
真机数据白采了?银河通用具身VLA大模型已充分泛化,预训练基于仿真合成大数据!
真机数据白采了?银河通用具身VLA大模型已充分泛化,预训练基于仿真合成大数据!今天,银河通用机器人发布了端到端具身抓取基础大模型「GraspVLA」,全球第一个预训练完全基于仿真合成大数据的具身大模型,展现出了比OpenVLA、π0、RT-2、RDT等模型更全面强大的泛化性和真实场景实用潜力。
来自主题: AI技术研报
6832 点击 2025-01-10 12:23
 搜索
搜索
今天,银河通用机器人发布了端到端具身抓取基础大模型「GraspVLA」,全球第一个预训练完全基于仿真合成大数据的具身大模型,展现出了比OpenVLA、π0、RT-2、RDT等模型更全面强大的泛化性和真实场景实用潜力。
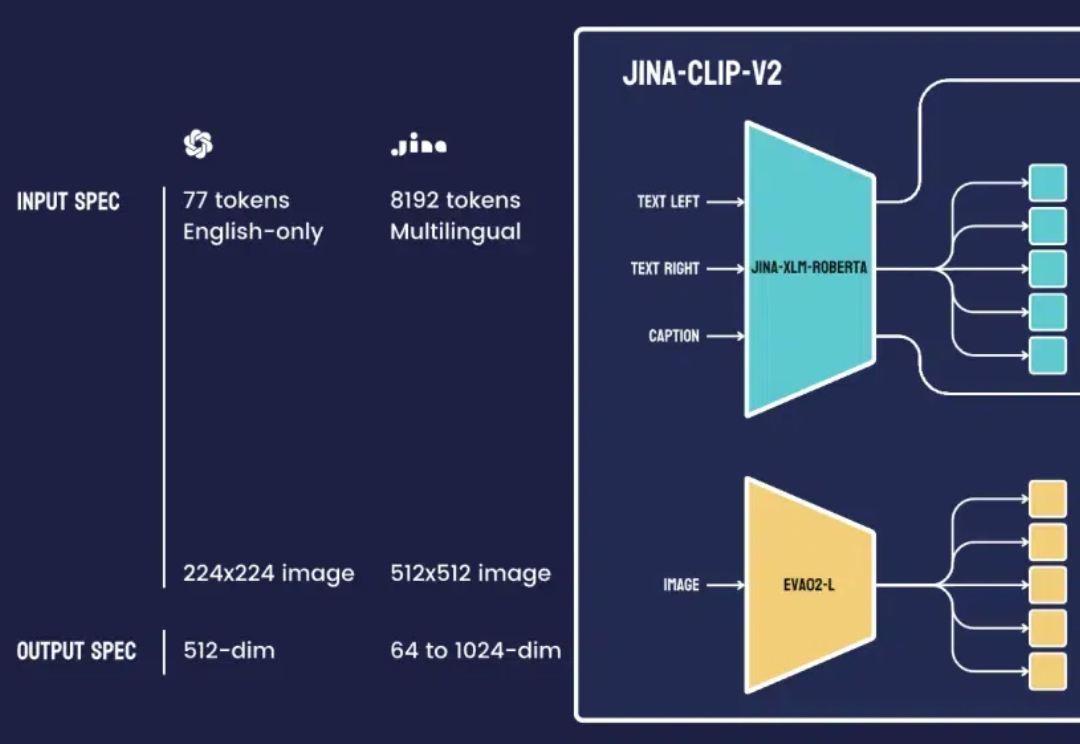
最近,我们团队的一位工程师在研究类 ColPali 模型时,受到启发,用新近发布的 jina-clip-v2 模型做了个颇具洞察力的可视化实验。
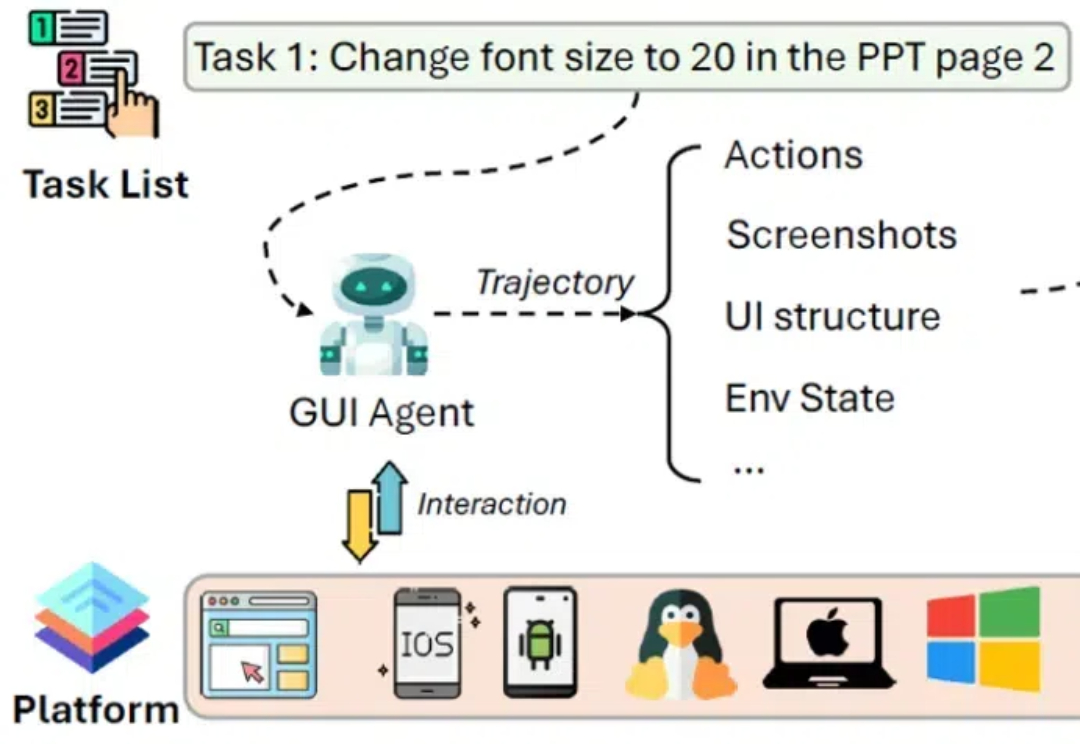
图形用户界面(Graphical User Interface, GUI)作为数字时代最具代表性的创新之一,大幅简化了人机交互的复杂度。
不知这是极大地提高了网站的安全性,还是成功地把人类拒绝于网站“门外”? 在使用 App、网页应用时,你有没有遇到过这样的情况:一个验证窗口突然跳出来,要求你完成某个任务,证明“你是人类,而不是机器人”?
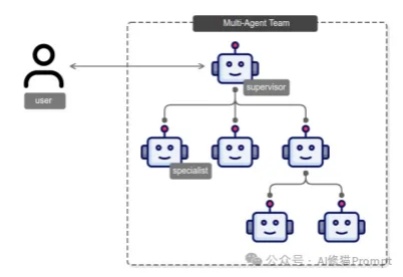
随着大语言模型(LLM)技术的快速发展,单一AI智能体已经展现出强大的问题解决能力。然而,在面对复杂的企业级应用场景时,单一智能体的能力往往显得捉襟见肘。

