# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
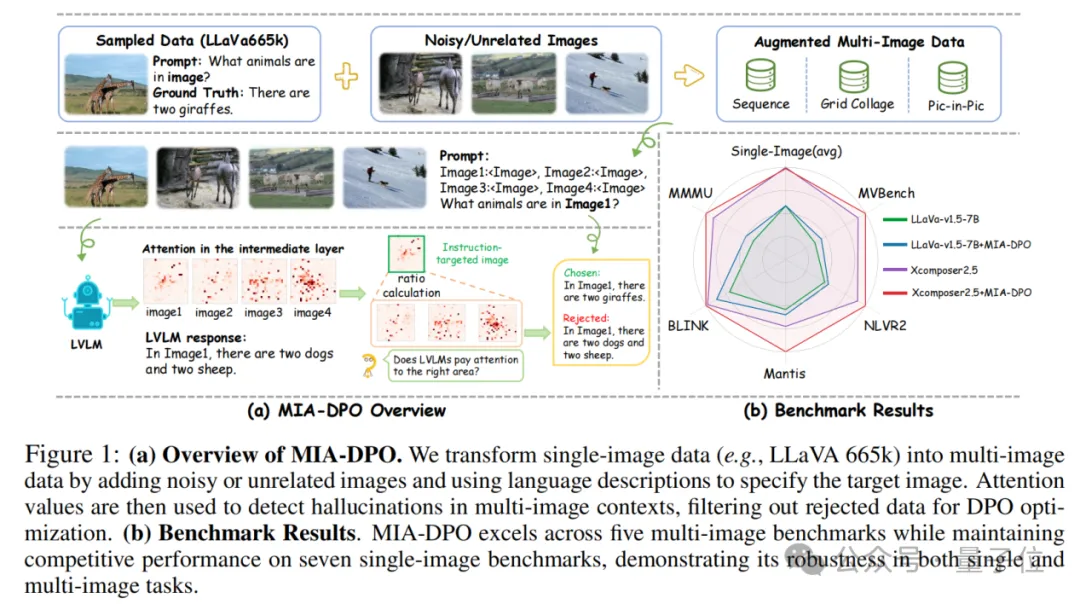
多图像场景也能用DPO方法来对齐了!
由上海交大、上海AI实验室、港中文等带来最新成果MIA-DPO。
这是一个面向大型视觉语言模型的多图像增强的偏好对齐方法。
通过将单图像数据扩展至多图像数据,并设计序列、网格拼贴和图中图三种数据格式,MIA-DPO大幅降低了数据收集和标注成本,且具有高度可扩展性。

要知道,理解多图像上下文已经成为视觉语言大模型的发展趋势之一,许多数据集和评估基准被提出。不过幻觉问题依然很难避免,且引入多图像数据可能削弱单图像任务的表现。
虽然偏好对齐方法(如DPO)在单图像场景中已被证明有效,但多图像偏好对齐仍然是一个解决问题。
MIA-DPO不仅解决了这一问题,而且无需依赖人工标注或昂贵的API。
通过分析视觉大语言模型在多图像处理中的注意力分布差异,他们提出了一种基于注意力的选择方法(Attention Aware Selection),自动过滤掉关注无关图像的错误答案,构建了自动化、低成本且适用于多图像场景的DPO数据生成方法。
值得一提的是,该论文还获得了当日HuggingFace Daily Paper #1.
