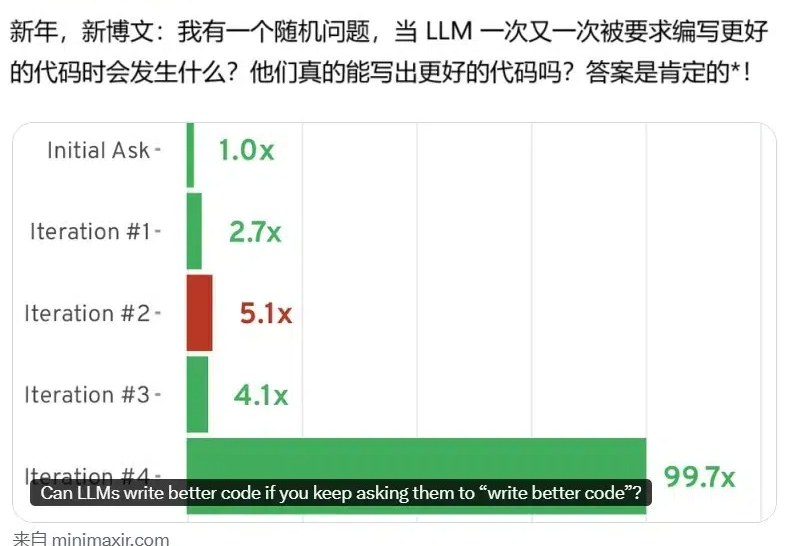
不停PUA大模型「写更好点」,无需其它花哨技术就能让AI代码水平暴增
不停PUA大模型「写更好点」,无需其它花哨技术就能让AI代码水平暴增AI 的编程能力已经得到了证明,但还并不完美。近日,BuzzFeed 的资深数据科学家 Max Woolf 发现,如果通过提示词不断要求模型写更好的代码(write better code),AI 模型还真能写出更好的代码!
来自主题: AI资讯
9481 点击 2025-01-12 10:51
 搜索
搜索
AI 的编程能力已经得到了证明,但还并不完美。近日,BuzzFeed 的资深数据科学家 Max Woolf 发现,如果通过提示词不断要求模型写更好的代码(write better code),AI 模型还真能写出更好的代码!
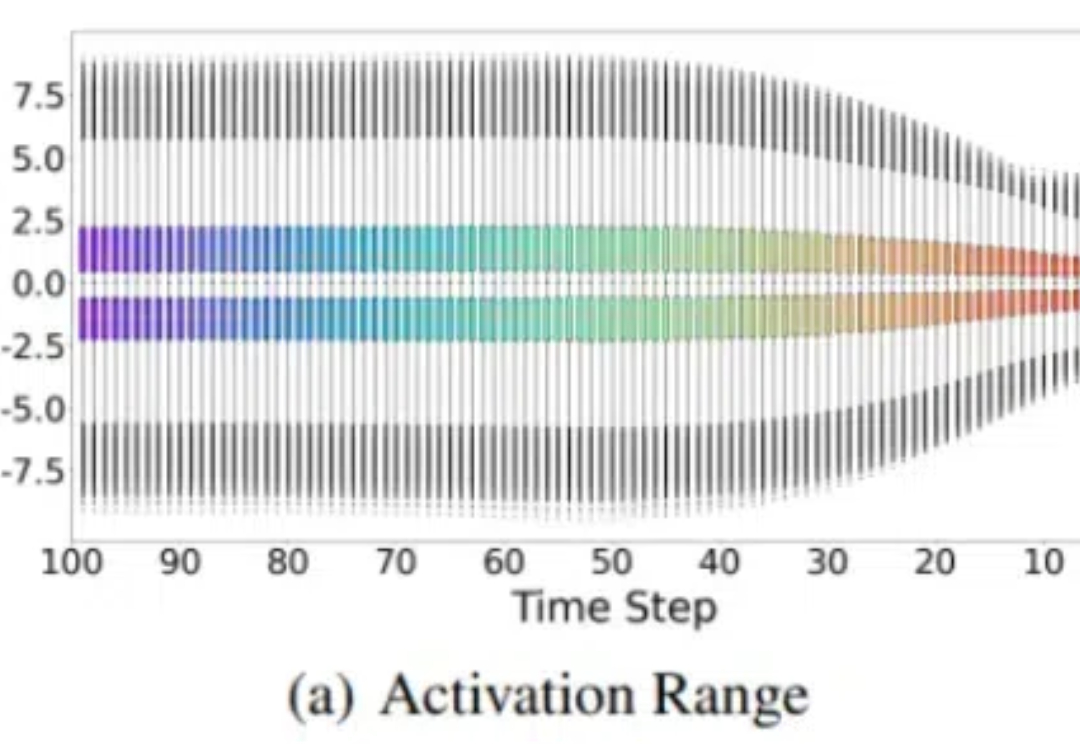
