AI圈水太深:OpenAI保密、Meta作弊!国产MoE却异军突起
AI圈水太深:OpenAI保密、Meta作弊!国产MoE却异军突起从GPT-2到Llama 4,大模型这几年到底「胖」了多少?从百亿级密集参数到稀疏MoE架构,从闭源霸权到开源反击,Meta、OpenAI、Mistral、DeepSeek……群雄割据,谁能称王?
来自主题: AI技术研报
9268 点击 2025-07-16 16:18
 搜索
搜索
从GPT-2到Llama 4,大模型这几年到底「胖」了多少?从百亿级密集参数到稀疏MoE架构,从闭源霸权到开源反击,Meta、OpenAI、Mistral、DeepSeek……群雄割据,谁能称王?

难得难得,几大AI巨头不竞争了不抢人了,改联合一起发研究了。

剧本杀大家都玩过吗?这是一种经典的桌上角色扮演游戏(TTRPG), 游戏中的核心人物是游戏主持人(GM), 相当于整个世界的「导演 + 编剧 + 旁白」,负责掌控游戏环境,讲述故事背景,并扮演所有非玩家角色(NPC)。
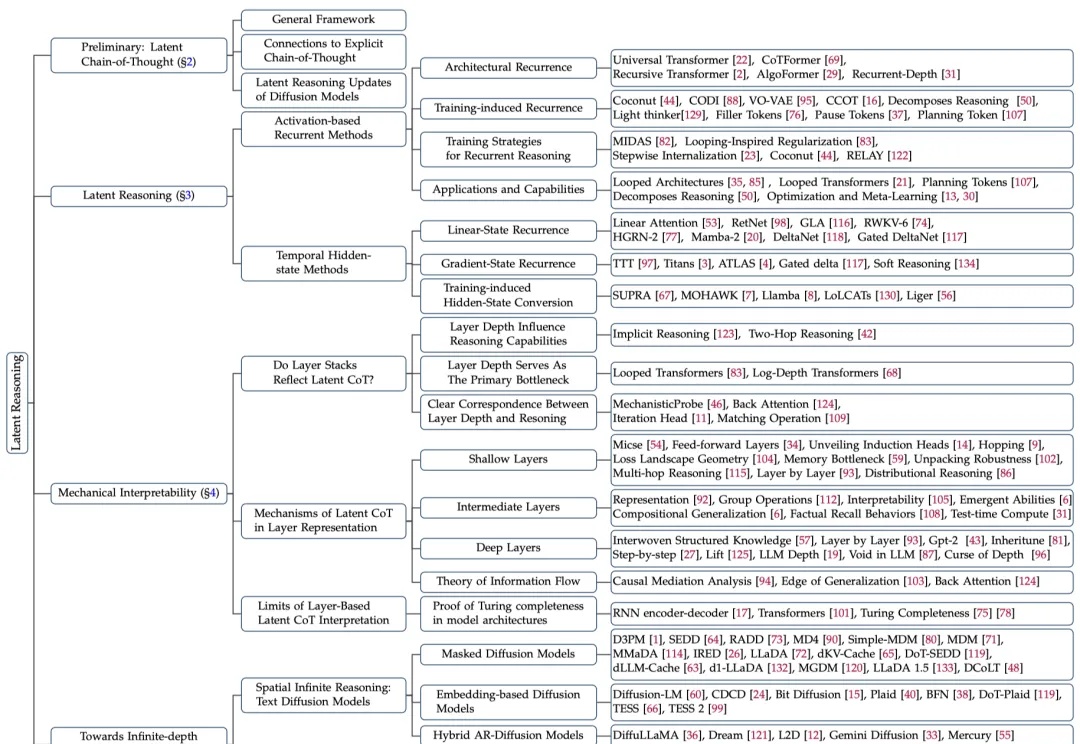
大模型在潜空间中推理,带宽能达到普通(显式)思维链(CoT)的2700多倍?

自 Stable Diffusion、Flux 等扩散模型 (Diffusion models) 席卷图像生成领域以来,文本到图像的生成技术取得了长足进步。但它们往往只能根据精确的文字或图片提示作图,缺乏真正读懂图像与文本、在多模 态上下文中推理并创作的能力。能否让模型像人类一样真正读懂图像与文本、完成多模态推理与创作,一直是学术界和工业界关注的热门问题。

一个冒号,竟然让大模型集体翻车?

MIRIX,一个由 UCSD 和 NYU 团队主导的新系统,正在重新定义 AI 的记忆格局。

我们正经历一场前所未有的智能跃迁。人工智能带来的,远不止于技术革新,更是一场深刻重塑人类认知、教育与生存方式的范式转移。

都在研究考生,考卷出问题了。

还在担心机器人只能机械执行、不会灵活应变?