
1/10训练数据超越GPT-4o!清华等提出隐式过程奖励模型PRIME,在线刷SOTA
1/10训练数据超越GPT-4o!清华等提出隐式过程奖励模型PRIME,在线刷SOTA1/10训练数据激发高级推理能力!近日,来自清华的研究者提出了PRIME,通过隐式奖励来进行过程强化,提高了语言模型的推理能力,超越了SFT以及蒸馏等方法。
来自主题: AI技术研报
4495 点击 2025-01-08 11:12
 搜索
搜索
1/10训练数据激发高级推理能力!近日,来自清华的研究者提出了PRIME,通过隐式奖励来进行过程强化,提高了语言模型的推理能力,超越了SFT以及蒸馏等方法。

陈丹琦团队又带着他们的降本大法来了—— 数据砍掉三分之一,大模型性能却完全不减。 他们引入了元数据,加速了大模型预训练的同时,也不增加单独的计算开销。
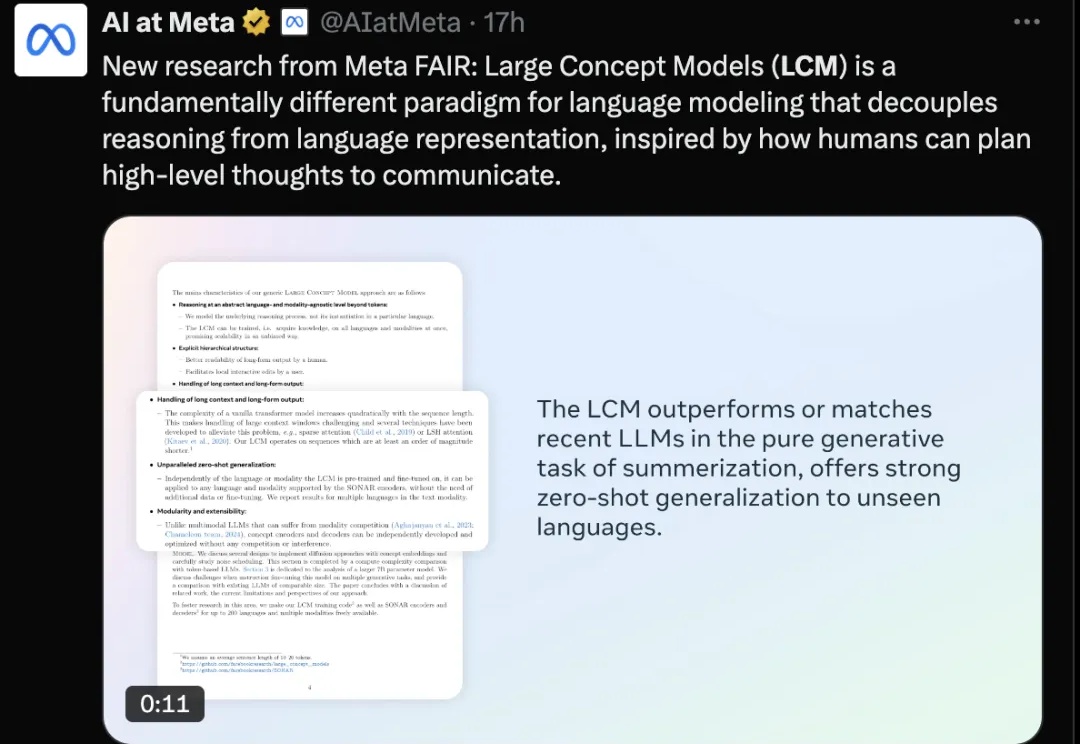
Meta提出大概念模型,抛弃token,采用更高级别的「概念」在句子嵌入空间上建模,彻底摆脱语言和模态对模型的制约。

游戏本质上是虚拟模拟,而虚拟模拟在过去的几十年里,一直是为了好玩而设计的。但是,我们将越来越多地看到它们在现实世界中用于各种用例,无论是培训、学习和发展,还是用于机器人和其他自主系统的训练场,亦或是可视化,来让人们实时看到事物变得栩栩如生。
智能涌现独家获悉:零一万物裁撤预训练算法团队和Infra团队后,阿里通义、智能云团队给出了offer。

