
DSPy还能整RAG的活?LeReT: 用强化学习实现LLM智能检索
DSPy还能整RAG的活?LeReT: 用强化学习实现LLM智能检索斯坦福大学奥马尔(Omar)的DSPy研究团队最近更新了他们的项目文档,发了很多不错的案例,以及很多国际知名企业的DSPy用例,这些可能对您的项目有启发。
来自主题: AI资讯
4933 点击 2024-11-04 10:09
 搜索
搜索
斯坦福大学奥马尔(Omar)的DSPy研究团队最近更新了他们的项目文档,发了很多不错的案例,以及很多国际知名企业的DSPy用例,这些可能对您的项目有启发。

在人工智能(AI)领域,特别是深度学习和神经网络训练中,GPU(图形处理单元)已经成为不可或缺的硬件。但为什么AI对GPU的要求高,而不是CPU(中央处理单元)呢?让我们通过一个生动的比喻来揭开这个谜团。

RAG,AI,模型训练,人工智能

在人工智能领域,大型预训练模型(如 GPT 和 LLaVA)的 “幻觉” 现象常被视为一个难以克服的挑战,尤其是在执行精确任务如图像分割时。

AI,LLM,模型训练,人工智能
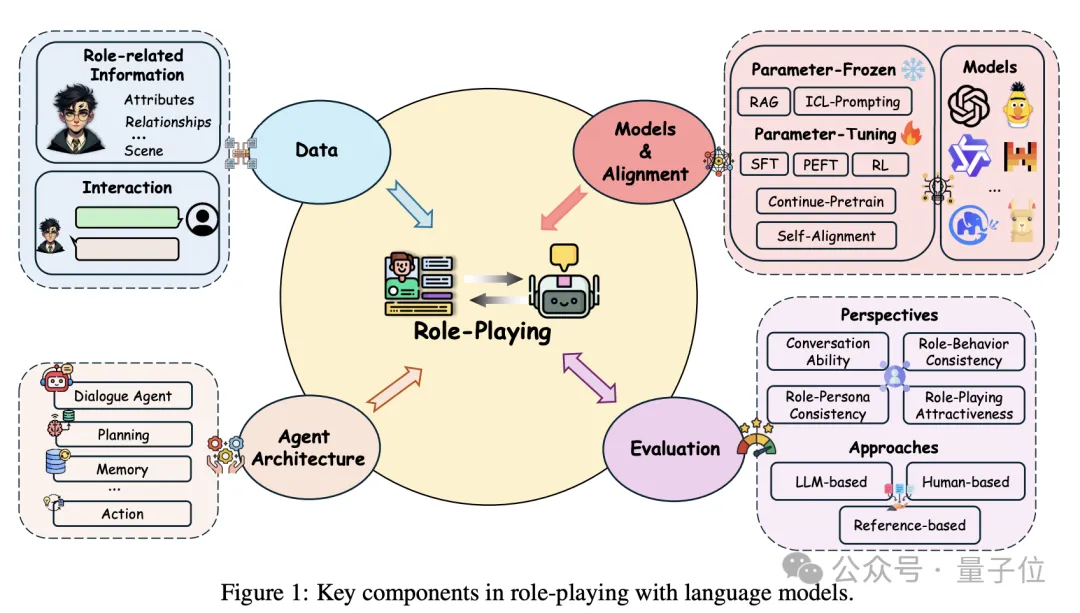
AI界也有了自己的“奥斯卡”,哪家大模型角色扮演更入戏? 来自香港科技大学、腾讯、新加坡管理大学的团队提出新综述—— 不仅系统性地回顾了角色扮演语言模型的发展历程,还对每个阶段的关键进展进行了深入剖析,展示了这些进展如何推动模型逐步实现更复杂、更逼真的角色扮演。

Transformer自问世后就大放异彩,但有个小毛病一直没解决: 总爱把注意力放在不相关的内容上,也就是信噪比低。 现在微软亚研院、清华团队出手,提出全新改进版Differential Transformer,专治这个老毛病,引起热议。

改进KV缓存压缩,大模型推理显存瓶颈迎来新突破—— 中科大研究团队提出Ada-KV,通过自适应预算分配算法来优化KV缓存的驱逐过程,以提高推理效率。

多图像场景也能用DPO方法来对齐了! 由上海交大、上海AI实验室、港中文等带来最新成果MIA-DPO。 这是一个面向大型视觉语言模型的多图像增强的偏好对齐方法。
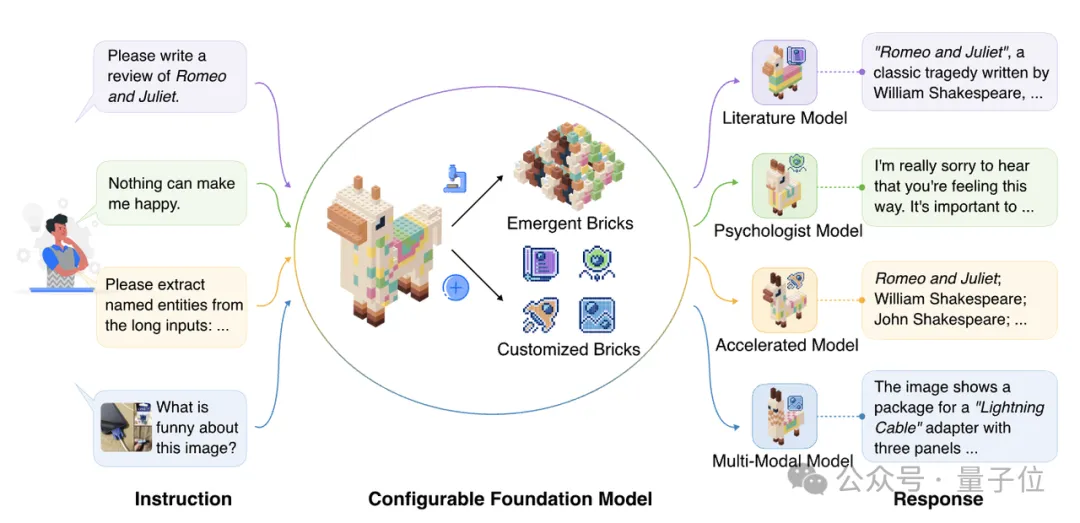
探索更高效的模型架构, MoE是最具代表性的方向之一。 MoE架构的主要优势是利用稀疏激活的性质,将大模型拆解成若干功能模块,每次计算仅激活其中一小部分,而保持其余模块不被使用,从而大大降低了模型的计算与学习成本,能够在同等计算量的情况下产生性能优势。