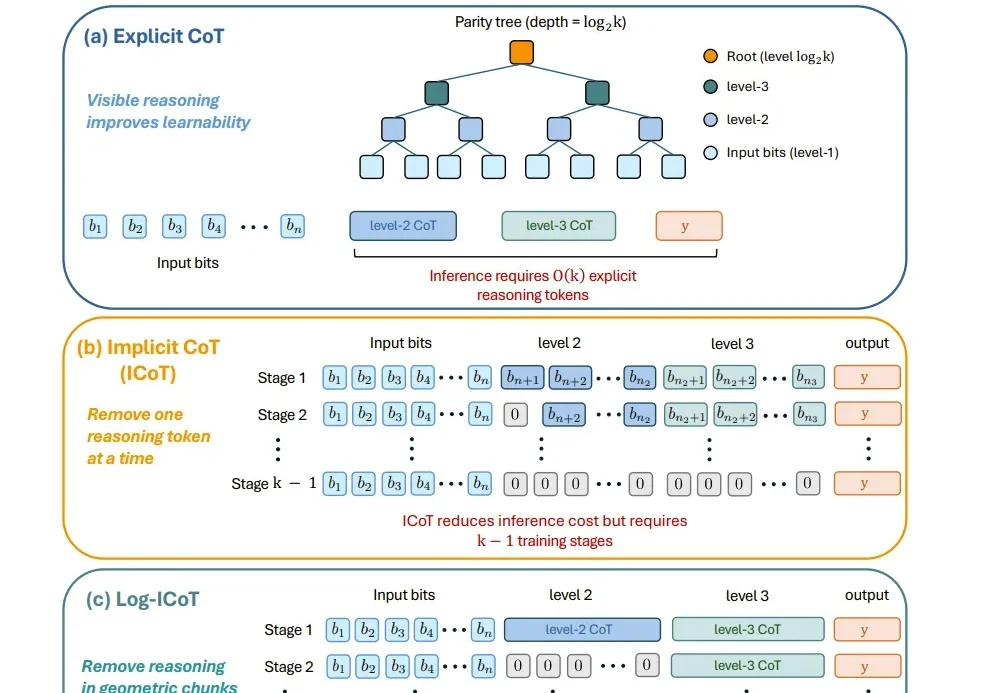
AI真能学会心算?隐式思维链首次得到理论证明,Stuart Russell参与
AI真能学会心算?隐式思维链首次得到理论证明,Stuart Russell参与过去一年,AI 推理模型的使用成本让不少开发者叫苦。
来自主题: AI技术研报
7328 点击 2026-06-08 09:49
 搜索
搜索
过去一年,AI 推理模型的使用成本让不少开发者叫苦。
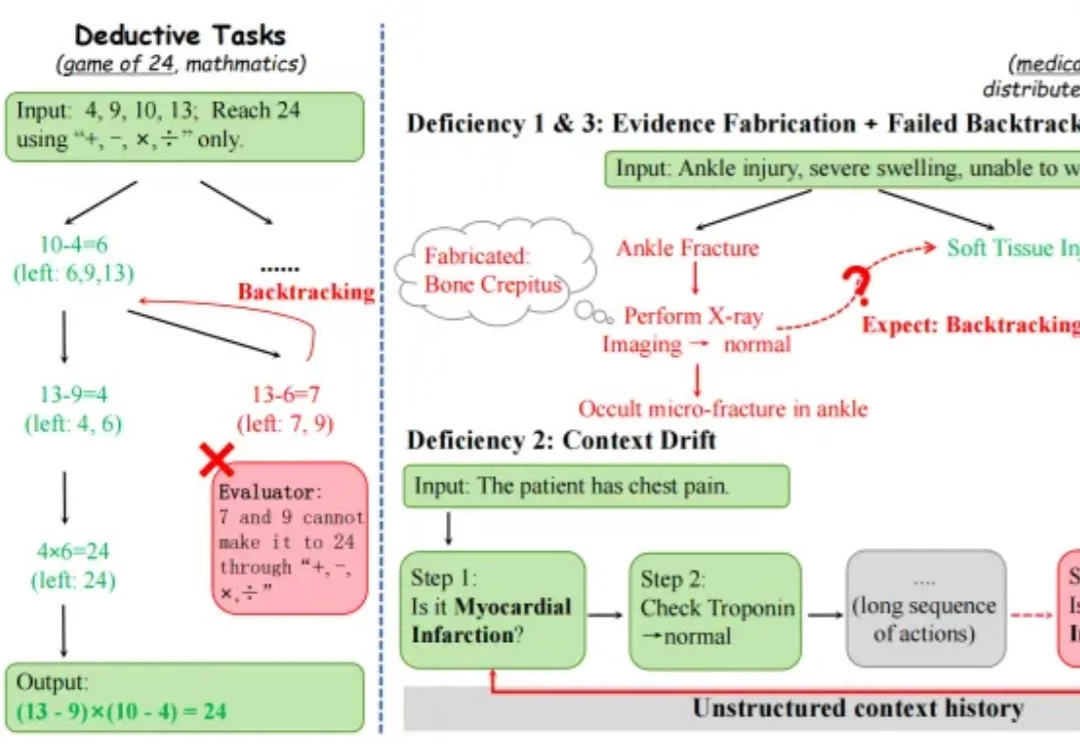
近年来,大语言模型在数学、代码等任务上的表现不断刷新上限,但到了医疗诊断、故障排查这类真实世界任务里,真正困难的是让多个智能体在不确定的动态环境中持续协作推理。
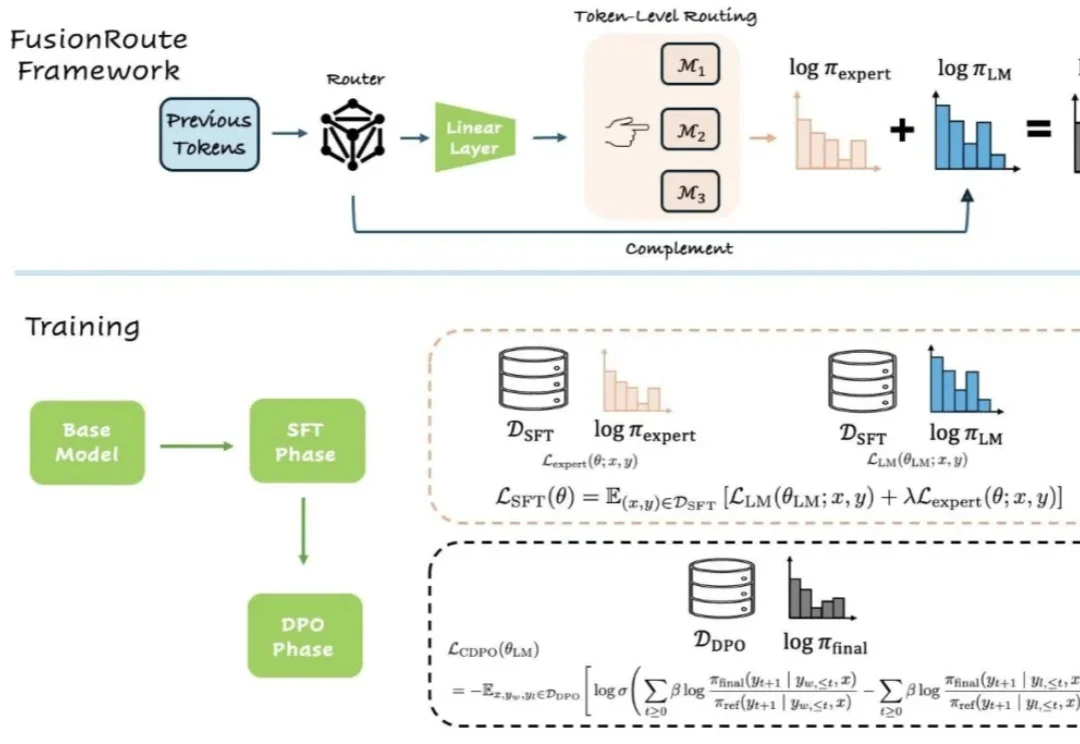
近年来,大语言模型能力的提升,已不再仅仅依赖于更大的模型规模或更多的训练数据。越来越多的研究开始探索另一条路径:通过多个专家模型的协作来完成生成任务。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。

