
云端模型如何落地物理世界?招商局狮子山人工智能实验室用LiOS打通具身智能全链路
云端模型如何落地物理世界?招商局狮子山人工智能实验室用LiOS打通具身智能全链路把一件皱成一团的衣服叠好,是家务,也是机器人操作里的“硬仗”。
来自主题: AI技术研报
8827 点击 2026-06-02 11:57
 搜索
搜索
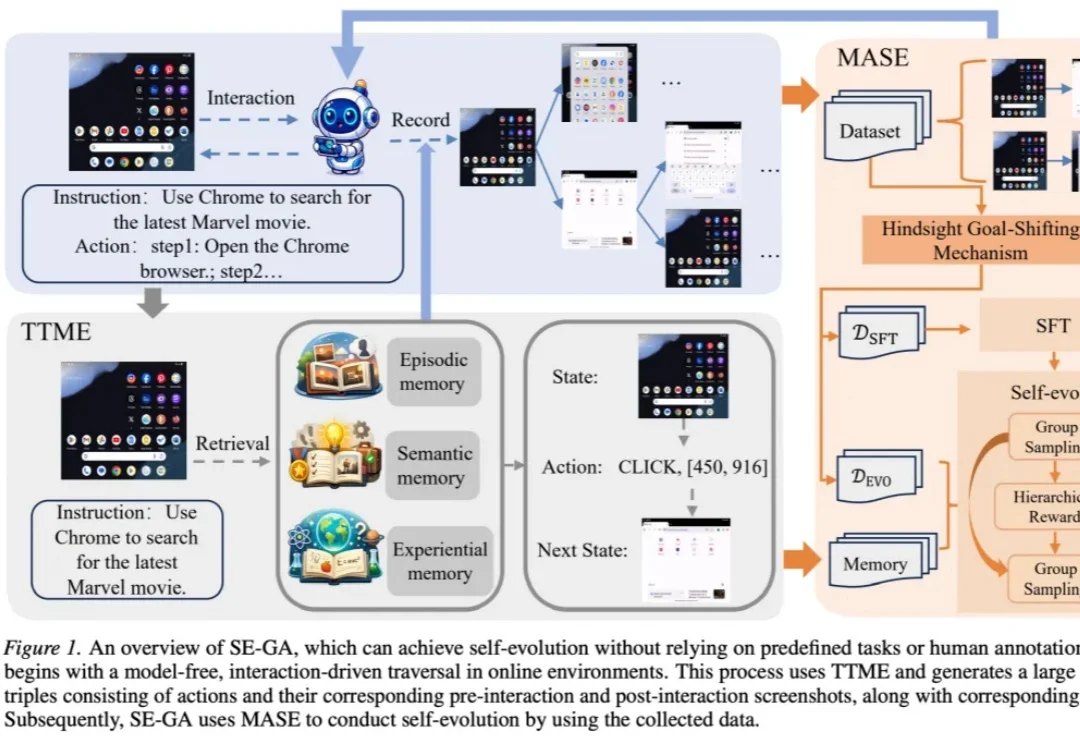
把一件皱成一团的衣服叠好,是家务,也是机器人操作里的“硬仗”。

2026 年初,各大 AI 厂商在上下文窗口长度上展开激烈角逐。Google 的 Gemini 3 Pro 已支持 100 万级 token 上下文,Meta 的 Llama 4 Scout 更宣称可处理 1000 万 token。GPT-5 系列也在快速推进长上下文能力。
本文团队长期从事负责任的人工智能与人工智能赋能社会科学相关研究,围绕视觉生成大模型安全治理、智能体安全等方向开展系统性工作,相关成果发表于AAAI、ICML、TMM 等国际期刊与会议。

紧跟DeepSeek价格战,小米掏出技术底牌!