将扩散模型量化到1比特极限,又有新SOTA了! 来自北航、ETH等机构的研究人员提出了一种名为BiDM的新方法,首次将扩散模型(DMs)的权重和激活完全二值化。
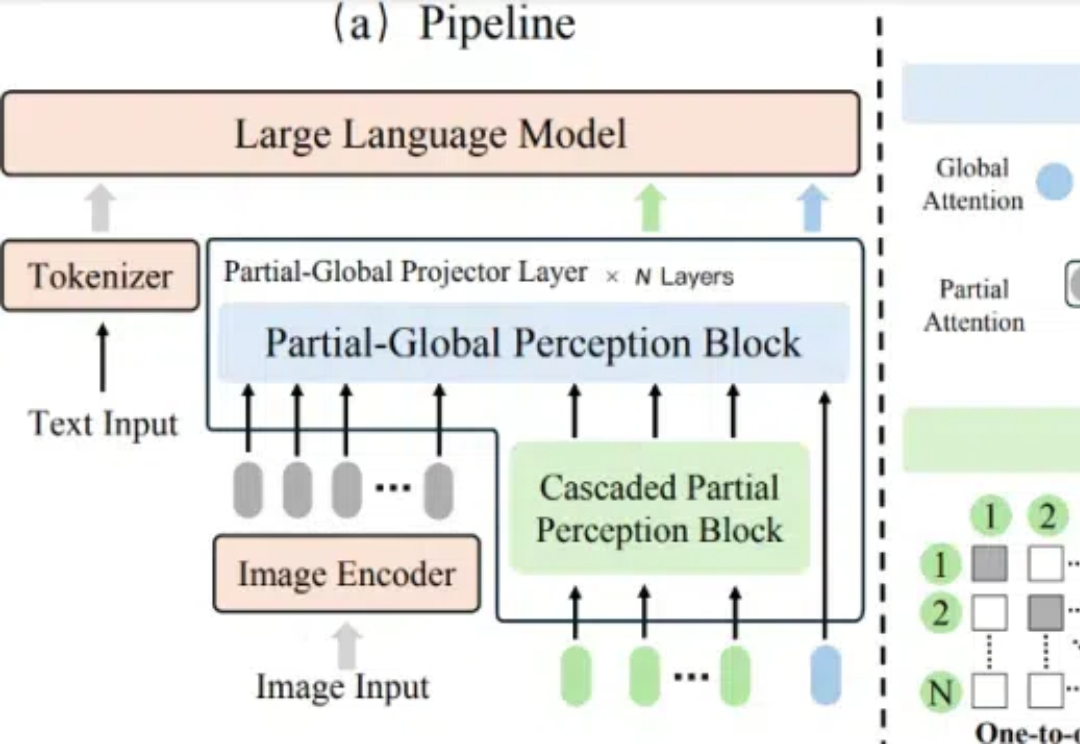
在多模态大语言模型(MLLMs)的发展中,视觉 - 语言连接器作为将视觉特征映射到 LLM 语言空间的关键组件,起到了桥梁作用。

LLM会把编程淘汰吗?近日,哥本哈根大学的计算机教授,通过分析计算理论中的定理所施加的基本限制,得出结论:距离编程的终结还远得很。
Meta-CoT 通过显式建模生成特定思维链(CoT)所需的底层推理过程,扩展了传统的思维链方法。

大模型长序列的处理能力已越来越重要,像复杂长文本任务、多帧视频理解任务、以及 OpenAI 近期发布的 o1、o3 系列模型的高计算量模式,需要处理的输入 + 输出总 token 数从几万量级上升到了几百万量级。
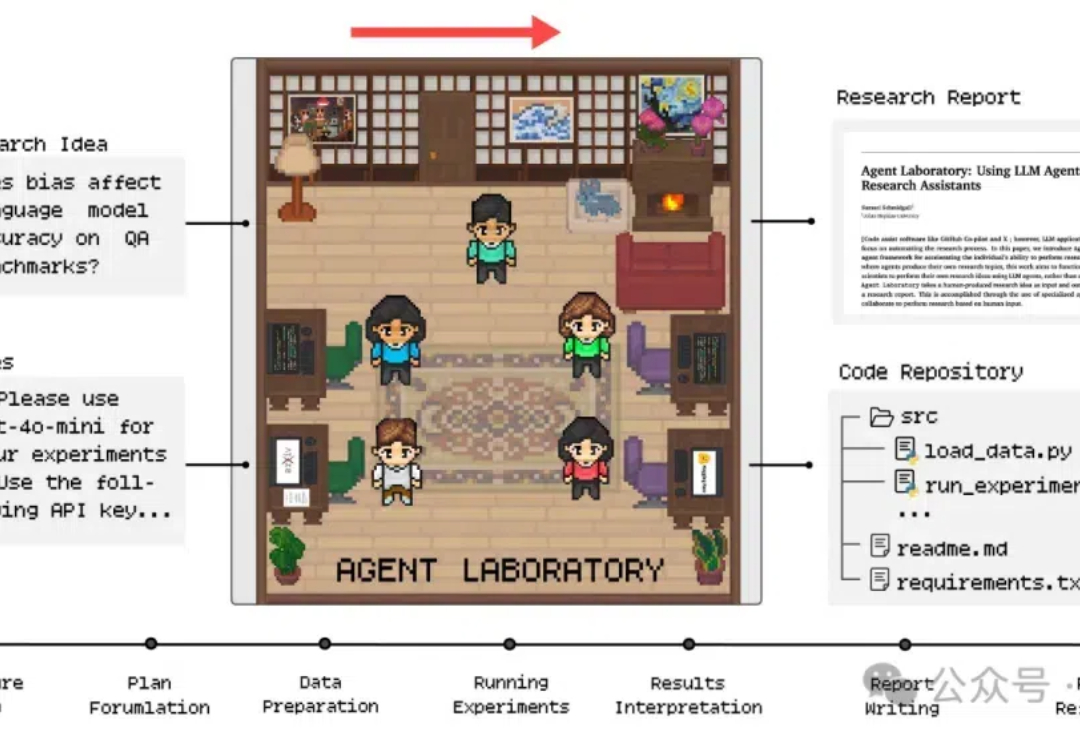