为从根本上研究LVLM的多图推理问题,研究者首先深入探索了多图情境下LVLM的幻觉问题。一些早期研究探讨了不同类型的单图像幻觉现象,例如物体幻觉,指的是模型错误描述图像中不存在的物体。与单图像幻觉相比,多图像场景引入了更加复杂的幻觉类型。如图2所示,研究者将多图像幻觉分为两类:
(1) Sequence Confusion
当模型面对多张图片时,可能无法准确识别输入提示所指向的图像。例如,在图2的上方案例中,问题是针对图像1(人与大海),但模型的回答却基于图像4(铁轨上的火车)。
(2) Element Interference
相比单图像,多图像场景中的视觉元素数量显著增加,导致LVLMs在不同元素之间产生混淆。例如,在图2的下方案例中,问题“图像2中的汽车是什么颜色?”本应回答为“白色”。然而,LVLM错误地将图像3中摩托车的颜色属性理解为图像2中汽车的颜色,导致了错误的回答。

为构建能够提升多图感知与推理能力并缓解幻觉的视觉文本对齐方法,研究者们提出了注意力机制作为检测幻觉的指标。
注意力机制揭示了模型在做出决策时“关注”的位置。研究者们观察到,注意力机制为检测多图像幻觉提供了重要线索。
理想情况下,注意力值应集中在与问题相关的输入图像的特定区域上。如果注意力值分散或未强烈聚焦于正确的视觉元素或区域,表明模型在理解多图像序列或区分不同图像的元素时存在困难。
基于这一观察,研究者们设计了一种基于注意力感知的选择机制,利用注意力值在DPO算法中选择包含幻觉的被拒绝样本。MIA-DPO的框架如下图3所示。
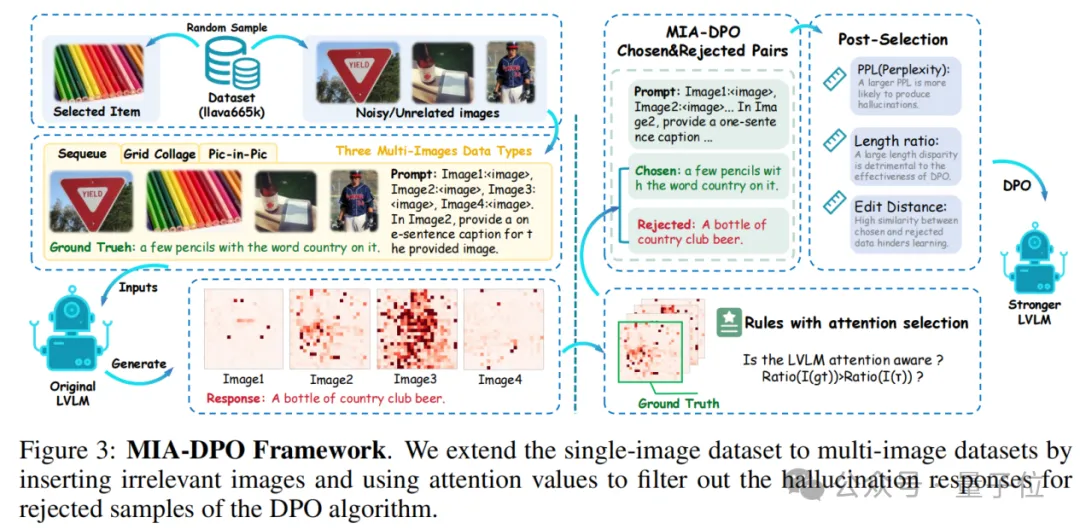
尽管基于注意力感知的选择机制在构建DPO数据时效果显著,但仍可能会包含少量噪声样本,进而对模型产生不利影响。为此,研究者们引入后选择步骤,通过以下三个指标来过滤噪声样本:(1) 困惑度(Perplexity, PPL);(2) 长度比率(Length Ratio);(3) 编辑距离(Edit Distance)。
在构造DPO数据的过程中,研究者通过引入无关图像高效地转换现有的单图像数据集(例如LLaVA-665k)。
