马斯克也拥抱C语言了!大模型训练堆栈抛弃JAX,提速一个数量级
马斯克也拥抱C语言了!大模型训练堆栈抛弃JAX,提速一个数量级不用JAX,SpaceX正在用C语言编写的全新堆栈训练新模型。而且马斯克本人亲口承认,Grok 5已经用的就是这个新堆栈。按马斯克的说法,这种新堆栈能让大模型训练速度提升一个数量级。
来自主题: AI资讯
8168 点击 2026-05-29 15:10
 搜索
搜索
不用JAX,SpaceX正在用C语言编写的全新堆栈训练新模型。而且马斯克本人亲口承认,Grok 5已经用的就是这个新堆栈。按马斯克的说法,这种新堆栈能让大模型训练速度提升一个数量级。

近日,千寻智能高阳团队的研究成果 《Learning Native Continuation for Action Chunking Flow Policies》 被机器人顶会 RSS 2026 接收!这项工作从训练机制出发,让机器人动作天然具有连续性,实现了 "连音" 般的流畅执行,在五个真实世界操作任务上超越了现有方法,为具身智能领域的动作生成研究提供了新的思路。

真实世界需要 200 多个小时的模型评测任务,可以在仿真中不到 0.5 小时内完成。

光正在进入AI算力系统,但这次不只是拿来传数据,而是直接参与计算。
