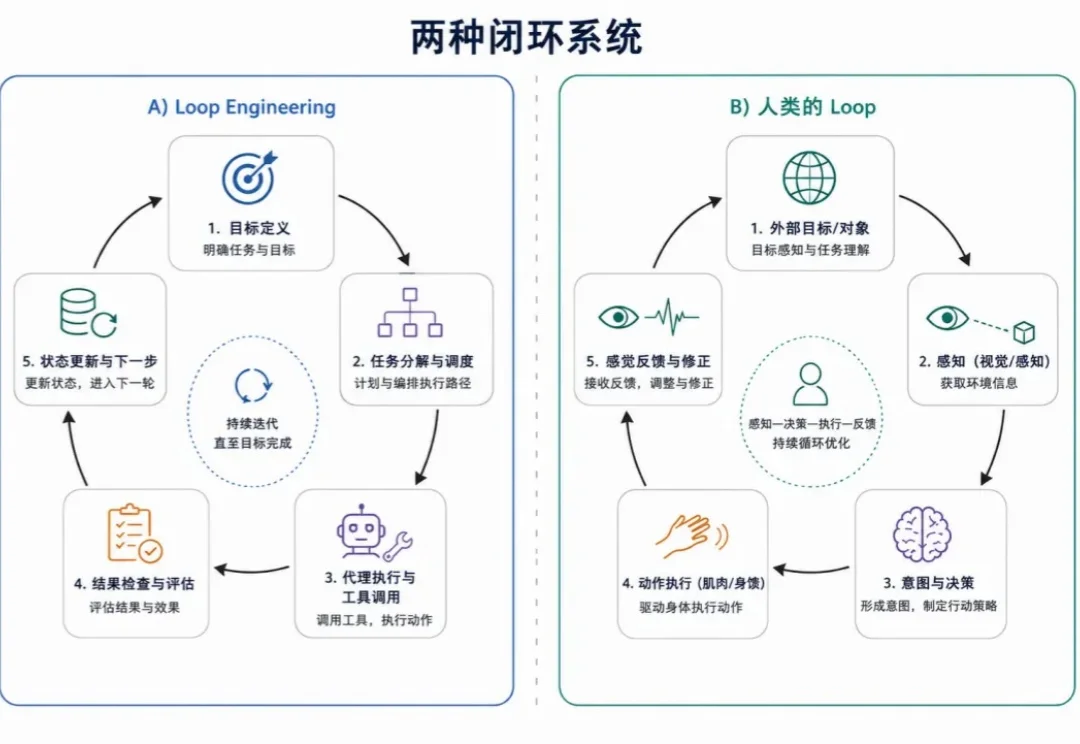
AI 圈最近又热了一个词:Loop Engineering。
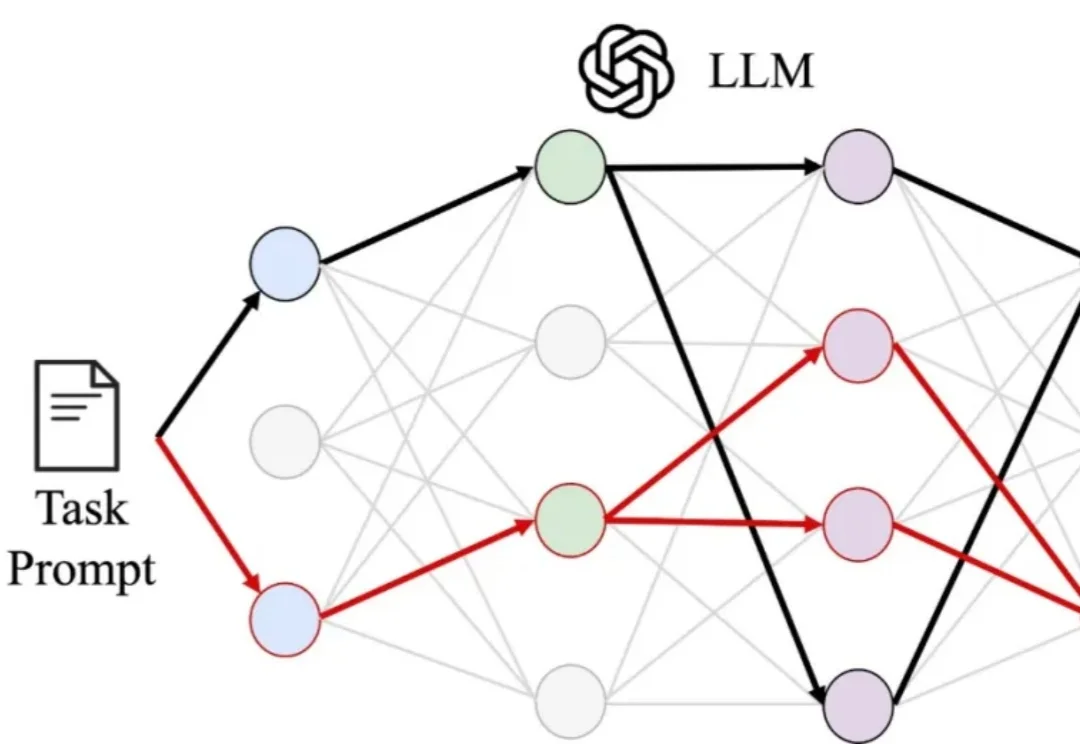
长期以来,机制可解释性(mechanistic interpretability)领域有一个几乎从未被明说、却被视为理所当然的前提:模型对于同一种任务的能力或表现,背后对应着一条唯一的、或近乎唯一的内部「电路」(circuit)。该领域的研究者们之所以要做「电路发现」(circuit discovery),是为了要把这些「特定的」电路找出来。

近期,DeepSeek发布DSpark让大模型推理效率再次成为行业焦点。

据外媒 The Information 报道:Meta 正在限制员工在 AI 模型构建中使用 Claude Code 和 Codex,原因是担心涉及模型蒸馏。 Meta 担心这些外部模型生成的内容,可能进入自家的训练数据或评测体系,从而引发所谓的模型蒸馏争议。

2026 年 6 月,大模型行业正在经历一场前所未有的「开源海啸」:英伟达放出了 550B 参数的混合架构模型,谷歌送出多模态的 Gemma 新版本,智谱用最宽松的协议全量开源了自家旗舰模型。

如今,大模型越来越擅长回答问题了,但当 AI 不再只停留在聊天窗口,而是走向智能眼镜、可穿戴设备乃至家庭机器人时,问题会随之改变。用户未必有时间把需求完整说出来,也未必希望助手随时插话。更理想的助手,应该能在现场真正理解人,在用户需要的时候出现,在不合适的时候保持安静。

随着全球智能体加速落地,算力需求呈指数级爆发,以 GPU 为核心的 AI 基础设施正变得愈发关键。据摩根士丹利报告预测,2028 年全球 AI 基础设施累计总投资将达 2.9 万亿美元。

你从桌上端起一杯水,大脑用了不到一秒,同时完成三件事: 估算杯子的重量,预判水面晃动的幅度,顺便绕开了旁边那个玻璃杯。