
深度|Pytorch华人负责人押注复合AI:行业已经从依赖Scaling Law逐渐转向强调模型的推理能力
深度|Pytorch华人负责人押注复合AI:行业已经从依赖Scaling Law逐渐转向强调模型的推理能力我亲眼见证了数据量的爆炸式增长以及行业的巨额投入。当时就很明显,AI是推动这些数据增长背后的关键动力。那是一个非常有趣的时刻——Meta正在完成“移动优先”的过渡,开始迈向“AI 优先”。
来自主题: AI资讯
5596 点击 2025-01-21 13:22
 搜索
搜索
我亲眼见证了数据量的爆炸式增长以及行业的巨额投入。当时就很明显,AI是推动这些数据增长背后的关键动力。那是一个非常有趣的时刻——Meta正在完成“移动优先”的过渡,开始迈向“AI 优先”。
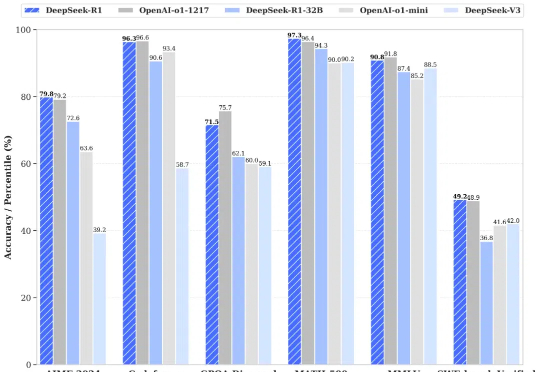
昨天晚上,DeepSeek 又开源了 DeepSeek-R1 模型(后简称 R1),再次炸翻了中美互联网: R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。 R1 上线 API,对用户开放思维链输出 R1 在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版,小模型则超越 OpenAI o1-mini
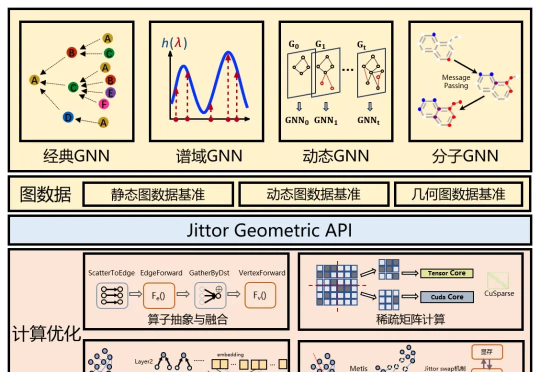
ittor Geometric 1.0是由中国人民大学与东北大学联合开发的图机器学习库,基于国产Jittor框架,高效灵活,可助力处理复杂图结构数据,性能优于同类型框架,支持多种前沿图神经网络模型,已开源供用户使用。
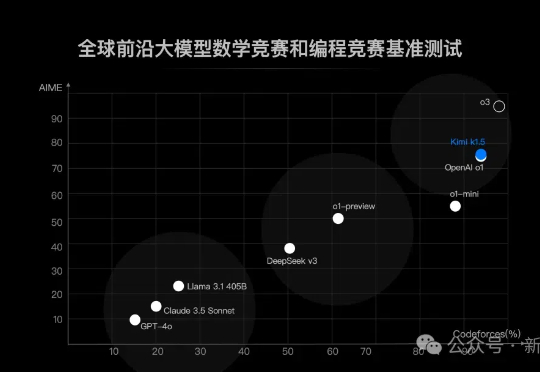
来了来了,月之暗面首个「满血版o1」来了!这是除OpenAI之外,首次有多模态模型在数学和代码能力上达到了满血版o1的水平。

AI具备的能力,本质上来自算法和训练大模型所用的数据,数据的数量和质量会对大模型起到决定性作用。此前OpenAI工作人员表示,因没有足够多的高质量数据,Orion项目(即GPT-5)进展缓慢。不得已之下,OpenAI招募了许多数学家、物理学家、程序员原创数据,用于训练大模型。
近期关于 scaling law 的讨论甚嚣尘上,很多观点认为 scale law is dead. 然而,我们认为,高质量的 “无监督” 数据才是 scaling law 的关键,尤其是教科书级别的高质量的知识语料。此外,尽管传统的语料快枯竭了,但是互联网上还有海量的视频并没有被利用起来,它们囊括了丰富的多种模态的知识,可以帮助 VLMs 更好好地理解世界。
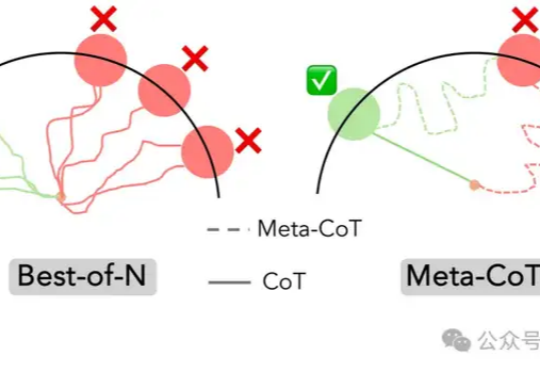
o1背后的推理原理,斯坦福和伯克利帮我们总结好了!

意图识别及其在智能设计中的应用
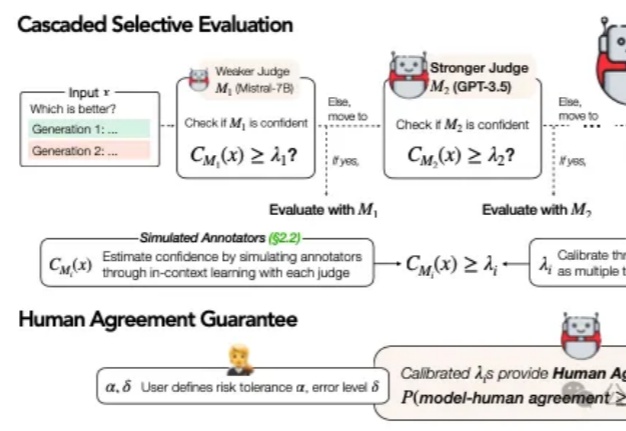
在当今AI技术迅猛发展的背景下,大语言模型(LLM)的评估问题已成为一个不可忽视的挑战。传统的做法是直接采用最强大的模型(如GPT-4)进行评估,这就像让最高法院的大法官直接处理所有交通违章案件一样,既不经济也不一定总能保证公正。
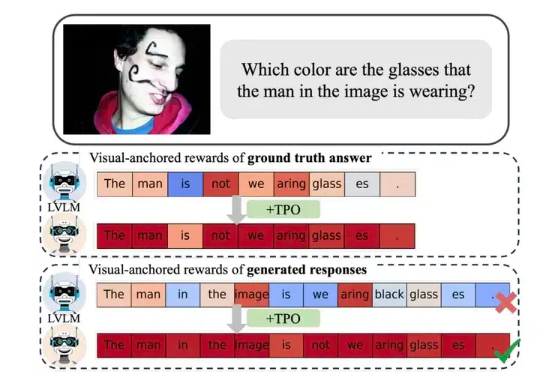
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。