
BEV杀入具身智能:跨维智能把机器人数据带上Scaling快车道
BEV杀入具身智能:跨维智能把机器人数据带上Scaling快车道具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。
来自主题: AI技术研报
9422 点击 2026-06-10 14:44
 搜索
搜索
具身智能现在面临的问题,和自动驾驶几年前的困境非常相似。
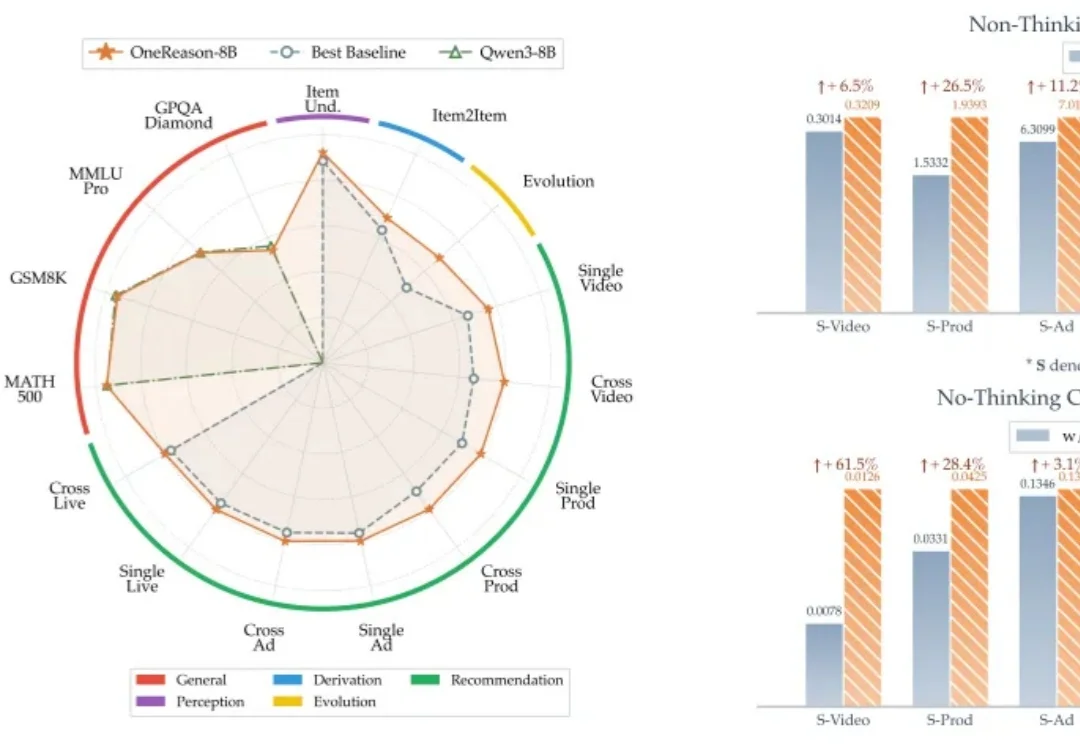
推荐系统的过去十年,本质是把 "用户 - 物料" 的统计共现挖到极致 —— 从协同过滤、深度模型,到生成式 OneRec 系列,每一代都在让 "记忆" 更精细、参数更大、序列更长,也让 Scaling 这件事在工业级推荐系统上跑通,持续释放算力红利。

