清华NANO滤波器:非线性贝叶斯状态估计迈入优化迭代计算的新范式
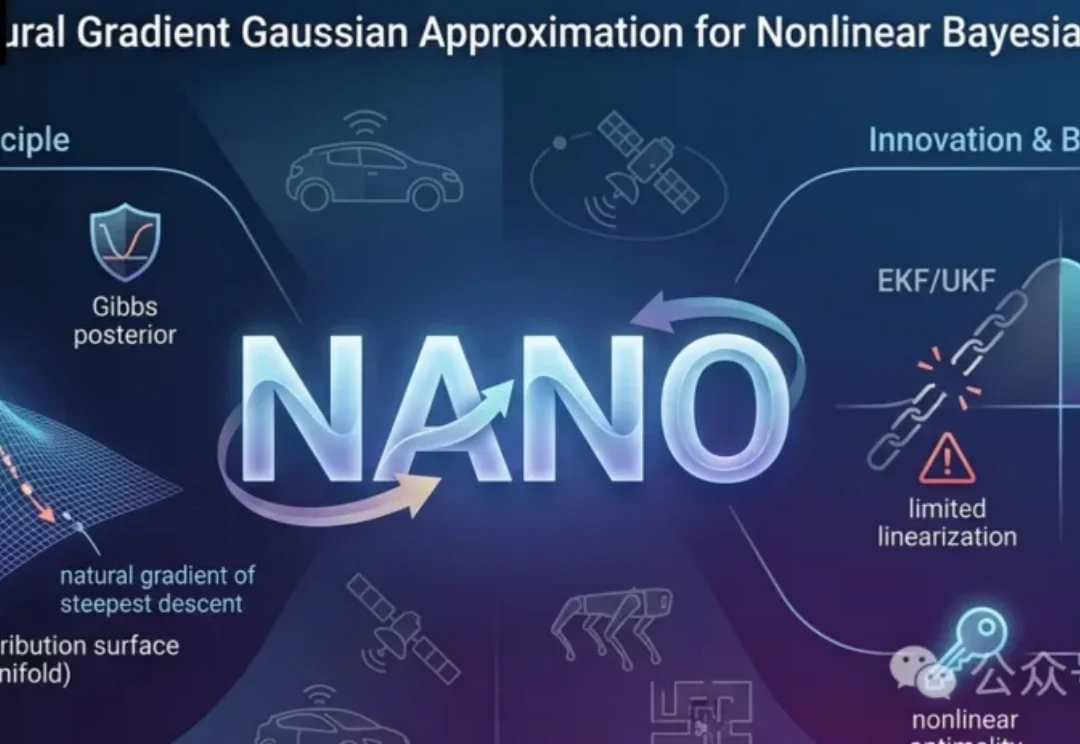
清华NANO滤波器:非线性贝叶斯状态估计迈入优化迭代计算的新范式NANO滤波器是一种新的非线性贝叶斯状态估计方法,它不依赖线性化模型,而是将预测和更新步骤转化为优化问题。这种方法在高斯分布空间中使用自然梯度,更精确地逼近最优后验,同时利用Stein引理避免显式求导,提升鲁棒性。
来自主题: AI技术研报
7452 点击 2026-06-22 15:15
 搜索
搜索
NANO滤波器是一种新的非线性贝叶斯状态估计方法,它不依赖线性化模型,而是将预测和更新步骤转化为优化问题。这种方法在高斯分布空间中使用自然梯度,更精确地逼近最优后验,同时利用Stein引理避免显式求导,提升鲁棒性。

Claude新模型要来了?据悉,Sonnet-5已经现身,下一代神级模型Fennec最快下周上线!而且,Mythos 5.1或6,已经在内部完成训练,Mythos升级版仅用60天跨代诞生。全面封锁,反而让Anthropic的迭代疯狂加速了!

