
帮大模型提速80%,华为拿出昇腾推理杀手锏FlashComm,三招搞定通算瓶颈
帮大模型提速80%,华为拿出昇腾推理杀手锏FlashComm,三招搞定通算瓶颈在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。
来自主题: AI技术研报
8213 点击 2025-05-23 10:18
 搜索
搜索
在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。在今年 2 月的 DeepSeek 开源周中,大模型推理过程中并行策略和通信效率的深度优化成为重点之一。
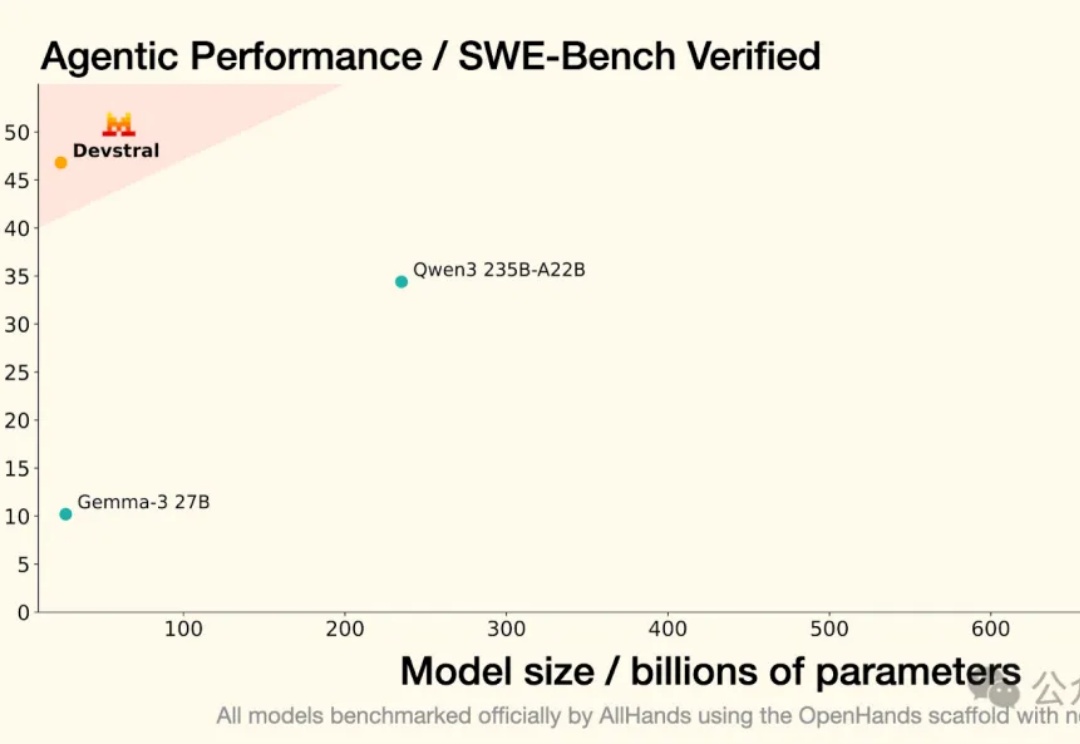
Mistral沉默好久,果然在憋大招。

「仿生人会梦见电子羊吗?」这是科幻界一个闻名遐迩的问题。现在英伟达给出答案:Yes!而且还可以从中学习新技能。如下面各种丝滑操作,都没有真实世界数据作为训练支撑。仅凭文本指令,机器人就完成相应任务。
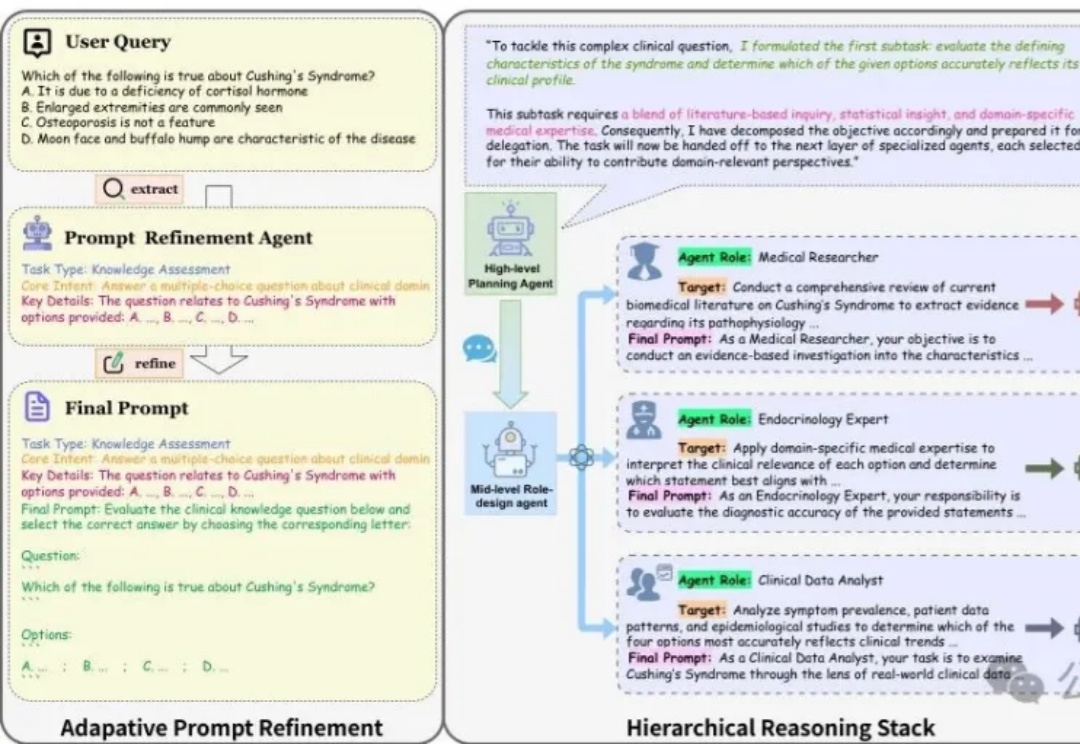
HALO框架通过三大创新机制重塑多Agent(MAS)协作方式:层次化推理架构克服了认知过载问题,让智能体各司其职;动态角色实例化能针对不同任务匹配专业智能体;基于MCTS的搜索引擎自动探索最优推理路径。它能将模糊的用户查询转化为专业提示,分解复杂任务并动态调整执行计划。
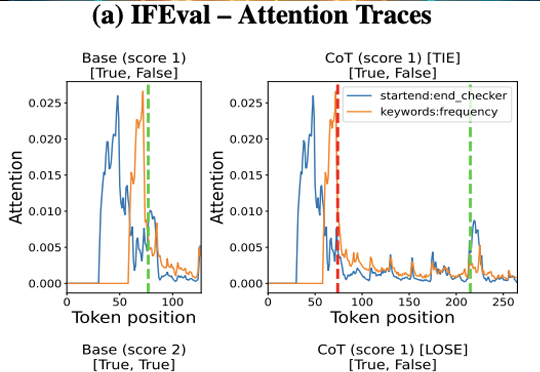
DeepSeek-R1火了,推理模型火了,思维链(Chain-of-Thought,CoT)火了!

不再依赖语言,仅凭图像就能完成模型推理?

何恺明团队又一力作!这次他们带来的是「生成模型界的降维打击」——MeanFlow:无需预训练、无需蒸馏、不搞课程学习,仅一步函数评估(1-NFE),就能碾压以往的扩散与流模型!

刚刚,昇腾两大技术创新,突破速度瓶颈重塑AI推理。FusionSpec创新的框架设计配合昇腾强大的计算能力,将投机推理框架耗时降至毫秒级,打破延迟魔咒。OptiQuant支持灵活量化,让推理性价比更高。

大语言模型(LLM)的生成范式正在从传统的「单人书写」向「分身协作」转变。传统自回归解码按顺序生成内容,而新兴的异步生成范式通过识别语义独立的内容块,实现并行生成。

京东探索研究院关于大模型的最新研究,登上了Nature旗下期刊!