不断用AI自己生成的内容去喂它,你猜怎么着?
不断用AI自己生成的内容去喂它,你猜怎么着?ChatGPT等聊天机器人背后的算法能从各种各样的网络文本中抓取万亿字节的素材,文本来源可以是网络文章,也可以是社媒平台的帖子,还可以是视频里的字幕或评论。
来自主题: AI技术研报
5250 点击 2025-01-24 13:13
 搜索
搜索
ChatGPT等聊天机器人背后的算法能从各种各样的网络文本中抓取万亿字节的素材,文本来源可以是网络文章,也可以是社媒平台的帖子,还可以是视频里的字幕或评论。

时隔不到一个月,DeepSeek又一次震动全球AI圈。去年 12 月,DeepSeek推出的DeepSeek-V3在全球AI领域掀起了巨大的波澜,它以极低的训练成本,实现了与GPT-4o和Claude Sonnet 3.5等顶尖模型相媲美的性能,震惊了业界。

刚刚发布的豆包大模型1.5,不仅多模态能力全面提升,霸榜多个基准;更难得的是,它在训练过程中从未使用过任何其他模型生成的数据,坚决不走蒸馏「捷径」。

研究者提出了FAST,一种高效的动作Tokenizer。通过结合离散余弦变换(DCT)和字节对编码(BPE),FAST显著缩短了训练时间,并且能高效地学习和执行复杂任务,标志着机器人自回归Transformer训练的一个重要突破。
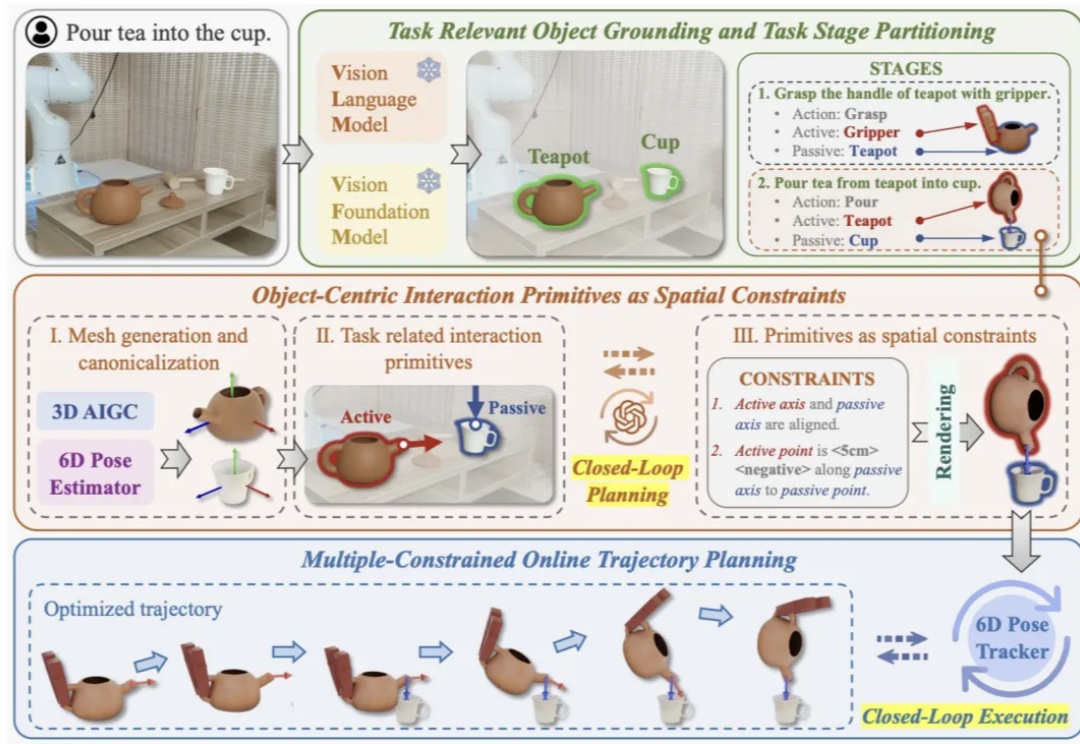
近年来视觉语⾔基础模型(Vision Language Models, VLMs)在多模态理解和⾼层次常识推理上⼤放异彩,如何将其应⽤于机器⼈以实现通⽤操作是具身智能领域的⼀个核⼼问题。这⼀⽬标的实现受两⼤关键挑战制约:
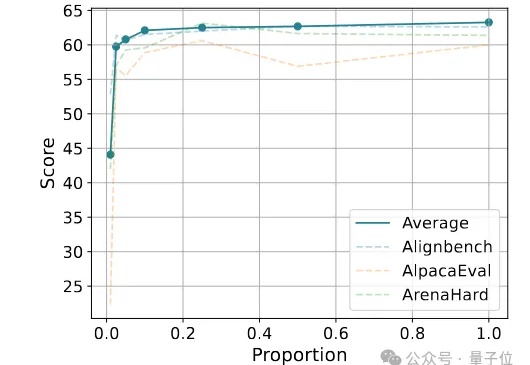
仅使用20K合成数据,就能让Qwen模型能力飙升——
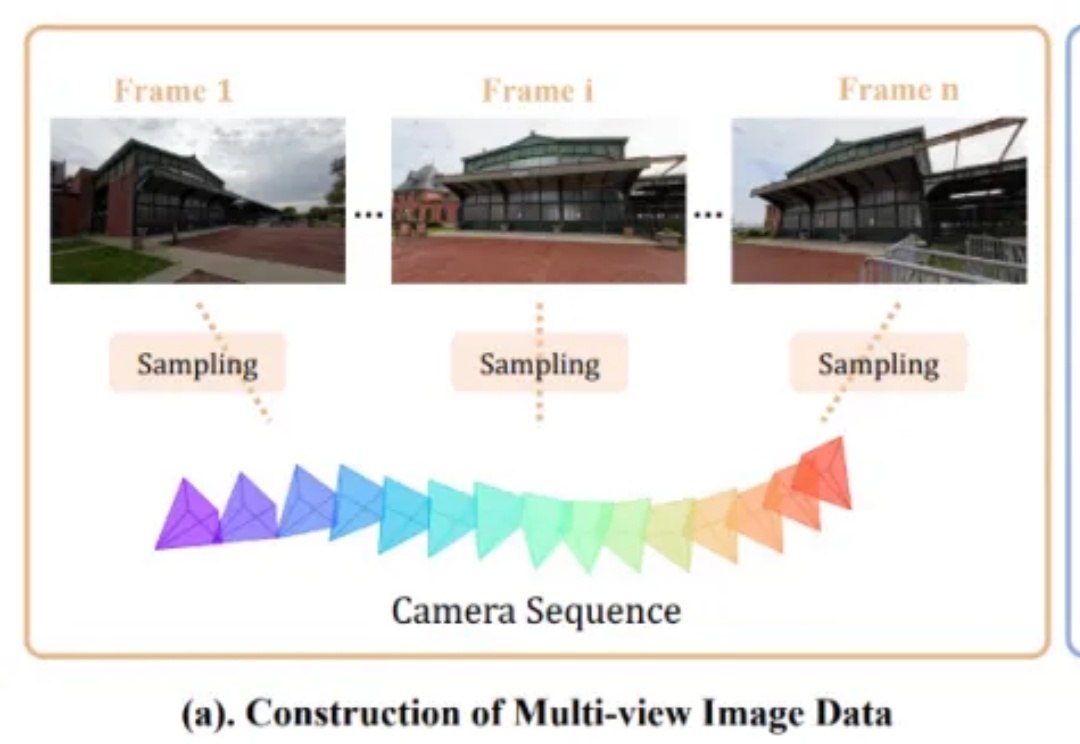
可灵,视频生成领域的佼佼者,近来动作不断。继发布可灵 1.6 后,又公开了多项研究揭示视频生成的洞察与前沿探索 ——《快手可灵凭什么频繁刷屏?揭秘背后三项重要研究》。

