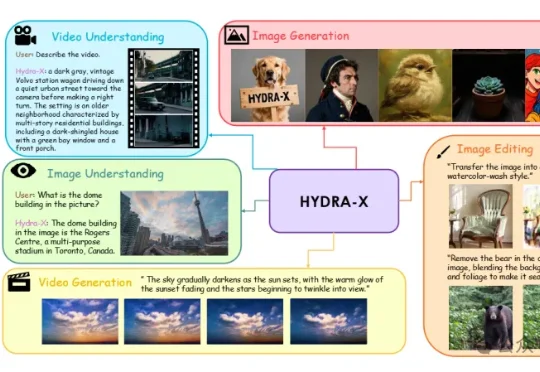
单个tokenizer胜任图像视频理解生成!南大&腾讯混元HYDRA打通多模态统一难题
单个tokenizer胜任图像视频理解生成!南大&腾讯混元HYDRA打通多模态统一难题南大王利民团队&腾讯混元的HYDRA系列(HYDRA,HYDRA-X)工作挑战了这个惯例,用一个基于ViT的统一视觉Tokenizer,帮助原生多模态模型更好地“看懂”和“创作”。训练一个基于ViT的Unified Tokenizer,使其同时具有理解和生成的能力,进而同时作为理解和生成的Autoencoder,来支持原生多模态模型(Unified Multimodal Models)的训练。
来自主题: AI技术研报
8755 点击 2026-06-28 11:13