就在最近,OpenAI扔出一篇重磅论文。他们发现,只教AI好好看病,它写代码居然也不作弊了。方法简单到离谱:拿5%的训练数据,教模型在回答健康问题时诚实、谨慎、知错能改。
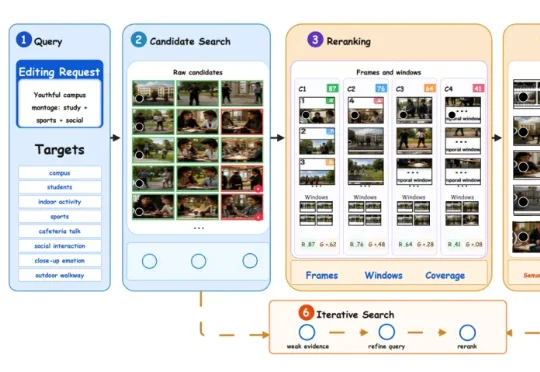
近年来,大语言模型(LLMs)在长篇视觉叙事中展现出卓越潜力,生产方式正迅速从单一模型生成转向面向生产的智能体系统。但长视频剪辑仍然是一个极难控制的长期任务。模型有时会在缺乏素材依据的情况下强行生成,甚至在面对明显断档的转场或人物不一致时依然“盲目拼接”。
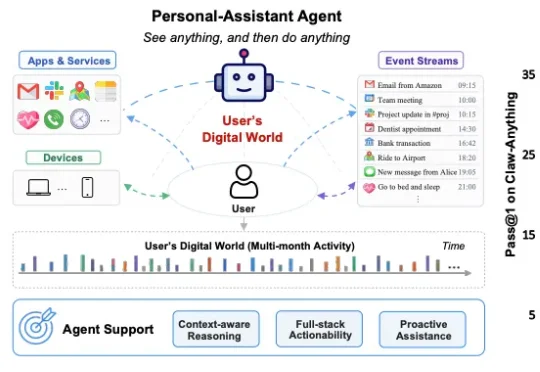
我们相信,常驻型 (always-on) AI 助理的下一次飞跃,不在于把某一个模型单点调得更聪明,而在于扩展智能体的上下文 (Scaling Agent Context)—— 不断拓宽助理能够持续 "感知 — 推理 — 执行" 的范围,作为生活连接器连接用户的信息孤岛,直到它能接管用户的整个数字世界。

来自西湖大学和香港中文大学(深圳)的团队沿着这一思路提出 Drifting Preference Optimization(DrPO),把漂移场用于单步文生图模型的偏好后训练。在 DrPO 中,奖励只负责对候选图像排序,不参与反向传播。具体而言,针对同一个文本提示词,当前模型生成一组候选图像。高分样本在特征空间中产生吸引,低分样本产生排斥,并结合参考模型约束给出模型的更新方向。

如今,CameraSquad 的出现,让这种多视角一致的视频生成与 3D 世界状态构建成为现实。近日,中国科学院大学高林研究员团队联合卡迪夫大学、香港科技大学和快手可灵团队,提出了一种面向多轨迹并行生成的相机可控视频生成方法 CameraSquad [1],相关论文已被 ACM SIGGRAPH 2026 录用。
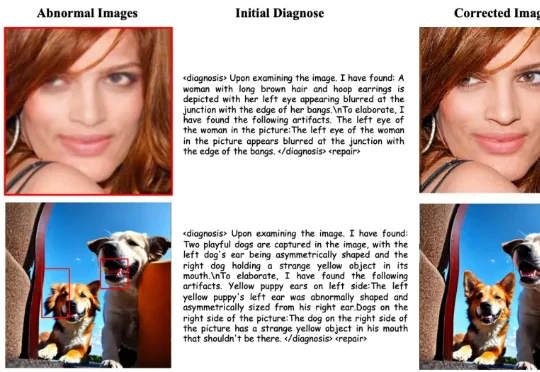
对于 AI 生成图像中可能存在的不自然伪影,我们是否不仅能够将其定位和解释,还能进一步对其进行修复,使图像恢复为更加真实、自然的视觉外观?围绕这一问题,来自北京大学等机构的研究者提出了 GenShield:一个统一的自回归框架,将 AI 生成图像检测 与 图像伪影修复 结合到同一个闭环中,实现从 “诊断” 到 “修复” 的一体化建模。
很多人认为这个数字不是随便挑的:美国政府向 Anthropic 下发出口管制指令、切断 Fable 5 与 Mythos 5 境外访问权限的那一刻,正是美国东部时间下午 5 点 21 分。「5 点 21」这个数字上的重复,被多家媒体解读为一次刻意设计的呼应。智谱选择在这个节点站出来,相当于当着全世界开发者的面说了一句话:你们担心的「模型随时可能被收回」,开源这边没有这个问题。

银河通用团队用史上最大、整整 20 亿帧的动捕数据,训练出了全球首个人形机器人全身实时运控基座大模型,该模型零样本泛化全新动作,成功率从 MLP 架构的 76.89% 跃至 92.58%,推理延迟仅 0.39ms,效果超越英伟达 SONIC,甚至比目前业内主流 TWIST 系统速度提升至五倍。