清华朱军团队 | 从点云到高保真三维网格:DeepMesh突破自回归生成瓶颈
清华朱军团队 | 从点云到高保真三维网格:DeepMesh突破自回归生成瓶颈在三维数字内容生产领域,三角形网格作为核心的几何表示形式,其质量直接影响虚拟资产在影视、游戏和工业设计等应用场景中的表现与效率。
来自主题: AI技术研报
6411 点击 2025-03-31 15:31
 搜索
搜索
在三维数字内容生产领域,三角形网格作为核心的几何表示形式,其质量直接影响虚拟资产在影视、游戏和工业设计等应用场景中的表现与效率。
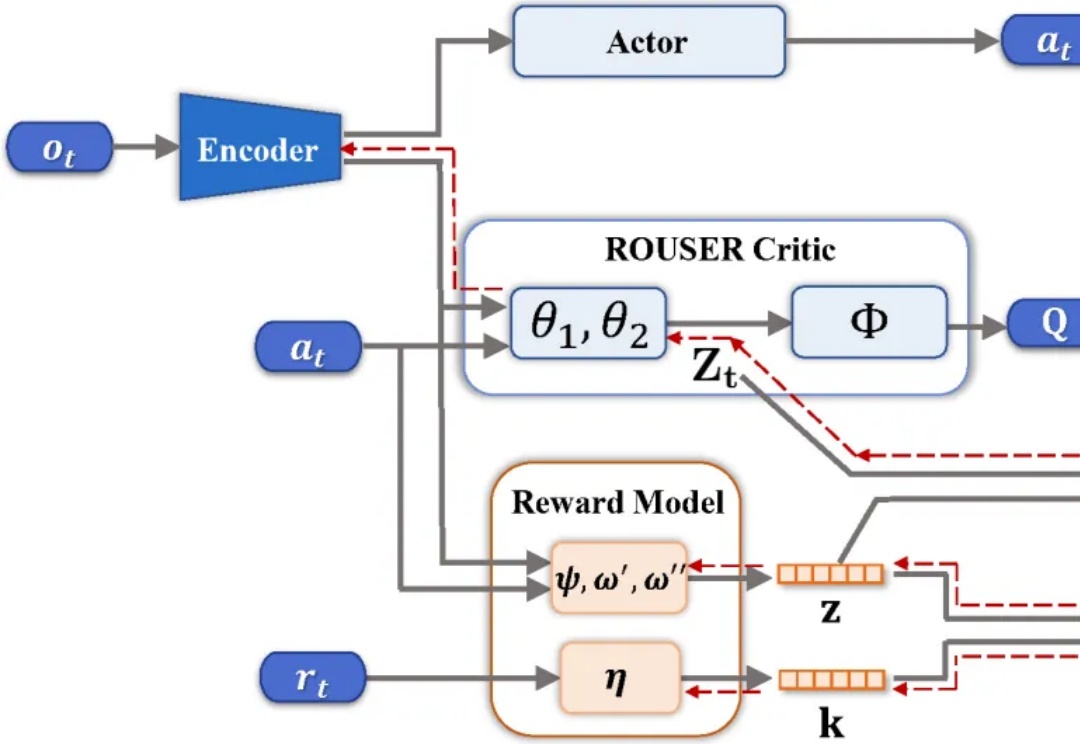
在视觉强化学习中,许多方法未考虑序列决策过程,导致所学表征缺乏关键的长期信息的空缺被填补上了。
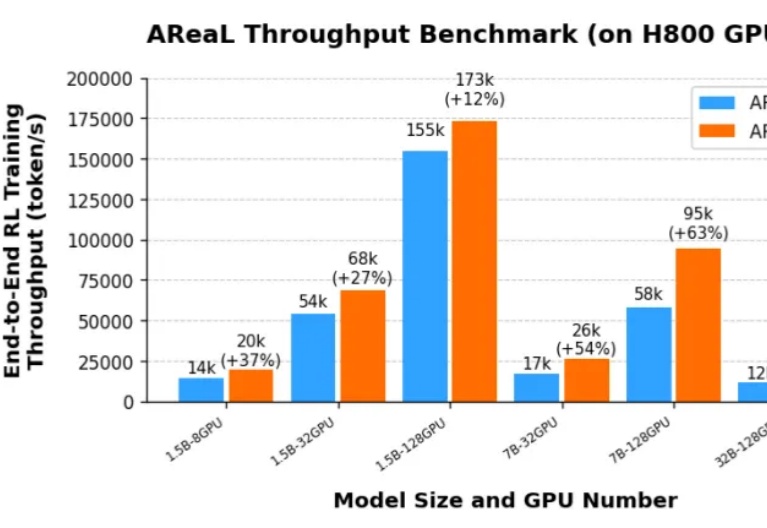
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高:

你是否曾对着一个繁复的AI框架,无奈地想:"真有必要搞得这么复杂吗?"在与臃肿框架斗争一年后,Zachary Huang博士决定大刀阔斧地革新,剔除所有花里胡哨的部分。于是Pocket Flow诞生了——一个仅有100行代码的超轻量级大语言模型框架!

当你翻开相册,看到一张平淡无奇的风景照,是否希望它能更温暖、更浪漫,甚至更忧郁?现在,EmoEdit 让这一切成为可能 —— 只需输入一个简单的情感词,EmoEdit 便能巧妙调整画面,使观众感知你想传递的情感。

你是否注意过人类观察世界的独特方式?
最近,AI 公司 Databricks 推出了一种新的调优方法 TAO,只需要输入数据,无需标注数据即可完成。更令人惊喜的是,TAO 在性能上甚至超过了基于标注数据的监督微调。

史上最大的基因组AI模型Evo 2使用超过12.8万个基因组数据训练,包含9.3万亿个核苷酸,能预测突变效应、设计 DNA 序列,并通过可视化工具展示学习到的生物特征,为生成生物学和疾病研究提供新思路。
论文第一作者为余鑫,香港大学三年级博士生,通讯作者为香港大学齐晓娟教授。主要研究方向为生成模型及其在图像和 3D 中的应用,发表计算机视觉和图形学顶级会议期刊论文数十篇,论文数次获得 Oral, Spotlight 和 Best Paper Honorable Mention 等荣誉。此项研究工作为作者于 Adobe Research 的实习期间完成。

幻觉(Hallucination),即生成事实错误或不一致的信息,已成为视觉-语言模型 (VLMs)可靠性面临的核心挑战。随着VLMs在自动驾驶、医疗诊断等关键领域的广泛应用,幻觉问题因其潜在的重大后果而备受关注。