老婆饼里没有老婆,夫妻肺片里没有夫妻,RLHF 里也没有真正的 RL。在最近的一篇博客中,德克萨斯大学奥斯汀分校助理教授 Atlas Wang 分享了这样一个观点。

因为 V3 版本开源模型的发布,DeepSeek 又火了一把,而且这一次,是外网刷屏。 训练成本估计只有 Llama 3.1 405B 模型的 11 分之一,后者的效果还不如它。

大厂为什么追求大模型? 昨天有提到,为什么要研究语言模型。
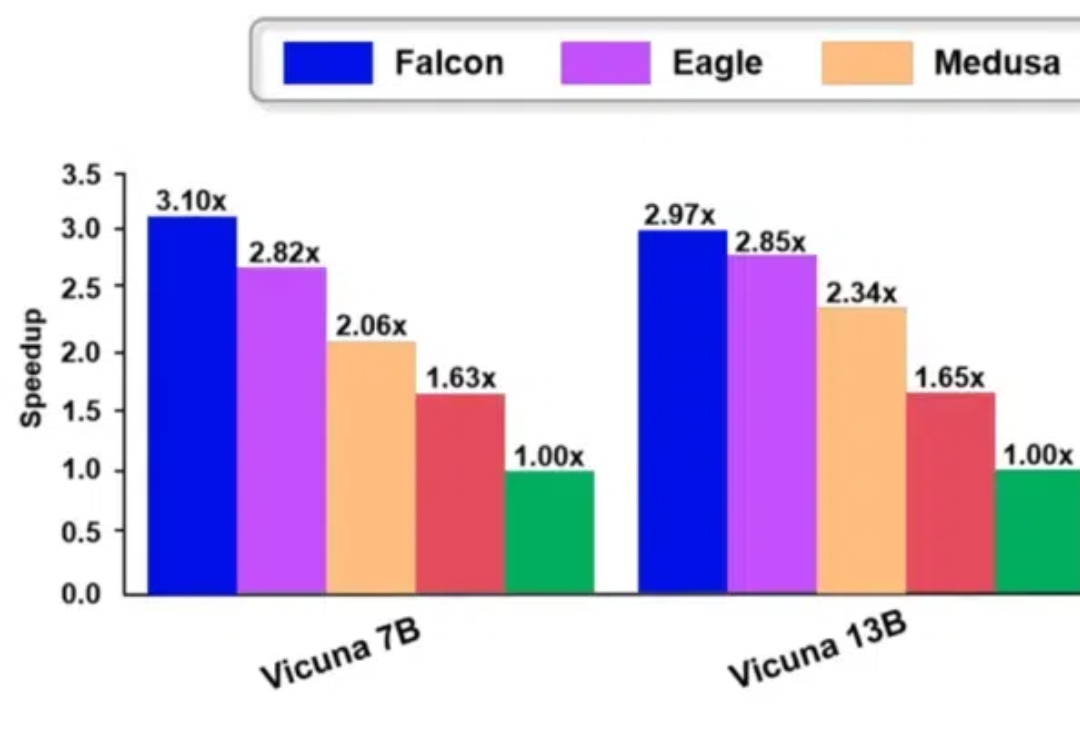
Falcon 方法是一种增强半自回归投机解码框架,旨在增强 draft model 的并行性和输出质量,以有效提升大模型的推理速度。Falcon 可以实现约 2.91-3.51 倍的加速比,在多种数据集上获得了很好的结果,并已应用到翼支付多个实际业务中。
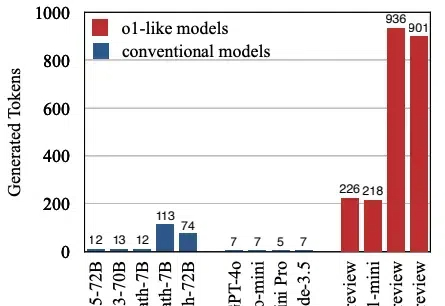
本文将介绍首个关于 o1 类长思维链模型过度思考现象。该工作由腾讯 AI Lab 与上海交通大学团队共同完成。