Transformer 依托强大的建模能力和 Scaling 效率在推荐领域被广泛应用于超长序列建模和生成式推荐等方向,
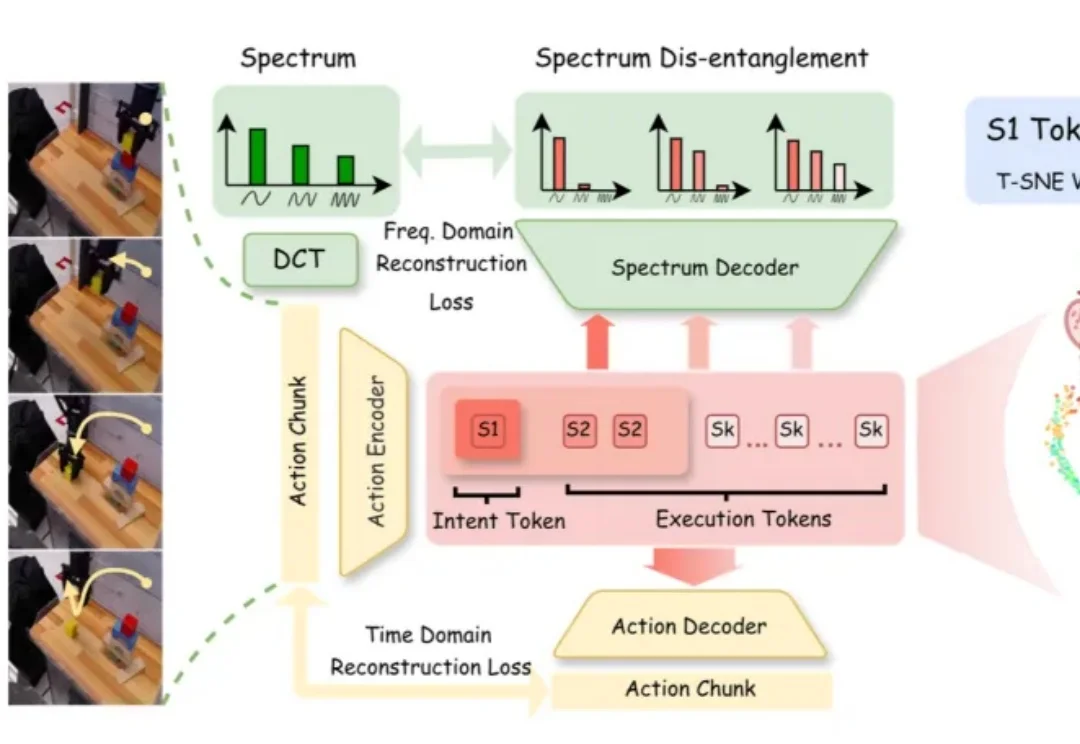
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。

过去两年,大模型写代码已经不再新鲜。从代码补全到 GitHub issue 修复,从竞赛编程到仓库级软件工程,人们习惯用一个简单标准评估 coding agent:代码能不能写对?测试能不能通过?