就在刚刚,Verses团队研发的Genius智能体,在Pong中超越了人类顶尖玩家!而且它仅仅训练2小时,用了1/10数据,就秒杀了其他顶级AI模型。

模型蒸馏也有「度」,过度蒸馏,只会导致模型性能下降。最近,来自中科院、北大等多家机构提出全新框架,从两个关键要素去评估和量化蒸馏模型的影响。结果发现,除了豆包、Claude、Gemini之外,大部分开/闭源LLM蒸馏程度过高。
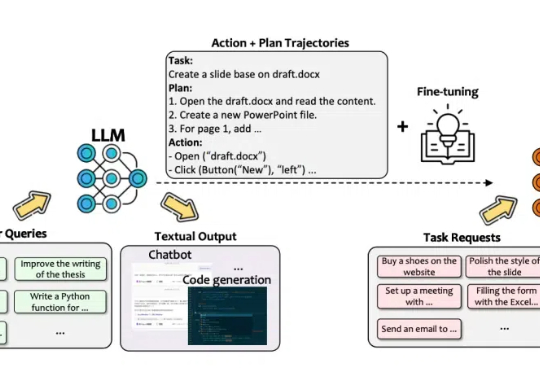
该技术报告的主要作者 Lu Wang, Fangkai Yang, Chaoyun Zhang, Shilin He, Pu Zhao, Si Qin 等均来自 Data, Knowledge, and Intelligence (DKI) 团队,为微软 TaskWeaver, WizardLLM, Windows GUI Agent UFO 的核心开发者。