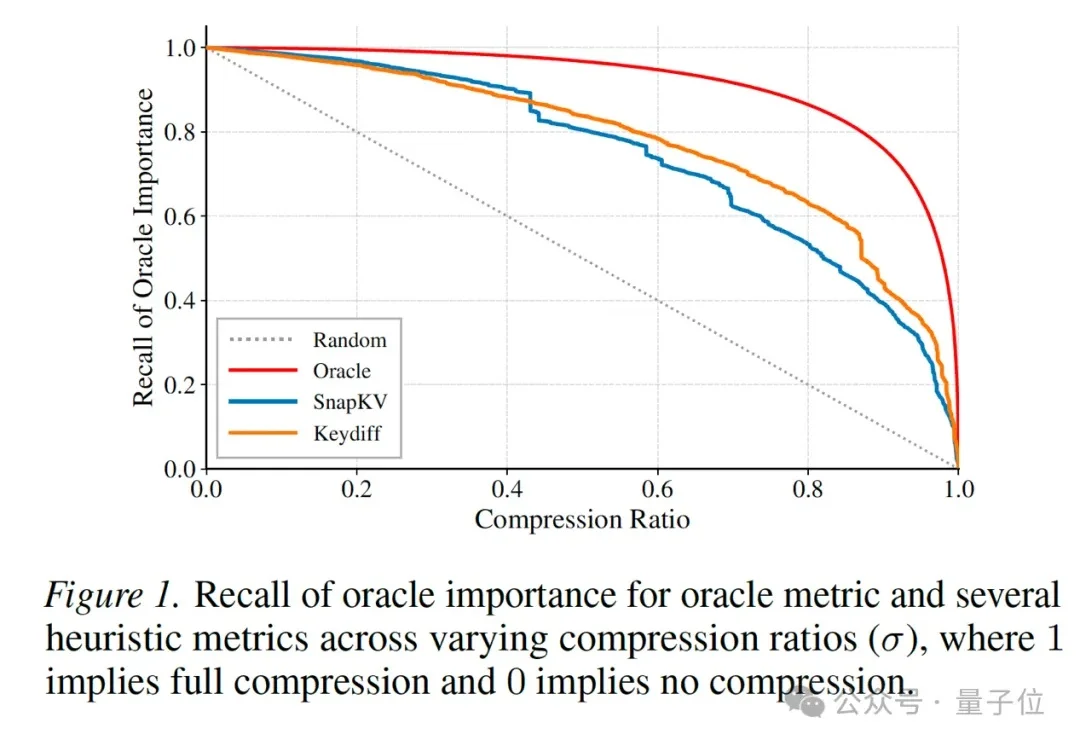
KV Cache终于不用无脑全留了!百度&复旦用「投资回报率」重新分配缓存|ICML 2026
KV Cache终于不用无脑全留了!百度&复旦用「投资回报率」重新分配缓存|ICML 2026随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。
来自主题: AI技术研报
9900 点击 2026-06-15 09:18
 搜索
搜索
随着AI Coding、Agent、Deep Research 等应用快速普及,模型单次处理的上下文长度正在从几万Token迈向几十万甚至百万Token。
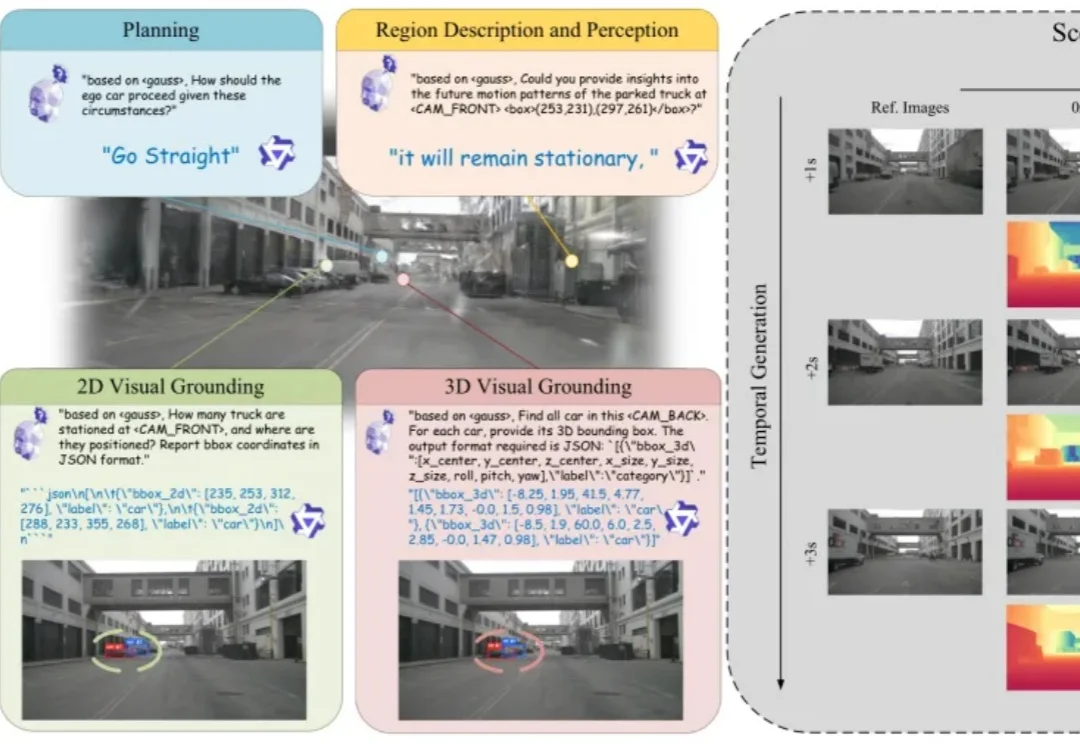
自动驾驶世界模型的研究目标已经从单纯预测未来视觉帧,扩展到构建可用于场景理解、空间定位和后续决策的世界表示。如果模型只能生成外观上合理的未来图像,却无法回答场景中有哪些目标、目标位于何处,以及不同视角下的空间结构如何变化,那么它仍然缺少对三维驾驶环境的显式建模能力。
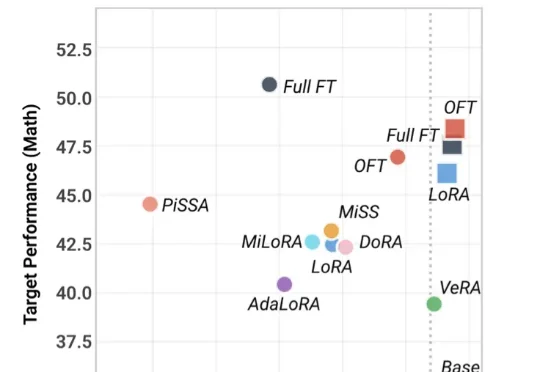