近日,来自清华大学智能产业研究院(AIR)的团队联合北京智源研究院(BAAI)、北京大学、南京大学等机构构建了一个基准:GeoCodeBench。这是一个面向 3D 几何计算机视觉的 PhD 级 coding benchmark,

早在 2023 年大模型快速发展期,哈工大张民教授立知大模型团队已开展多模态大模型驱动的视频内容创作智能体研究,并全球首发开源了电影制作智能体 FilmAgent 与动画片生成智能体 Anim-Director,受到国内外智能体研究者与文艺创作者的广泛关注。
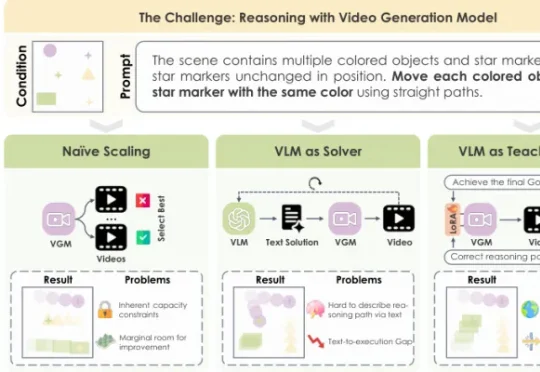
怎么让VGM学会按规则推理?过去主要有两条路。两条路,一个不动模型,一个只写文字,都没真正解决“执行”问题。为此,城大×快手可灵提出了第三条路:VLM-as-Teacher。