芯片强者AMD最新推出科研AI,o1-preview竟成天选打工人?! 注意看,只需将科研idea和相关笔记一股脑丢给AI,研究报告甚至是代码就能立马出炉了。

大连理工大学的研究人员提出了一种基于Wasserstein距离的知识蒸馏方法,克服了传统KL散度在Logit和Feature知识迁移中的局限性,在图像分类和目标检测任务上表现更好。
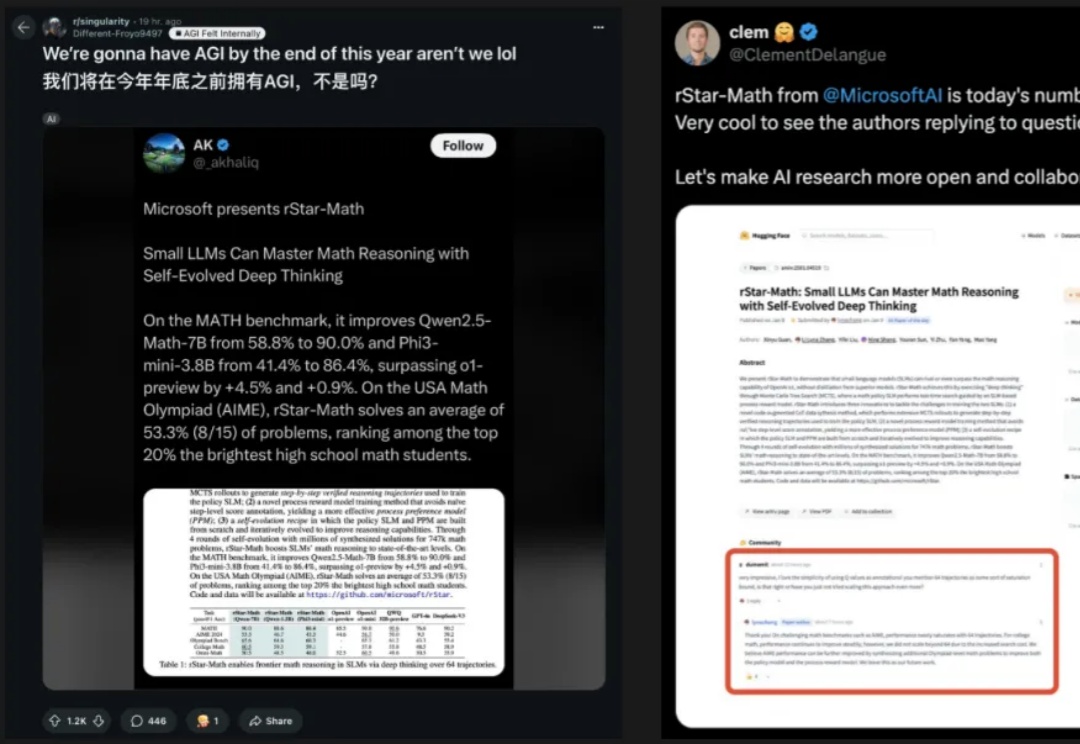
小模型也能击败o1?微软全华人团队提出rStar-Math算法,三大革命性技术突破,不仅让SLM在数学推理能力上刷新SOTA,更是挤进了全美20%顶尖高中生榜单。

最新综述论文探讨了知识蒸馏在持续学习中的应用,重点研究如何通过模仿旧模型的输出来减缓灾难性遗忘问题。通过在多个数据集上的实验,验证了知识蒸馏在巩固记忆方面的有效性,并指出结合数据回放和使用separated softmax损失函数可进一步提升其效果。