解锁Agent Swarm新潜力,openJiuwen又一力作:多智能体流网络
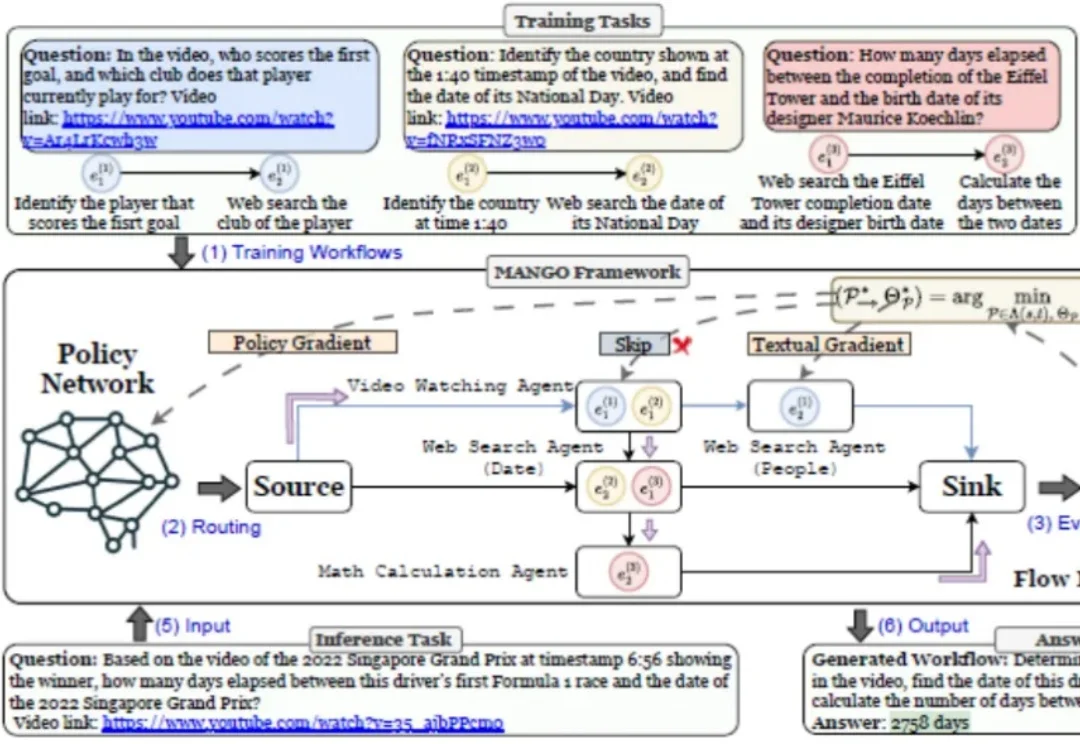
解锁Agent Swarm新潜力,openJiuwen又一力作:多智能体流网络多智能体协作对于解决复杂问题虽然具有巨大优势,但是其架构本质上易出现错误传播,因为由不正确的工作流生成或单智能体幻觉输出引起的错误会沿着协作链蔓延,影响最终结果。
来自主题: AI技术研报
10668 点击 2026-06-09 09:59
 搜索
搜索
多智能体协作对于解决复杂问题虽然具有巨大优势,但是其架构本质上易出现错误传播,因为由不正确的工作流生成或单智能体幻觉输出引起的错误会沿着协作链蔓延,影响最终结果。
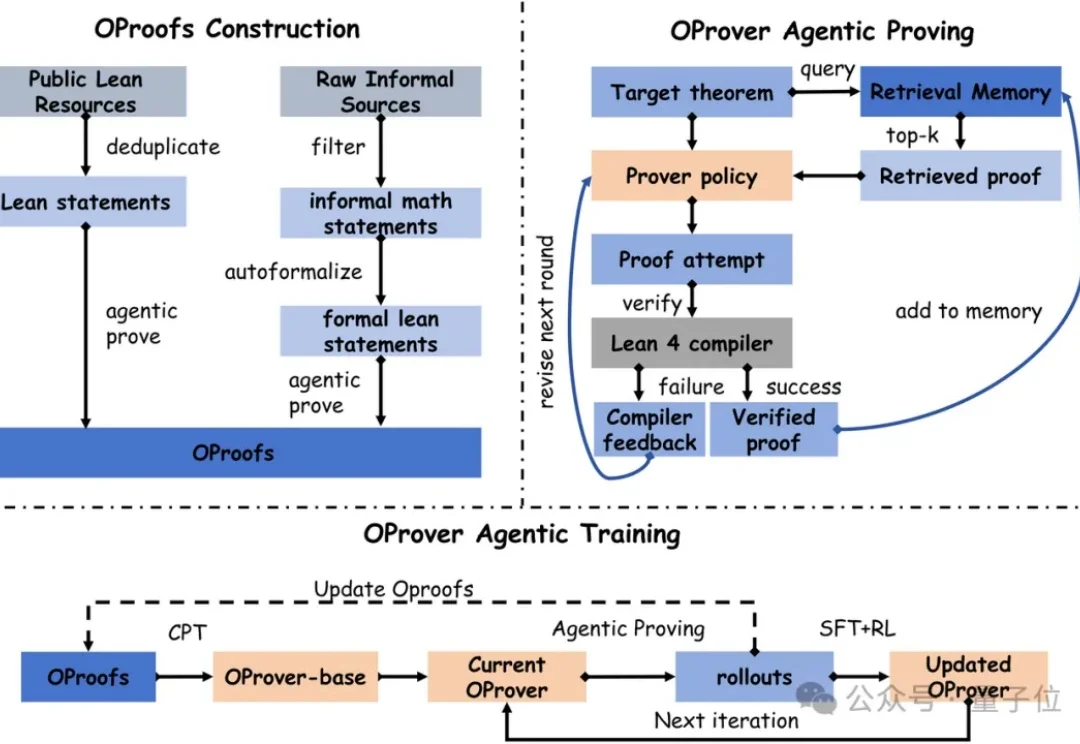
形式化定理证明,一直是LLM公认最严苛的推理试金石,每一步推导都必须通过Lean 4内核的机器验证。