近期,来自香港中文大学、西湖大学、德国马普所等机构的研究者提出了 PEFT-Arena —— 一个从稳定性‑可塑性权衡(stability–plasticity trade-off)视角重新审视 PEFT 方法的评测基准与分析框架。该工作已在 ICLR 2026 相关 workshop 上进行了展示,并开源了完整代码。

今天,由李飞飞联合创立的空间智能公司 World Labs 在同一天发布了三篇技术论文!三篇论文分别由公司内部实习生主导完成,研究方向各异,但共享同一个核心命题:借助已在海量图片数据上训练成熟的 2D 生成模型,降低 3D 内容生成的难度门槛。

香港城市大学曾晓成教授与中国石油大学(华东)钟杰教授团队给出了终结级的分子水平证据,成果发表于《Nature Physics》。他们首创了一套无监督深度学习框架,不给AI任何预设条件,直接把海量水系统中7400多万个水分子结构扔给模型,让AI自己去悟。结果不仅直接证明常压水里确实存在两种「暗」组份,还把A/B水分子相互变身的「立交桥」路线图给完整画了出来。
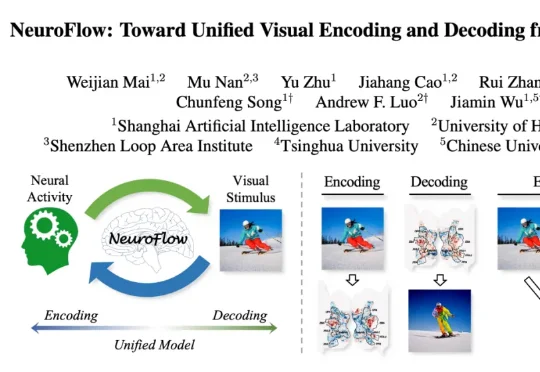