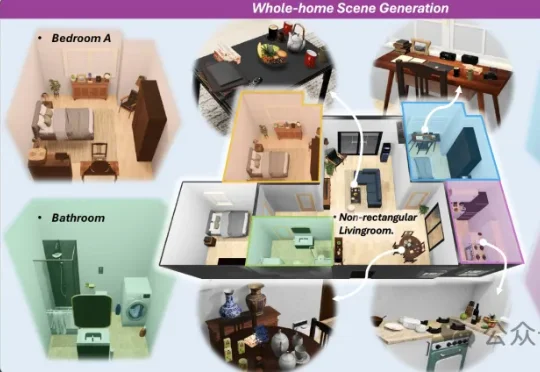
一觉睡醒,具身智能公司竟然也开始搞房地产了?!刚刚,大晓机器人联合港中文MMLab发布了一个新项目——Kairos-Homeworld,全球首个实现全屋三维生成与物体级全交互的统一框架。
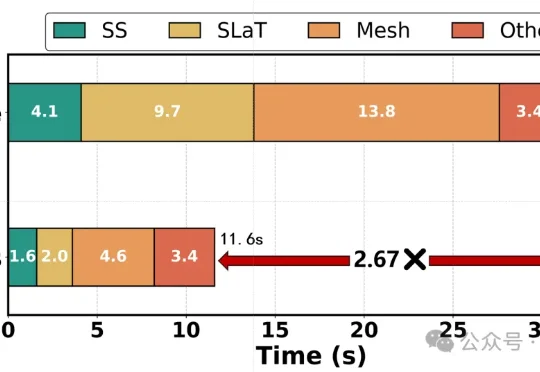
来自中国科学院计算技术研究所、ETH Zurich等机构的研究者提出了Fast-SAM3D。该方法直接面向SAM3D的推理链路做训练无关加速,在最大程度保持重建质量的同时,将单对象生成提速最高2.67倍,场景生成提速最高2.01倍。

6月5日,腾讯云AI产业应用大会上,腾讯集团高级执行副总裁汤道生和首席AI科学家姚顺雨同台对谈。这是姚顺雨加入腾讯后第一次在公司活动中公开亮相。这场对谈的主题叫《腾讯AI的下半场》。2025年4月,姚顺雨曾在个人博客发表《The Second Half》一文,在技术社区广泛传播。文章的核心判断是:AI正站在中场分界线上,上半场的核心在于训练方法和模型的突破