一年前,行业还在为“从自动补全到 Agent”的进化感到兴奋。然而一年过去,我们不难发现单纯靠“Vibe Coding”和“Prompt 调优”,面对非确定性模型带来的风险和成本问题,显然无法撑起企业级软件开发。
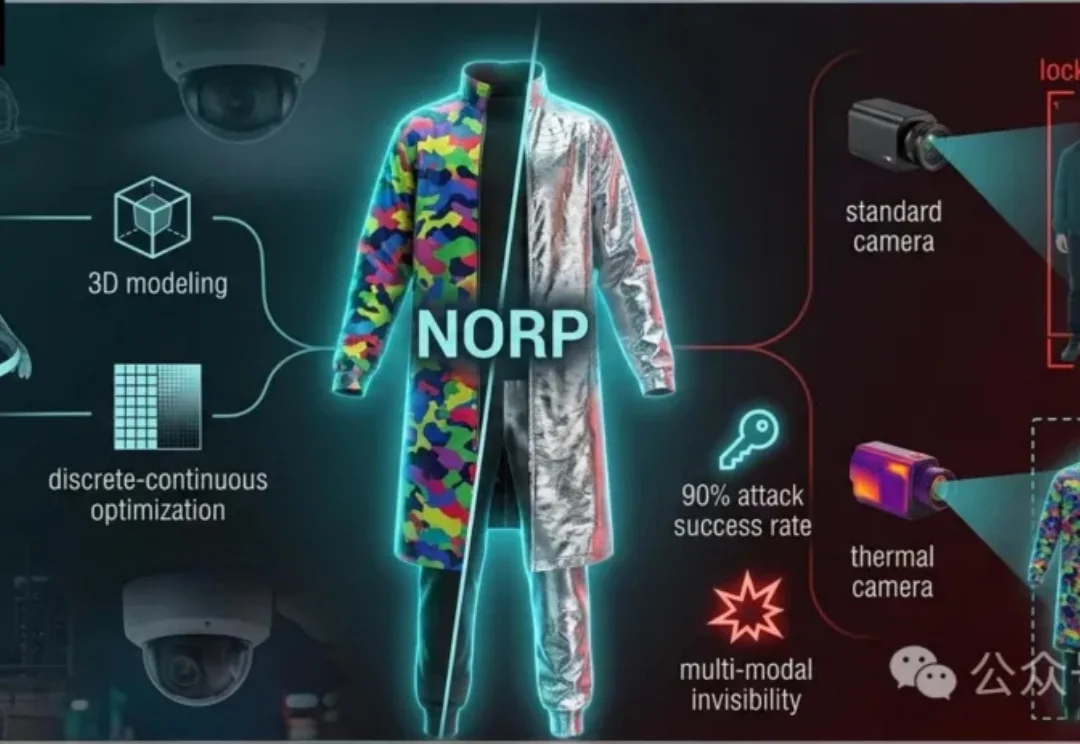
清华大学提出一种新型物理对抗方法,利用特殊服装同时干扰可见光和热成像检测。这种服装通过非重叠设计和三维建模优化,可有效躲避RGB-T检测器,促进系统安全性研究。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。
