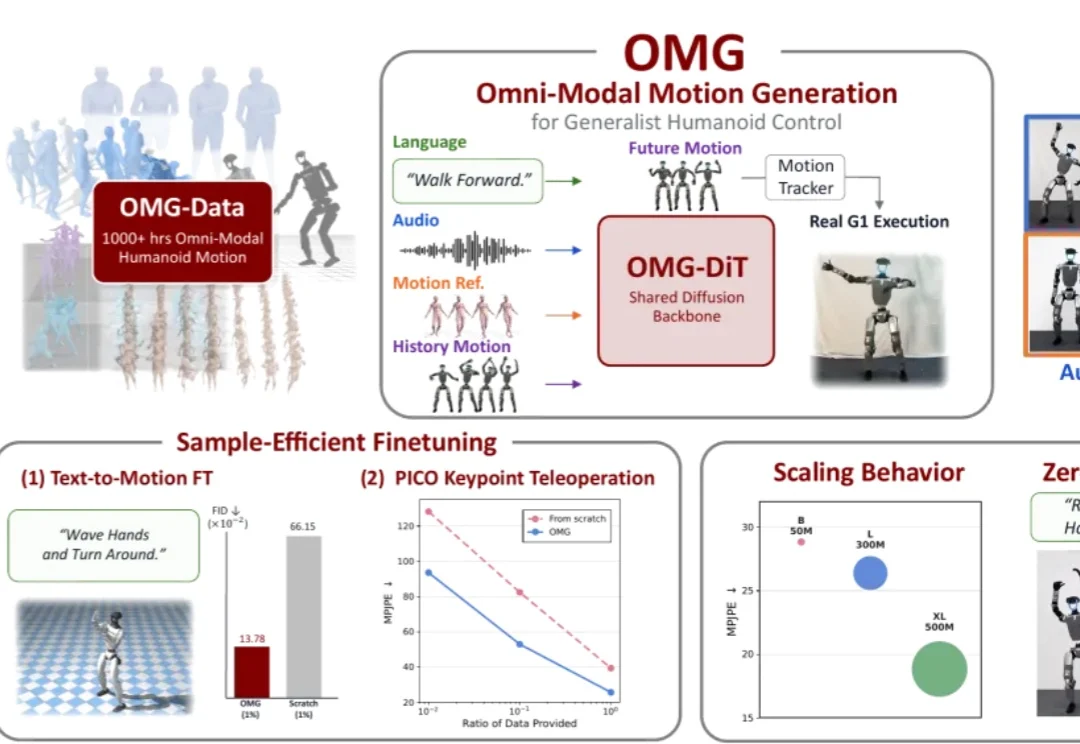
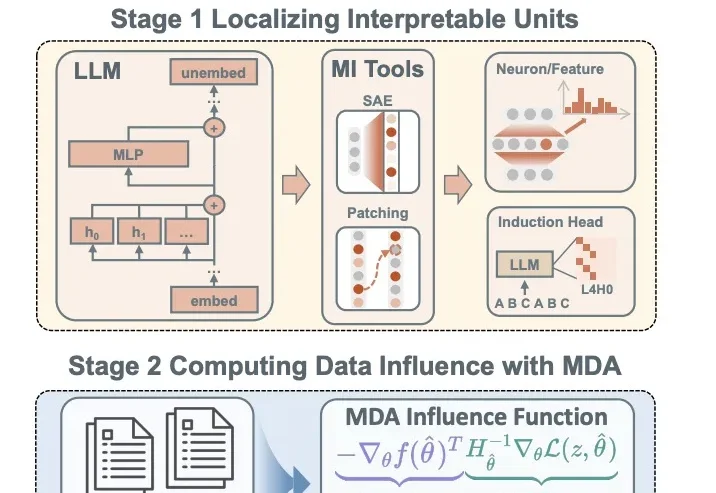
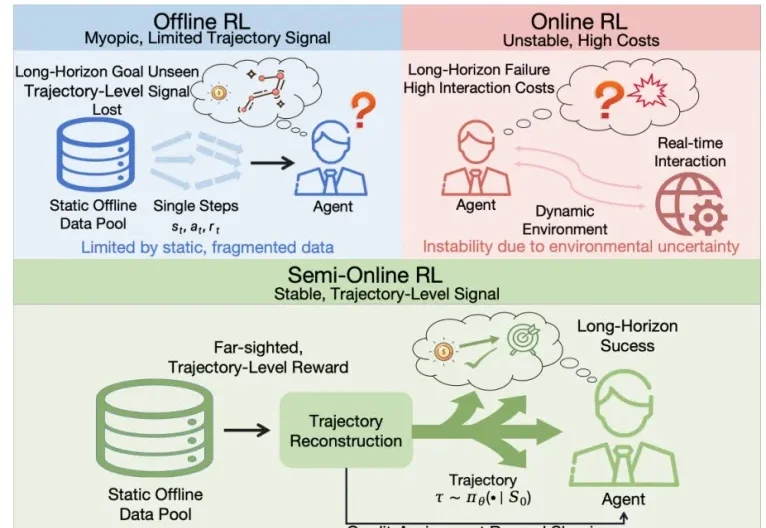
Nvidia都在点赞的LoopWM世界模型,竟然来自一家中国初创FaceMind?
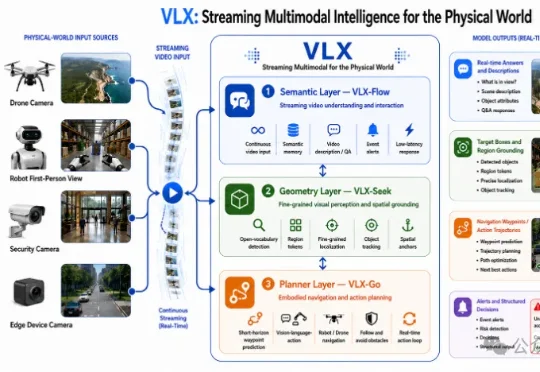
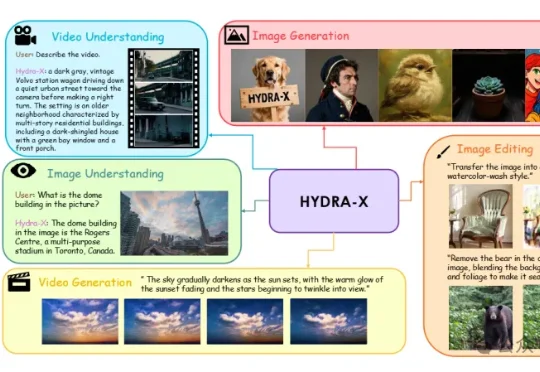
Nvidia都在点赞的LoopWM世界模型,竟然来自一家中国初创FaceMind?在世界模型这条路上,行业一直卡在一个几乎无解的矛盾里:想要更真实的长程模拟,就必须给模型更深的计算;可一旦把模型做得更深,部署成本、参数规模和误差累积又会迅速抬头。结果就是,大家都知道世界模型要 “想得更久”,却很难让它在现实系统里 “算得起、跑得稳”。
来自主题: AI技术研报
6018 点击 2026-06-29 15:54