该方法低成本、可扩展,数据形式丰富的优势,使MIA-DPO能够较为全面地缓解LVLMs可能产生的各种多图像幻觉类型。
如下图所示,研究者构建了三种格式的多图像DPO数据:
(1) 序列数据:多张图像按顺序排列,问题针对特定图像。图像数量从2到5张不等;
(2) 网格拼贴数据:多张图像合并为一张图,每张图像都有编号说明。问题根据语言描述定位到特定图像。图像数量从2到9张不等;
(3) 图中图数据:一张图像被缩放并叠加在另一张图像上,问题围绕组合后的图像展开。

研究者在多个多图和单图benchamrks上对MIA-DPO进行了测试。
实验结果显示,在经典的LLaVa1.5模型和更为强大的InternLM-Xcomposer2.5上,MIA-DPO都能显著提升模型的多图感知与推理能力,如图所示,LLaVa1.5和InternLM-Xcomposer2.5在五个多图benchmarks上分别取得了平均3%和4.3%的性能提升。
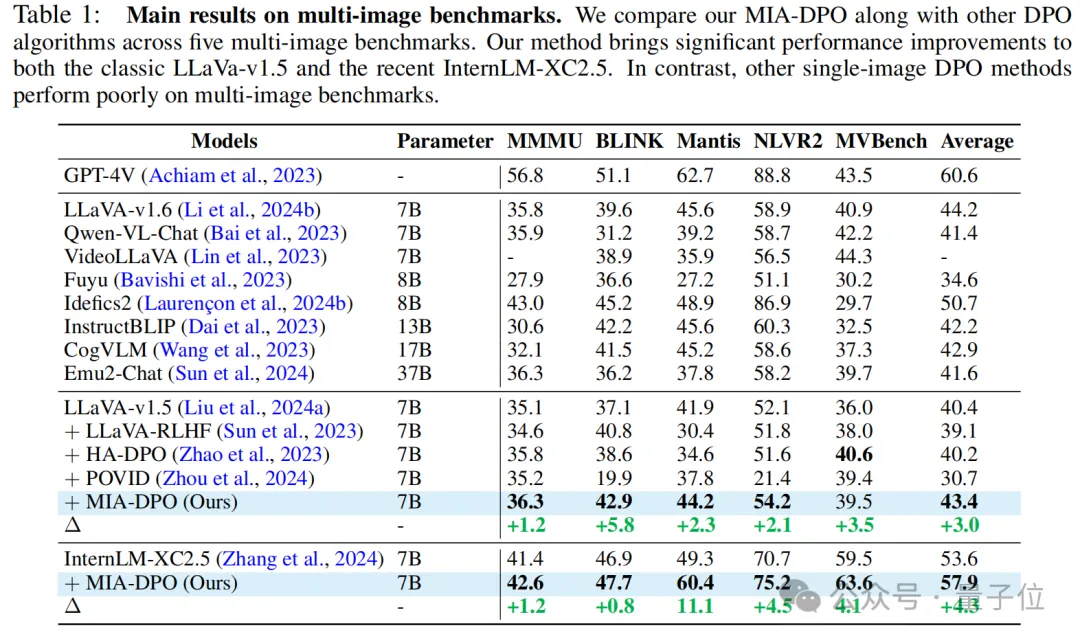
除此之外,研究着在多个单图benchmarks上也进行了丰富的实验,结果显示MIA-DPO在提升模型多图感知与推理能力的同时,也能保持住模型原有的单图理解能力。
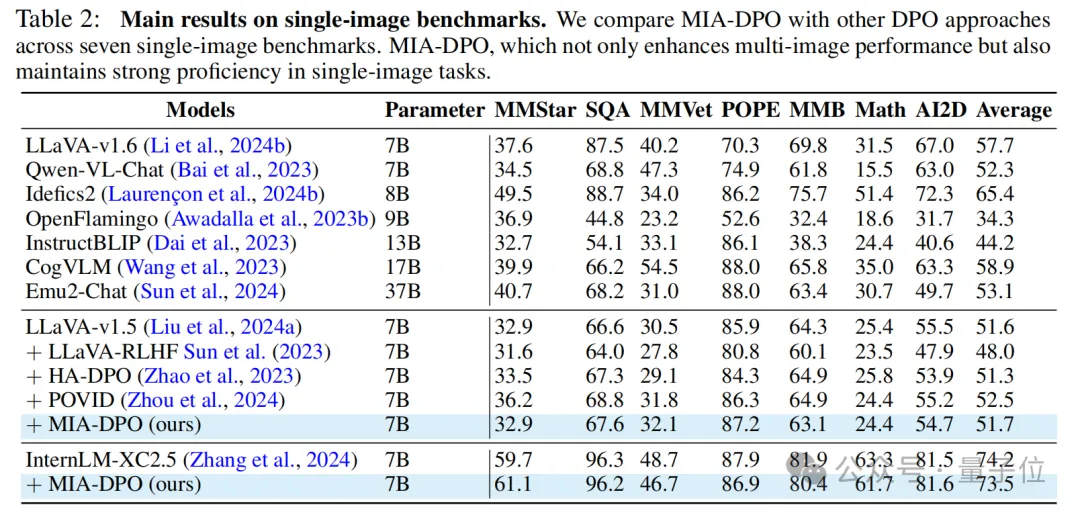
最后小结一下。
MIA-DPO不仅为多图像场景中对齐模型与人类偏好提出了全新解决方案,还通过引入低成本、可扩展的数据生成方法,推动了LVLMs在处理复杂多图像任务中的应用。MIA-DPO的成功证明了通过偏好优化对齐模型与人类反馈,在提升模型多图像感知与推理能力的同时,也可以保持原有的单图任务性能,为未来的研究奠定了坚实基础。
论文地址:
https://arxiv.org/abs/2410.17637
Project Page:
https://liuziyu77.github.io/MIA-DPO/
Code:
https://github.com/Liuziyu77/MIA-DPO
文章来自于微信公众号“量子位”,作者“刘子煜”



【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
