
梁文锋署名DeepSeek新论文:公开V3大模型降本方法
梁文锋署名DeepSeek新论文:公开V3大模型降本方法梁文锋亲自参与的DeepSeek最新论文,来了!
来自主题: AI技术研报
9023 点击 2025-05-16 11:47
 搜索
搜索
梁文锋亲自参与的DeepSeek最新论文,来了!
打破科技巨头算力垄断,个人开发者联手也能训练超大规模AI模型?
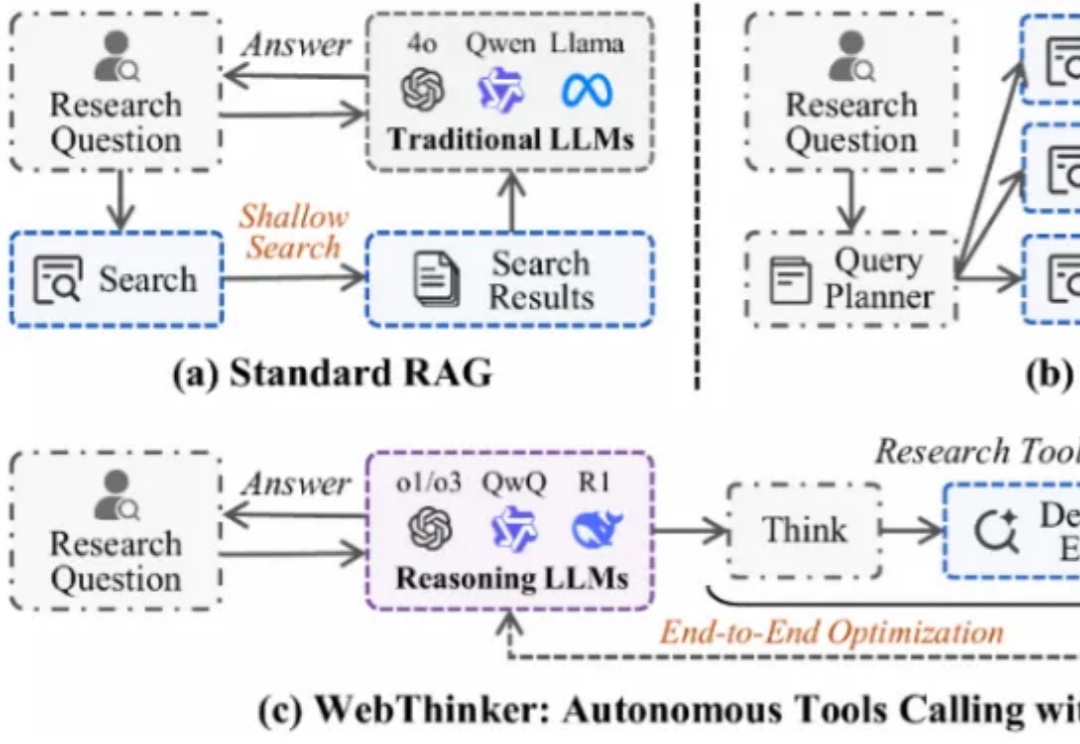
大型推理模型(如 OpenAI-o1、DeepSeek-R1)展现了强大的推理能力,但其静态知识限制了在复杂知识密集型任务及全面报告生成中的表现。为应对此挑战,深度研究智能体 WebThinker 赋予 LRM 在推理中自主搜索网络、导航网页及撰写报告的能力。
在上一篇文章中,我为大家介绍了SAT如何通过神经网络驱动的智能分段技术,解决传统文本处理中的语义割裂问题。今天,我将继续与您探讨SAT如何与Pneuma系统融合,开创表格数据检索与表示的新范式。
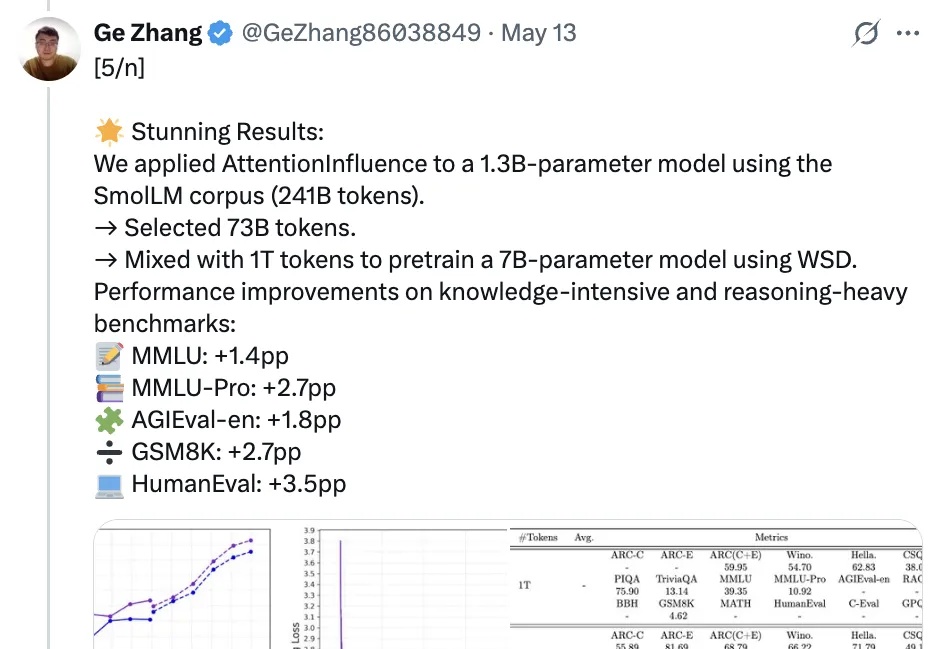
和人工标记数据说拜拜,利用预训练语言模型中的注意力机制就能选择可激发推理能力的训练数据!

