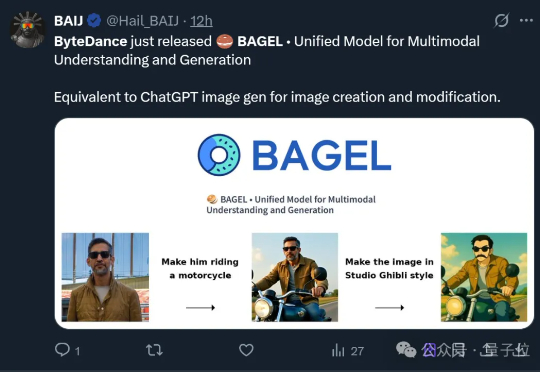
字节把GPT-4o级图像生成能力开源了!
字节把GPT-4o级图像生成能力开源了!字节最近真的猛猛开源啊……这一次,他们直接开源了GPT-4o级别的图像生成能力。不止于此,其最新融合的多模态模型BAGEL主打一个“大一统”, 将带图推理、图像编辑、3D生成等功能全都集中到了一个模型。
来自主题: AI技术研报
10553 点击 2025-05-24 17:34
 搜索
搜索
字节最近真的猛猛开源啊……这一次,他们直接开源了GPT-4o级别的图像生成能力。不止于此,其最新融合的多模态模型BAGEL主打一个“大一统”, 将带图推理、图像编辑、3D生成等功能全都集中到了一个模型。
OpenAI 研究员姚顺雨近期发布文章,指出:AI 下半场将聚焦问题定义与评估体系重构。在 AI 发展新阶段,行业需要通过设计更有效的模型评测体系,弥补 AI 能力与真实需求的差距。
本文详细解读了 Kimi k1.5、OpenReasonerZero、DAPO 和 Dr. GRPO 四篇论文中的创新点,读完会对 GRPO 及其改进算法有更深的理解,进而启发构建推理模型的新思路。
无需数据配对,文本嵌入也能互通?康奈尔重磅研究:所有模型都殊途同归。曾因llya离职OpenAI,在互联网上掀起讨论飓风的柏拉图表示假说提出:所有足够大规模的图像模型都具有相同的潜在表示。

上月,ChatGPT-4o无条件跪舔用户,被OpenAI紧急修复。然而,ICLR 2025的文章揭示LLM不止会「跪舔」,还有另外5种「套路」。
咱就是说啊,视觉基础模型这块儿,国产AI真就是上了个大分——Glint-MVT,来自格灵深瞳的最新成果。Glint-MVT,来自格灵深瞳的最新成果先来看下成绩——线性探测(LinearProbing):

来自香港科技大学、腾讯西雅图AI Lab、爱丁堡大学、Miniml.AI、英伟达的研究者联合提出了MMLongBench,旨在全面评估多模态模型的长文本理解能力。
来自香港中文大学(深圳)等单位的学者们提出了一种名为 DriveGEN 的无训练自动驾驶图像可控生成方法。该方法无需额外训练生成模型,即可实现训练图像数据的可控扩充,从而以较低的计算资源成本提升三维检测模型的鲁棒性。

在机器人操作中,物体运动往往涉及摩擦、碰撞等复杂物理机制。准确的物理属性描述可以实现对物体运动结果更准确的预测,并提升机器人在操作技能学习中的表现。
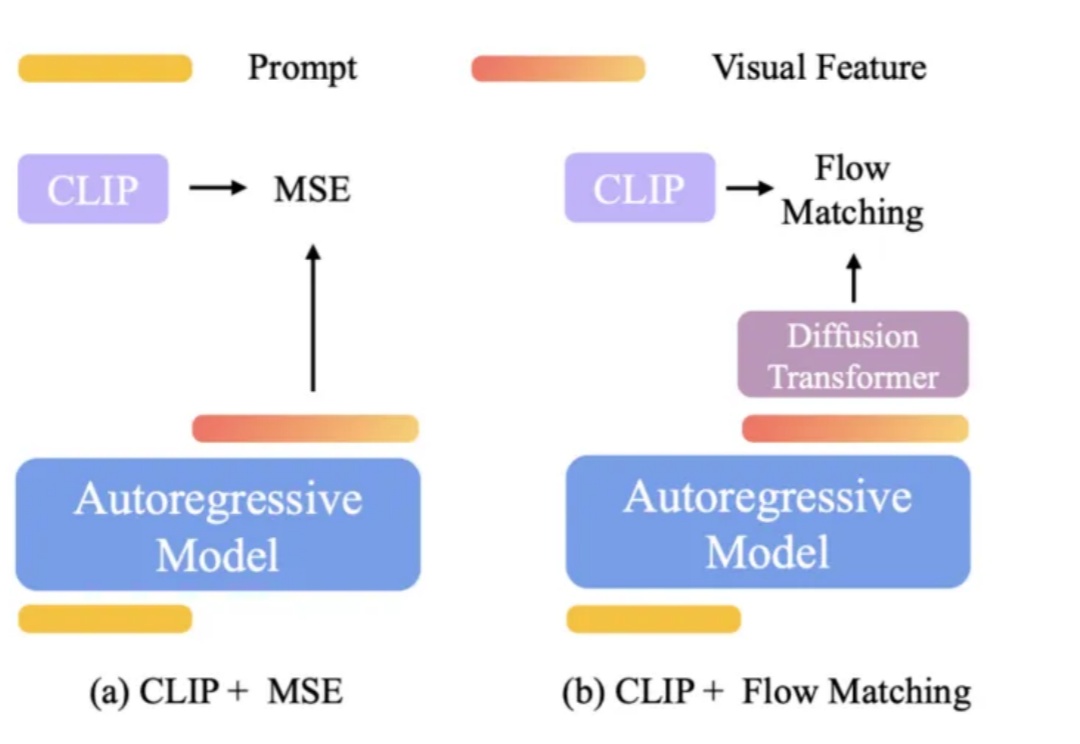
OpenAI 的 GPT-4o 在图像理解、生成和编辑任务上展现了顶级性能。流行的架构猜想是: