细粒度对齐无需仔细标注了!淘天提出视觉锚定奖励,自我校准实现多模态对齐
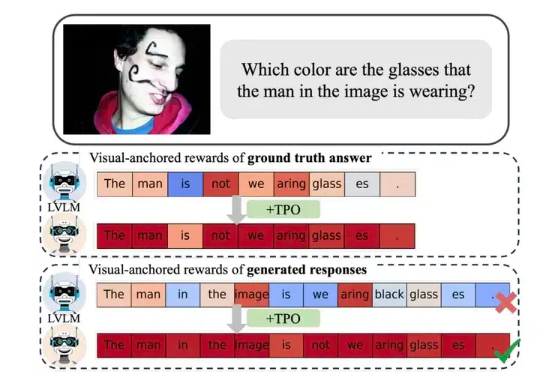
细粒度对齐无需仔细标注了!淘天提出视觉锚定奖励,自我校准实现多模态对齐近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。
来自主题: AI技术研报
7950 点击 2025-01-19 14:51
 搜索
搜索
近年来,视觉大模型(Large Vision Language Models, LVLMs)领域经历了迅猛的发展,这些模型在图像理解、视觉对话以及其他跨模态任务中展现出了卓越的能力。然而,随着 LVLMs 复杂性和能力的增长,「幻觉现象」的挑战也日益凸显。

2024又是AI精彩纷呈的一年。LLM不再是AI舞台上唯一的主角。随着预训练技术遭遇瓶颈,GPT-5迟迟未能问世,从业者开始从不同角度寻找突破。以o1为标志,大模型正式迈入“Post-Training”时代;开源发展迅猛,Llama 3.1首次击败闭源模型;中国本土大模型DeepSeek V3,在GPT-4o发布仅7个月后,用 1/10算力实现了几乎同等水平。

昨天,我们报道了一个行业猜想,说是 OpenAI 和 Anthropic 等前沿大模型公司可能已经训练出了下一代大模型,但由于它们的使用成本过高,所以短时间内根本不会被放出来。