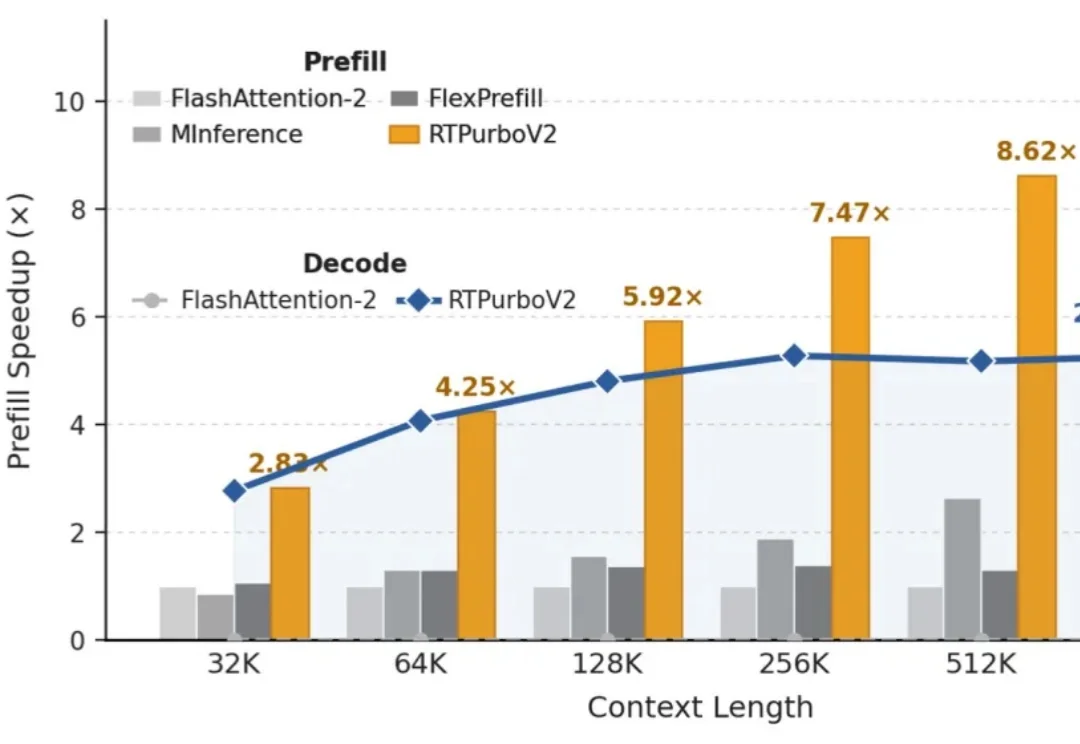
“Full Attention 正在被遗忘”

2K 图像 210ms 解码,4K 细节直接生成,传统「解码 + 超分」流水线可能要被重写了。

不扩上下文窗口、不换骨干架构、不做全参数微调 —— 只需要一个 8×8 的在线状态矩阵,就能让冻结的 Transformer 拥有真正的长期记忆。

大模型开始进入理论计算机科学最核心的问题之一:算法设计。

北大彭宇新团队提出「美学照片重构」新任务,从摄影教学视频中自动构建数据集AesRecon,并开发两阶段模型AesFormer,通过优化构图、视角与人物姿态,提升照片的美感与艺术表现力。