流媒体平台爱奇艺已向上海市徐汇区人民法院正式提起诉讼,指控国内AI初创企业MiniMax在AI模型训练及内容生成流程中,涉嫌侵犯其版权,导致生成的内容构成了对爱奇艺版权的侵犯。
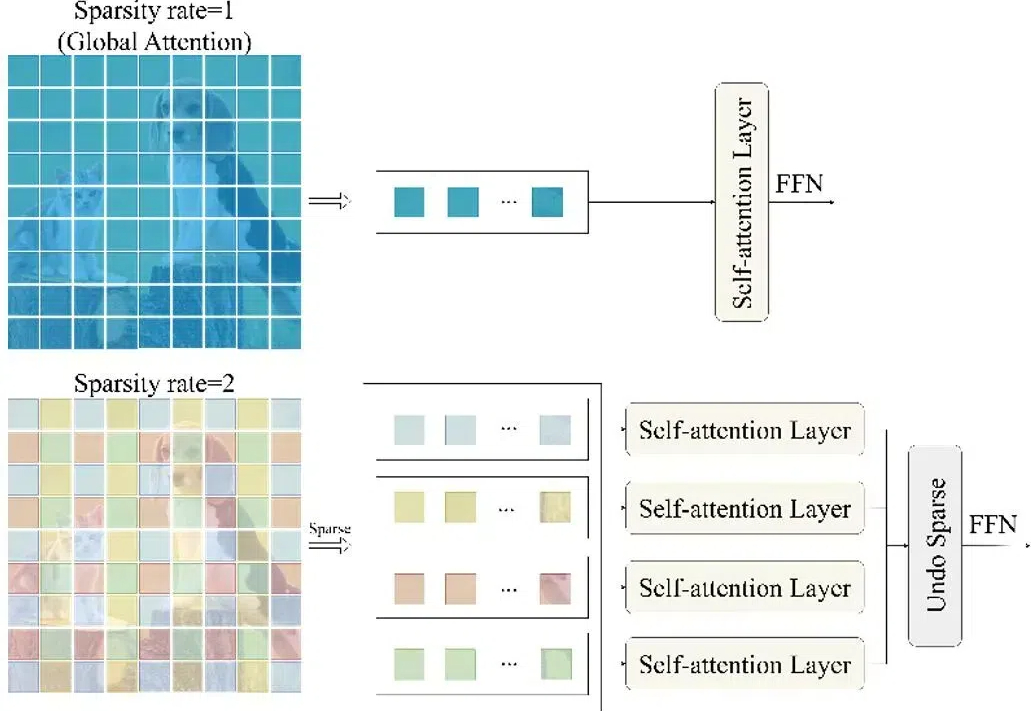
随着图像编辑工具和图像生成技术的快速发展,图像处理变得非常方便。然而图像在经过处理后不可避免的会留下伪影(操作痕迹),这些伪影可分为语义和非语义特征。

大模型浪潮下,AI与其背后的通信网络存在密不可分的联系,可以总结为Network for AI和AI for Network两层关系—— 我们用网络加速AI训练推理,通过AI手段让网络变得更加安全可靠。
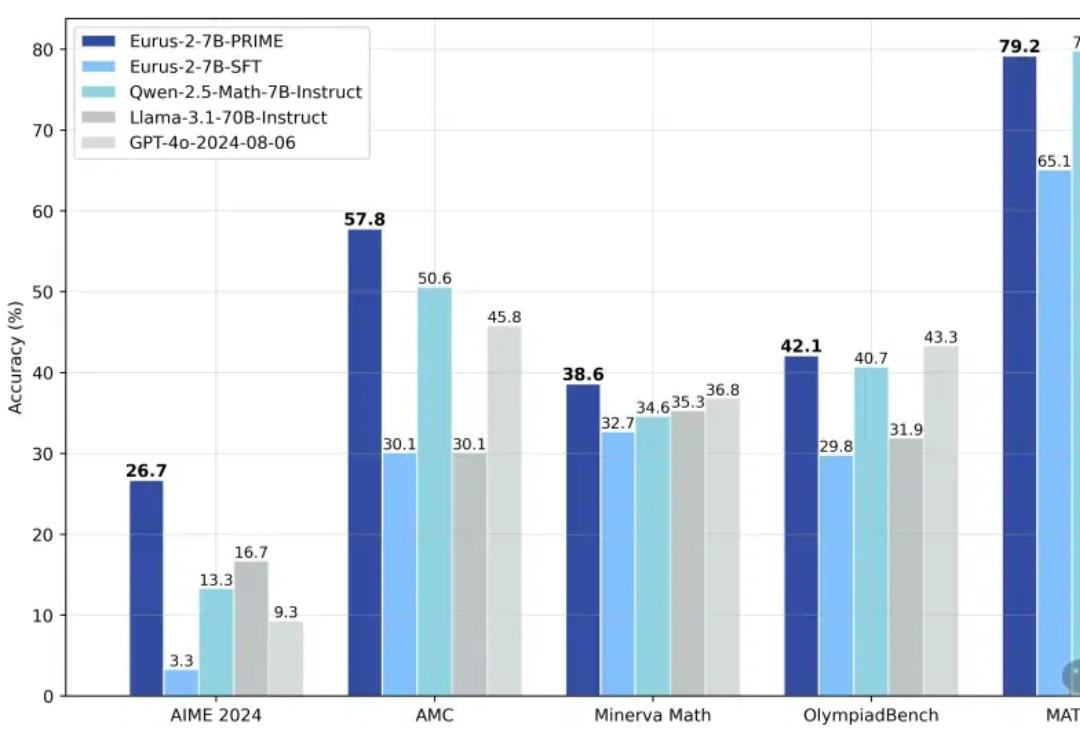
OpenAI o1和o3模型的发布证明了强化学习能够让大模型拥有像人一样的快速迭代试错、深度思考的高阶推理能力,在基于模仿学习的Scaling Law逐渐受到质疑的今天,基于探索的强化学习有望带来新的Scaling Law。

2020年2月,数据标注员作为人工智能训练师的一个工种,被正式纳入国家职业分类目录。短短几年,这个劳动力需求量巨大的行业,迅速在一些中小城市落地生根。