DeepSeek最新论文深入剖析了V3/R1的开发历程,揭示了硬件与大语言模型架构协同设计的核心奥秘。论文展示了如何突破内存、计算和通信瓶颈,实现低成本、高效率的大规模AI训练与推理。不仅总结了实践经验,还为未来AI硬件与模型协同设计提出了建议。
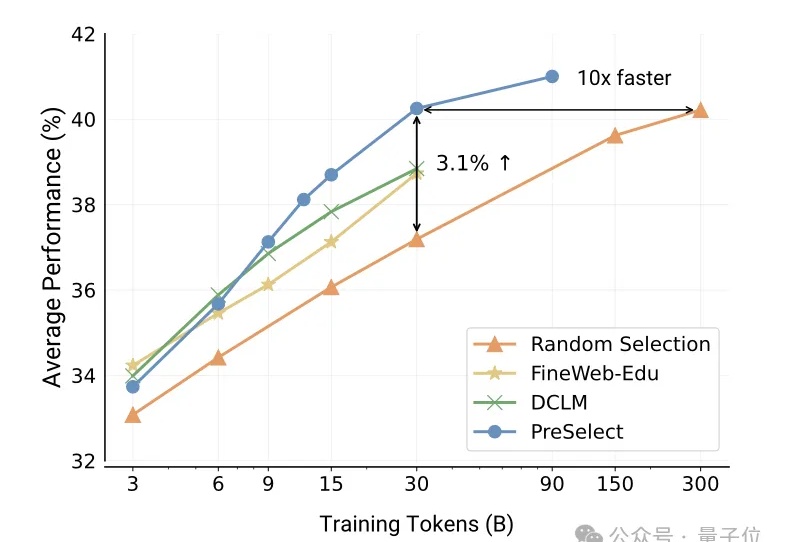
vivo自研大模型用的数据筛选方法,公开了。

搞RAG开发,一个被普遍忽视却又至关重要的痛点是:如何避免Token分块带来的语义割裂问题。SAT模型通过神经网络驱动的智能分段技术,巧妙解决了这一难题。它不是RAG的替代,而是RAG的强力前置增强层,通过确保每个文本块的语义完整性,显著降低下游生成的幻觉风险。

R1 横空出世,带火了 GRPO 算法,RL 也随之成为 2025 年的热门技术探索方向,近期,字节 Seed 团队就在图像生成方向进行了相关探索。
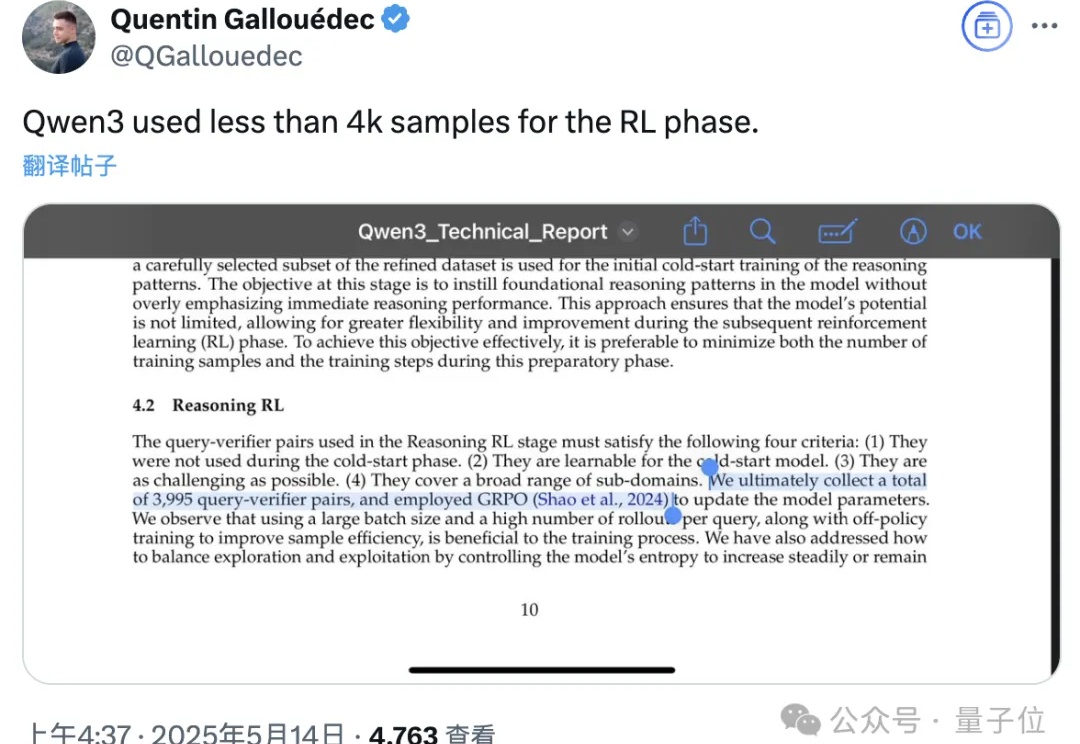
Qwen3技术报告新鲜出炉,8款模型背后的关键技术被揭晓!