大型语言模型(LLMs)能够解决研究生水平的数学问题,但今天的搜索引擎却无法准确理解一个简单的三词短语。

一个新框架,让Qwen版o1成绩暴涨: 在博士级别的科学问答、数学、代码能力的11项评测中,能力显著提升,拿下10个第一! 这就是人大、清华联手推出的最新「Agentic搜索增强推理模型框架」Search-o1的特别之处。
对于 LLM,推理时 scaling 是有效的!这一点已经被近期的许多推理大模型证明:o1、o3、DeepSeek R1、QwQ、Step Reasoner mini……
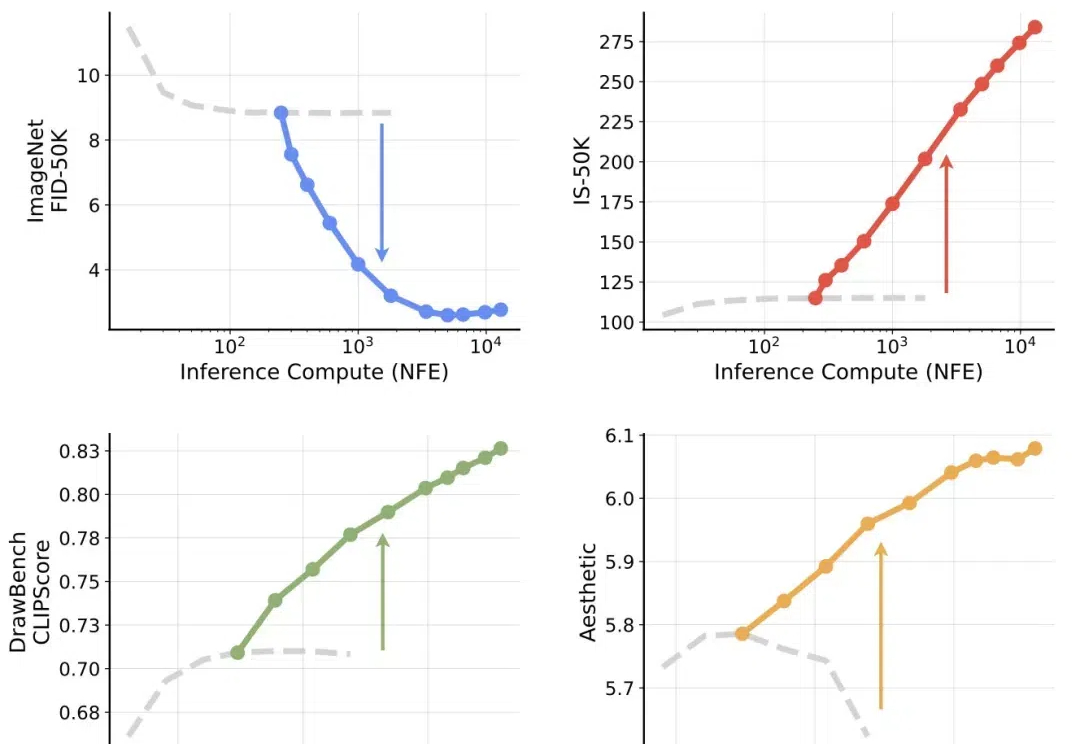
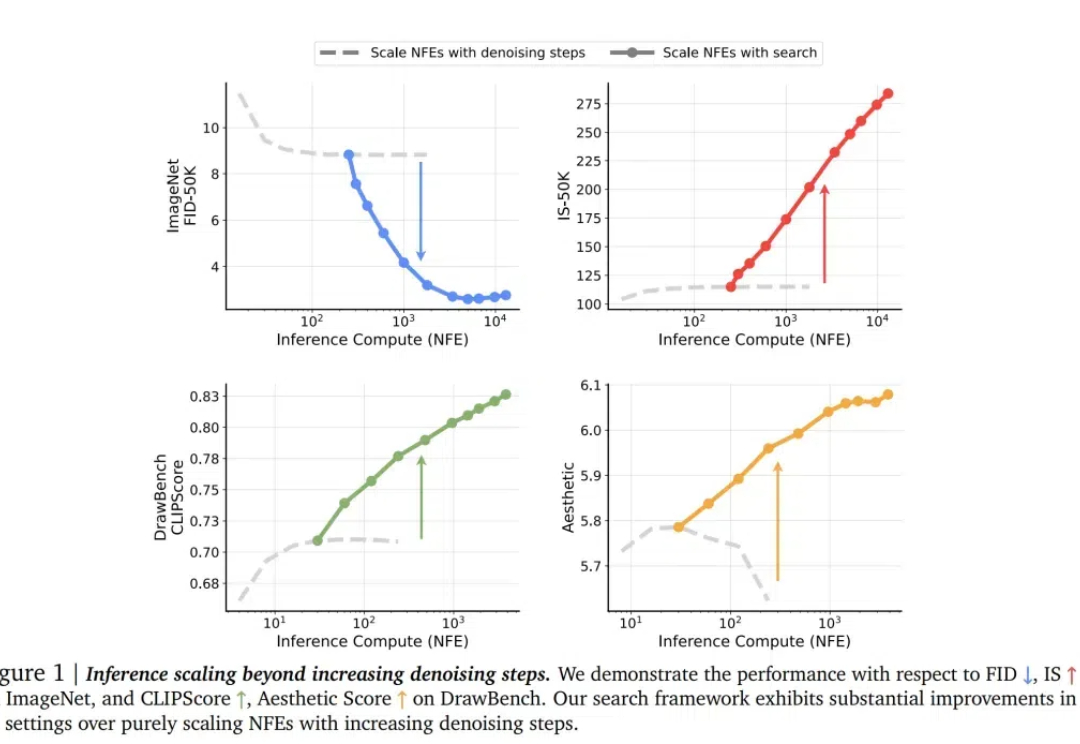
划时代的突破来了!来自NYU、MIT和谷歌的顶尖研究团队联手,为扩散模型开辟了一个全新的方向——测试时计算Scaling Law。其中,谢赛宁高徒为共同一作。
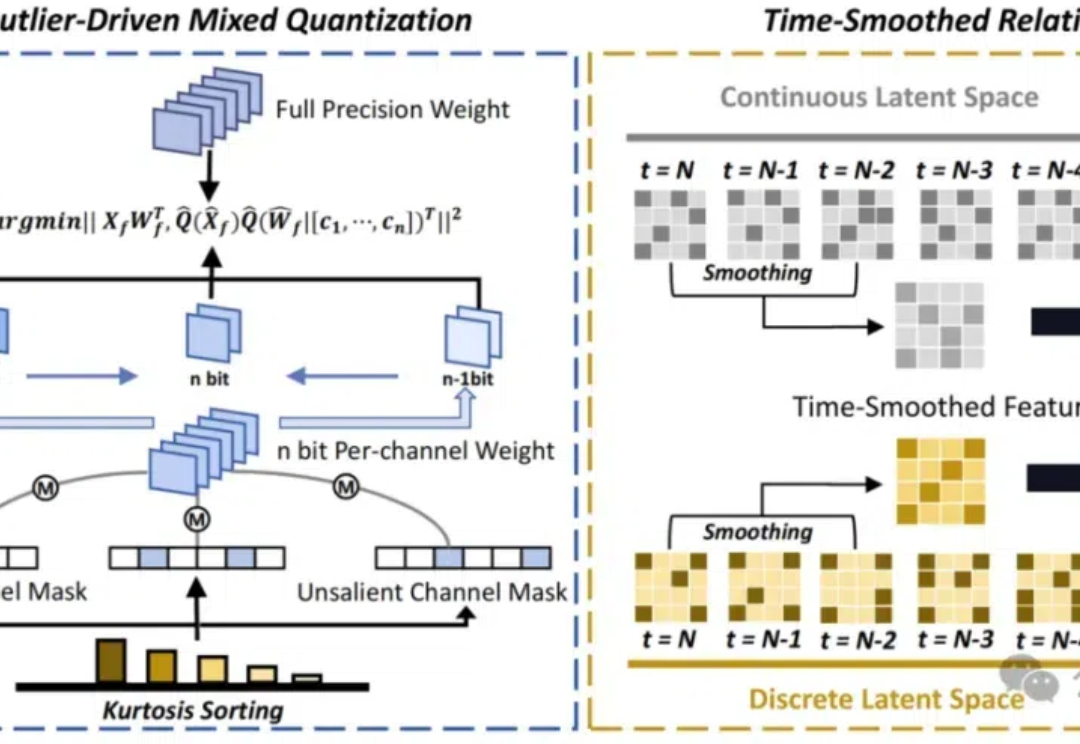
降低扩散模型生成的计算成本,性能还保持在高水平! 最新研究提出一种用于极低位差分量化的混合精度量化方法。

模型安全和可靠性、系统整合和互操作性、用户交互和认证…… 当“多模态”“跨模态”成为不可阻挡的AI趋势时,多模态场景下的安全挑战尤其应当引发产学研各界的注意。

清华大学团队在强化学习领域取得重大突破