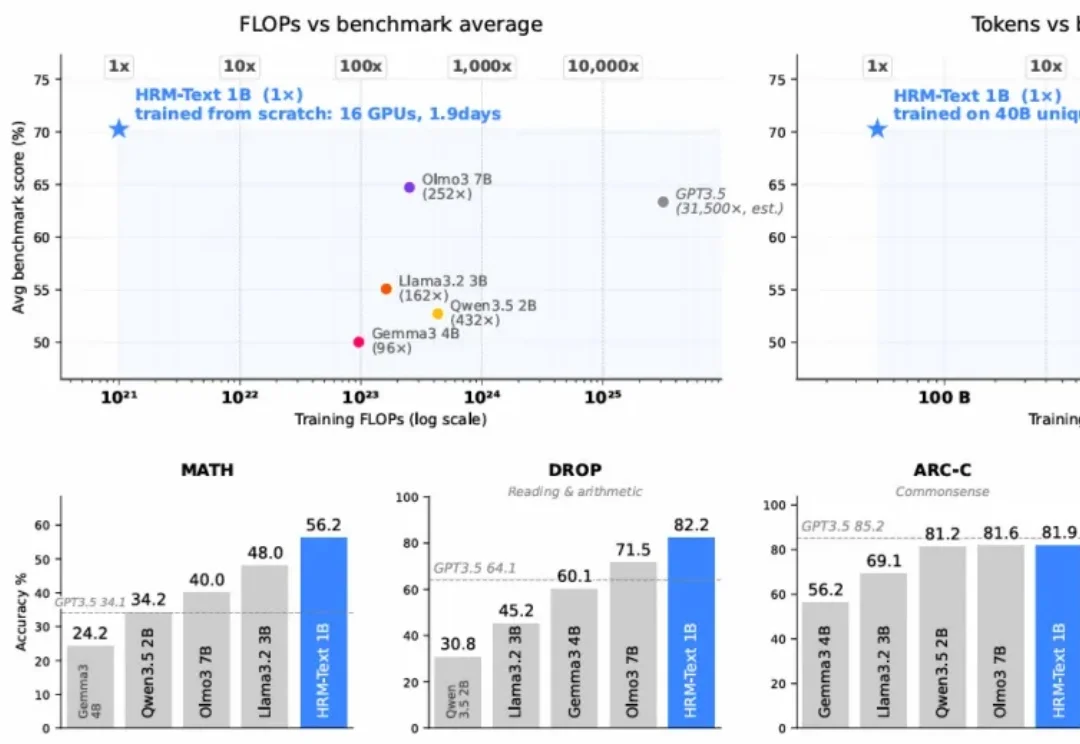
一个约 1B 参数的模型,在 MATH 上拿到 56.2,在 GSM8K 上拿到 84.5,在 ARC-Challenge 上拿到 81.9。训练成本约 1500 美元,16 块 H100 跑了不到两天。

Meta 发布了一项令人震撼的研究工作 VLM³,首次揭示了三维视觉学习的 Bitter Lesson:标准的视觉语言模型 + scale 数据就是最简单有效的范式,针对特定任务的架构、损失函数以及数据增强的设计,甚至是 regression 的 formulation,均不是三维视觉学习的必要条件。
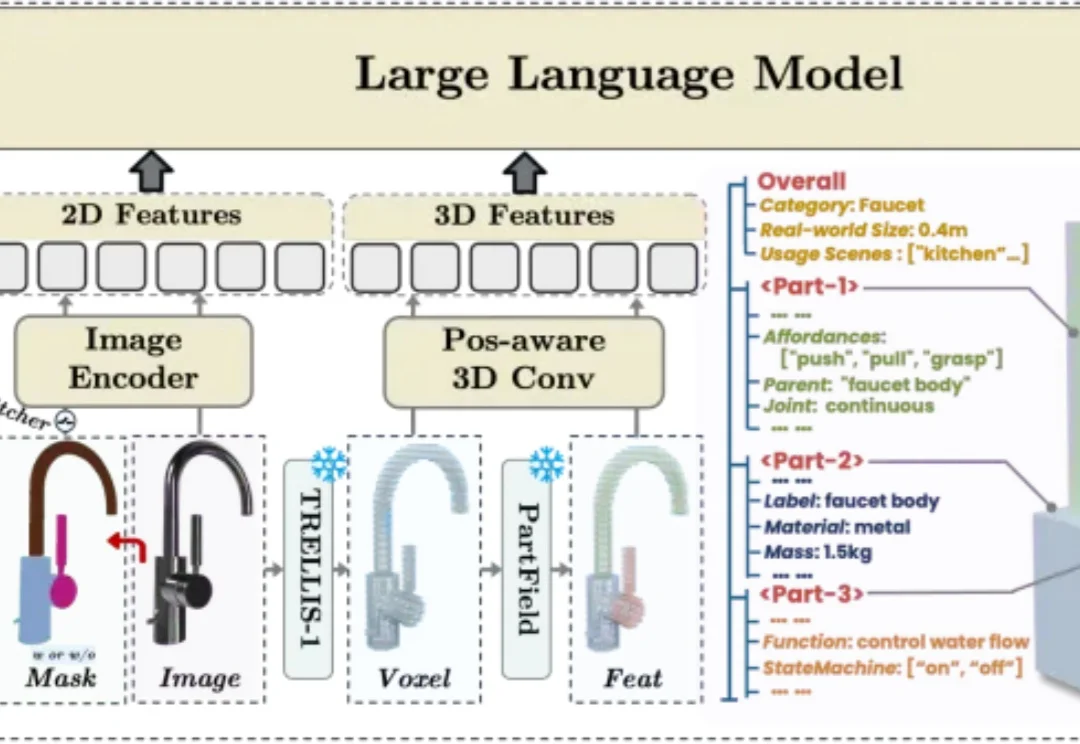