来自上海人工智能实验室、香港大学、香港中文大学等机构的研究团队,提出首个基于统一神经流模型的视觉-神经双向建模框架NeuroFlow,相关成果入选 CVPR 2026。它首次将视觉编码(写脑)与解码(读脑)整合到同一可逆流结构中,打通视觉感知与神经活动之间的双向通路,为理解人类视觉认知机制、构建下一代通用视觉假体与双向脑机接口提供了全新范式。

上下文攻击、供应链渗透、AI社区崩溃……当大模型智能体真正进入开放世界,挑战远比想象中复杂。
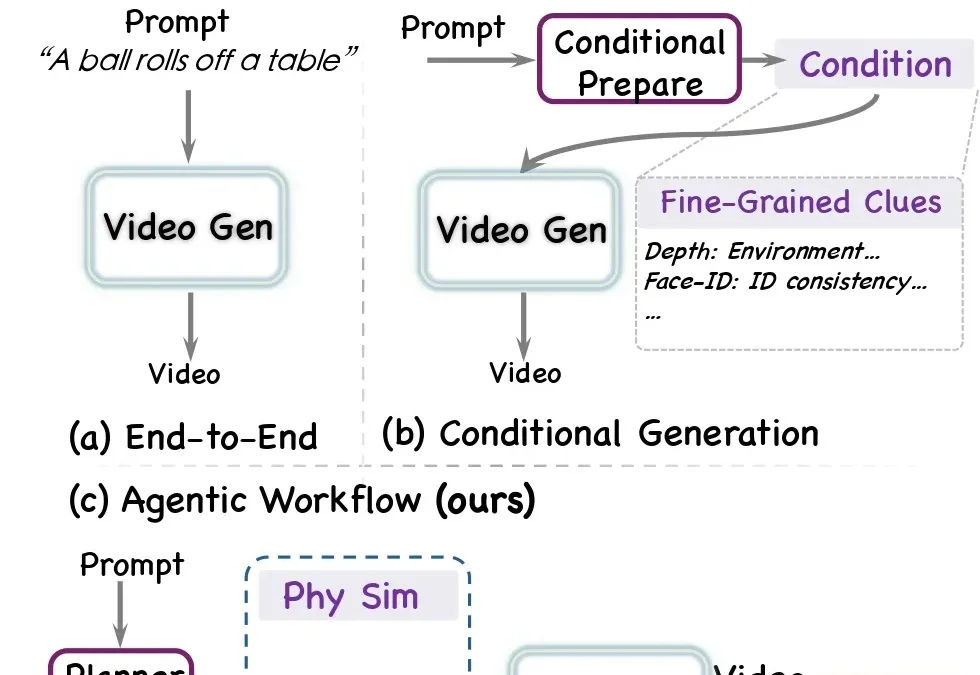
近年来,视频生成模型发展迅猛。从 Sora、Veo、Kling 到一系列开源视频生成模型,文生视频已经逼近真实影像的观感 —— 画面清晰、镜头流畅、风格可控,一句话就能生成一段观感不错的视频。
如果把一个商业化产品、一个科技公司的底层系统比作一棵树,那任意挑出一个项目,层层抽丝剥茧之后,你一定会发现,最早的年轮,一定与开源有关。

近日,Anthropic 发布了一篇引发广泛关注的文章《When AI builds itself》。文中披露了极其惊人的内部数据:截至 2026 年 5 月,Anthropic 超过 80% 的合并代码已由 Claude 编写,工程师的日常代码产出飙升了 8 倍;更令人瞩目的是,AI 智能体已经可以自主提出假设、执行长达数百小时的强化安全实验。