从大模型的提示词到智能体的 Skills,看着进化了,但又没有完全进化。
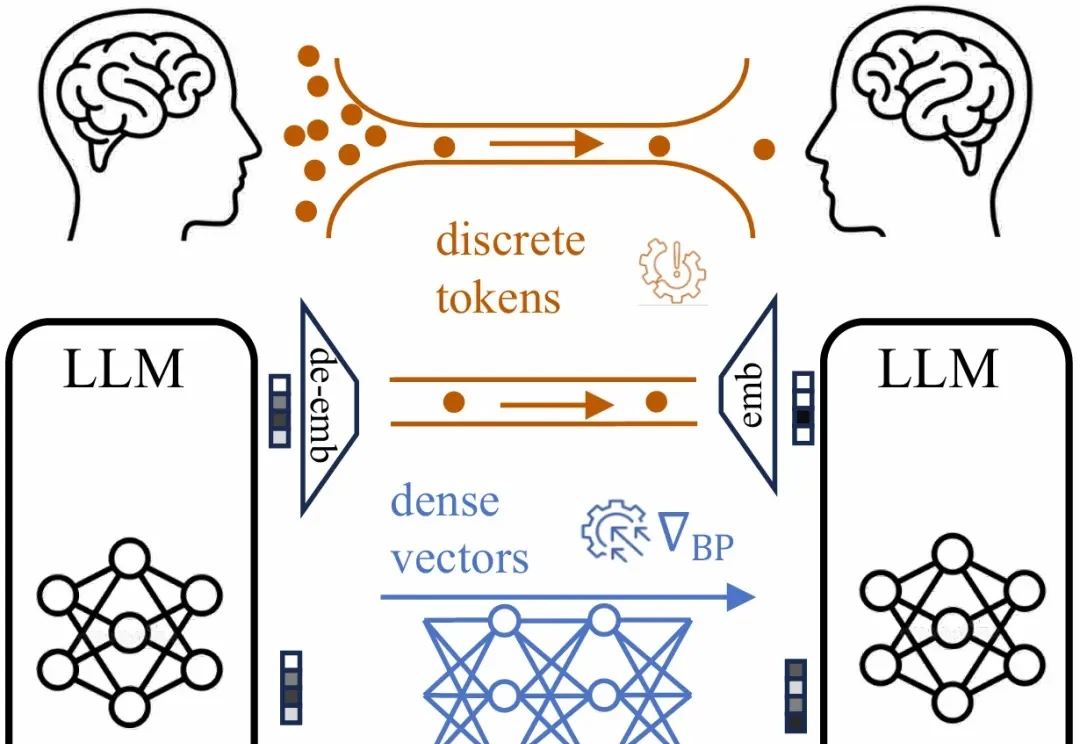
大语言模型正在成为人工智能系统的核心组件。从文本生成、数学推理到代码编写,单个大模型已经展现出强大的能力。
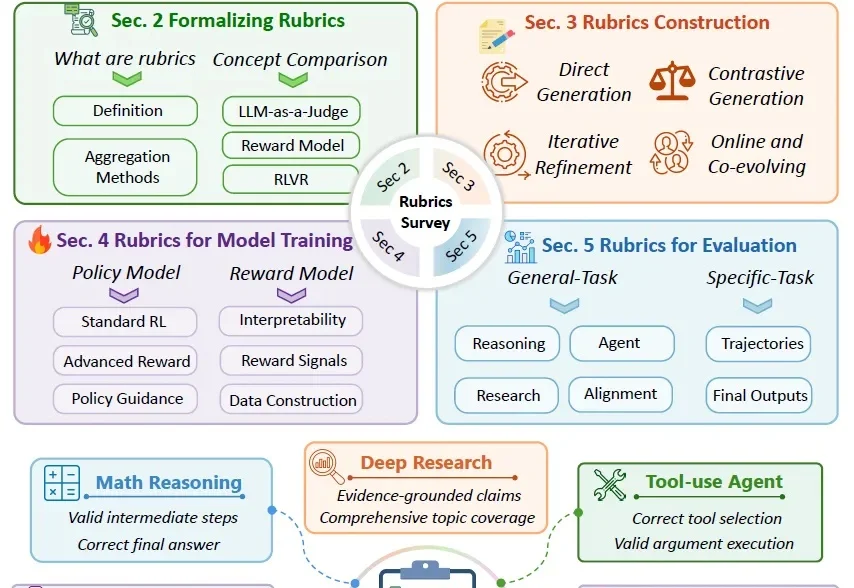
近年来,随着大模型从简单问答,走向深度研究、医疗咨询、多模态生成和长程 Agent 任务,一个基础问题变得越来越难回答:我们到底应该怎样判断模型输出的质量?
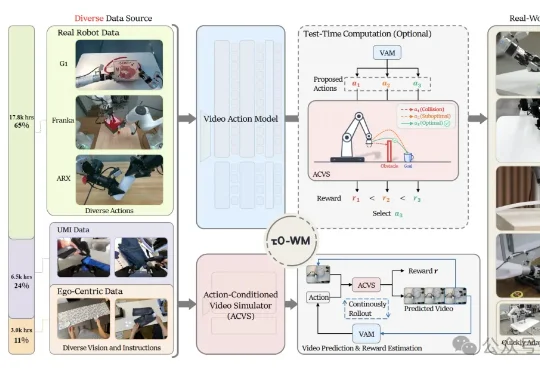
刚刚,上海创智学院副教授、智元机器人首席科学家罗剑岚带队,发布全球最大规模的开源预训练具身世界模型——τ0-World Model(τ0-WM)。整个τ0-WM参数量达到5B,预训练数据规模高达约3万小时。其中,真机遥操作数据第一次成了绝对主力,占到了1.78万小时。

Heygo.ai对比每一次滑行数据,分析动作变化,并明确告诉接下来需要改进的地方。基于你的专属数据、滑行风格、习惯,为有经验的爱好者制定一套系统化的训练方案,精准攻克薄弱环节。

大模型从“回答问题”走向“完成任务”,正在面临以下瓶颈:面向Claw Agents的数据、训练和评测都比传统environment training更难。为了解决该问题,中国人民大学、至知研究院等最新提出ClawGym——