OpenAI 公开介绍 Computer-Using Agent 时,讲的也是这个方向:模型针对图形界面交互做过训练,能把屏幕理解、任务目标和鼠标键盘动作接起来。鼠标会动只是表面。遇到按钮位置变化、弹窗多一层、页面慢一点时,它还能重新看屏幕,继续判断下一步。
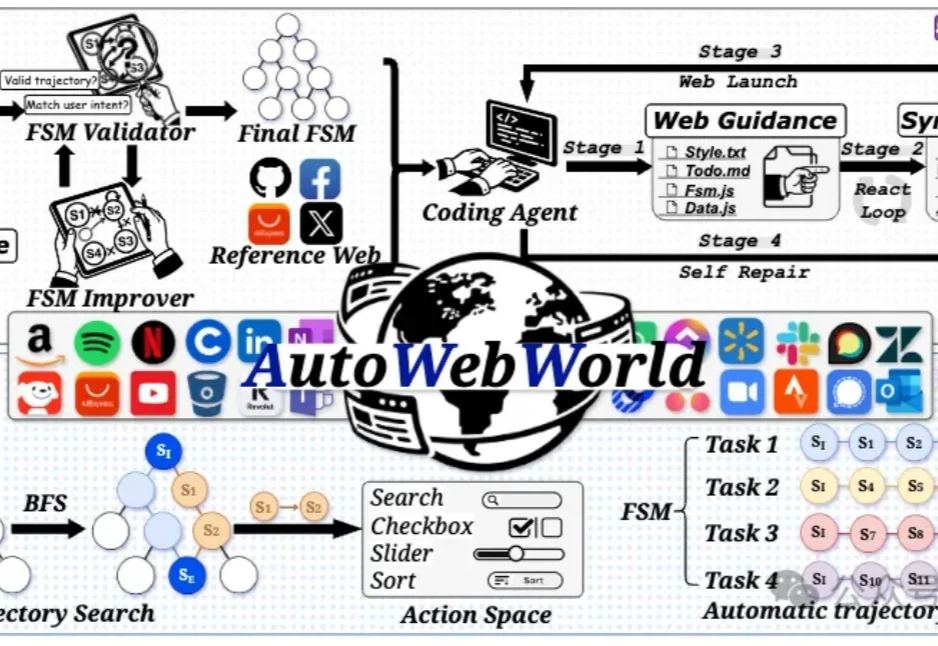
训练一个真正会用网页的GUI Agent,最自然的思路通常是: 去真实网站上操作,收集轨迹,再拿来训练。
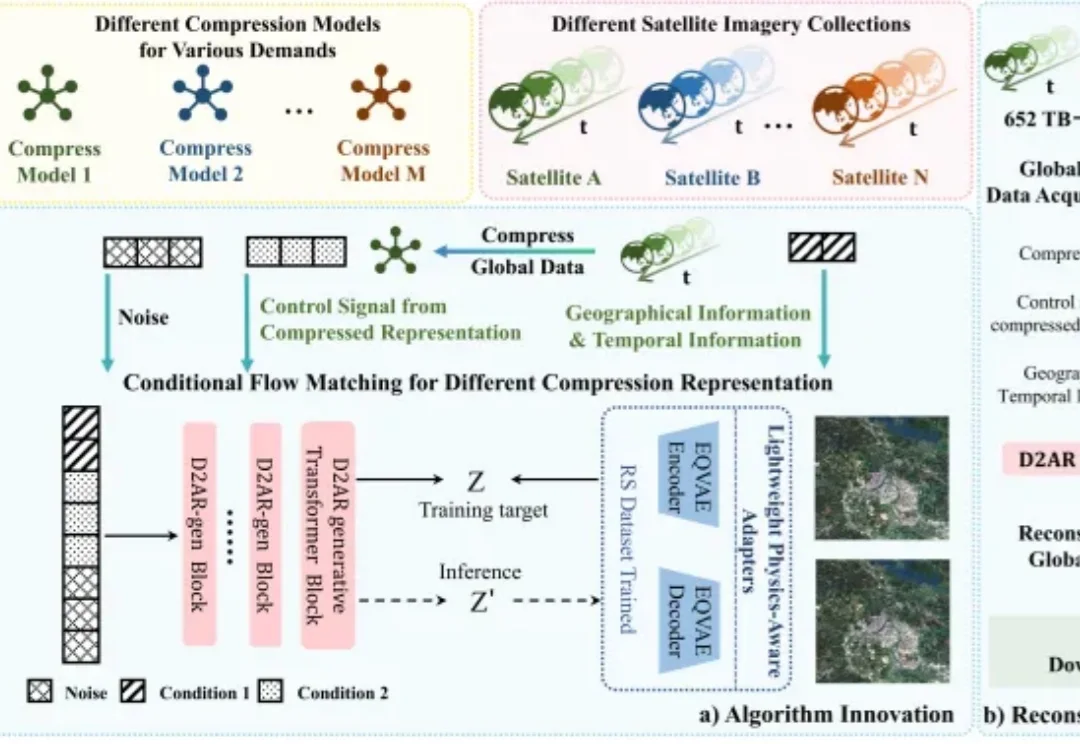
随着全球遥感卫星持续运行,地球观测数据正在快速增长。多源、多时相、多光谱遥感影像为国土监测、生态评估、灾害预警、气候变化研究等任务提供了重要数据基础,但也带来了显著的存储、传输和计算压力。
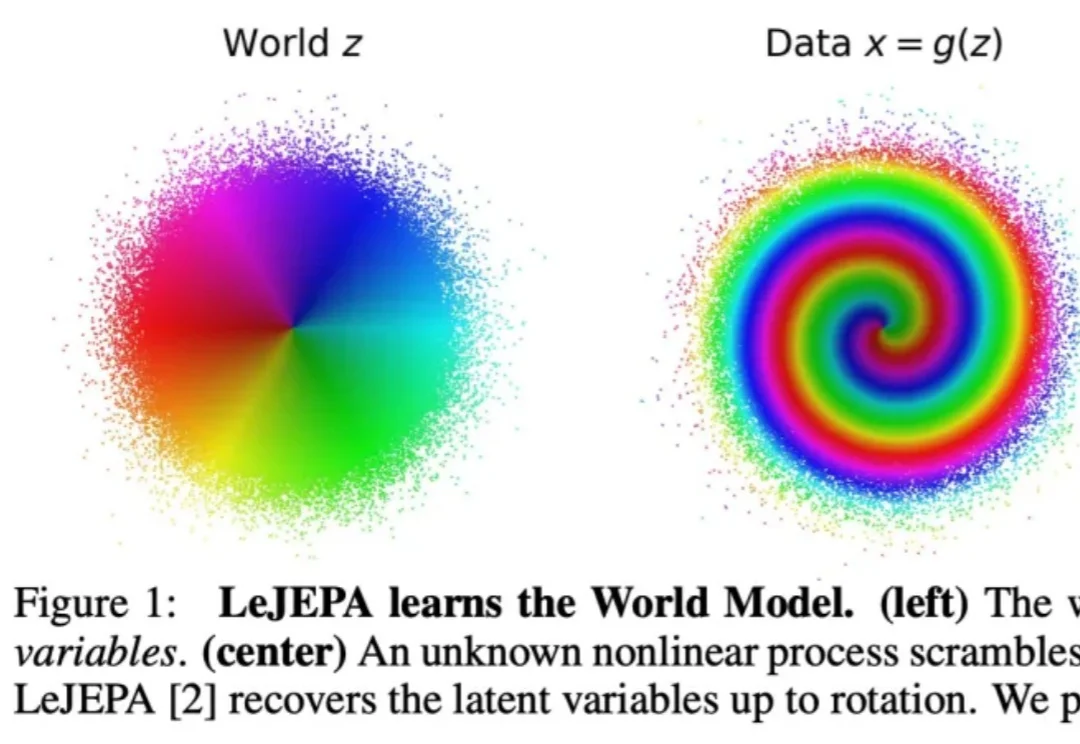
LeCun的LeJEPA到底有没有构建出世界模型?他本人最新发表的论文,解答了这个问题。

2026 年初,国内具身智能赛道掀起了一波开源潮,越来越多团队开始公开自己的视觉-语言-动作(VLA)模型、数据集与训练框架。与此同时,行业竞争也逐渐集中到 benchmark 成绩、任务成功率以及跨任务泛化能力上,尤其是在标准化或已训练任务中的表现。

7×24,AI也吃不消。