在交互式虚拟世界和具身智能快速发展的今天,高质量 3D 资产已经不再只是 “看起来像” 就足够。一个柜门不仅要有柜门的外观,还需要知道绕哪条轴旋转;一个按钮不仅要有按钮的形状,还需要具备 “按下 / 弹起” 的状态;一个抽屉不仅要有完整几何,还需要拥有滑动方向、运动范围、材质和质量等物理属性。该研究已被 ICML 2026 接收。
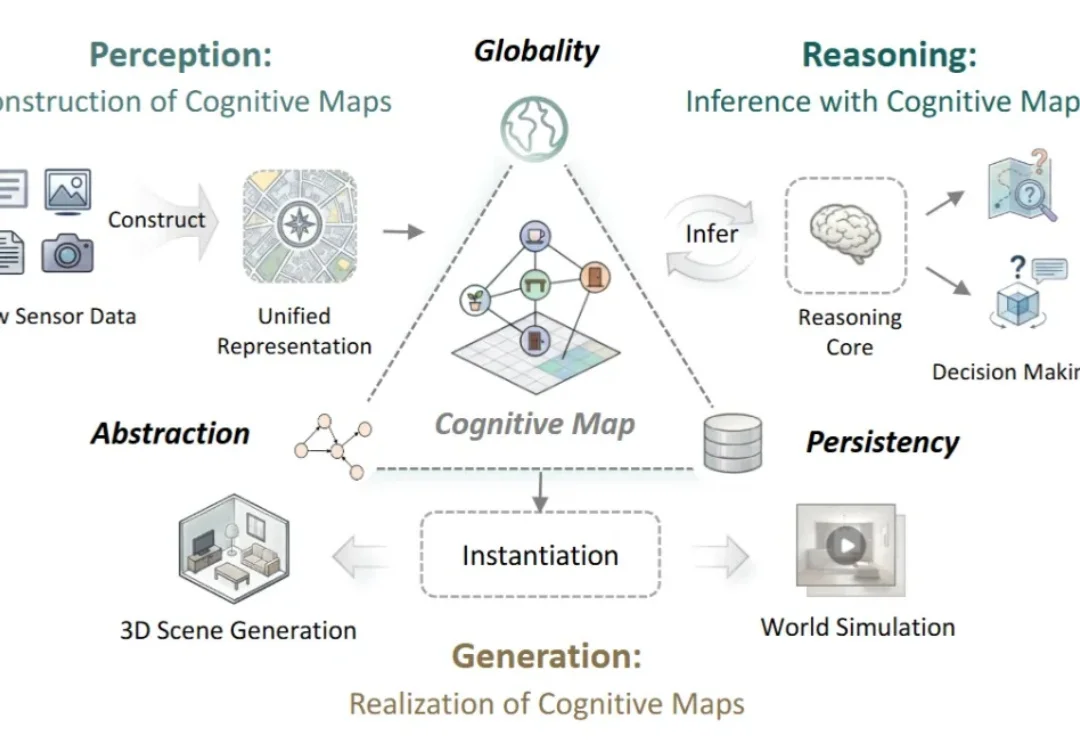
AI 已经能看懂图像、生成场景,甚至在虚拟环境中规划行动。

近年来,文生图模型的能力快速提升。从 Stable Diffusion 到 FLUX、Qwen-Image,扩散模型已经能够生成高质量图像,也能处理越来越复杂的文本提示。