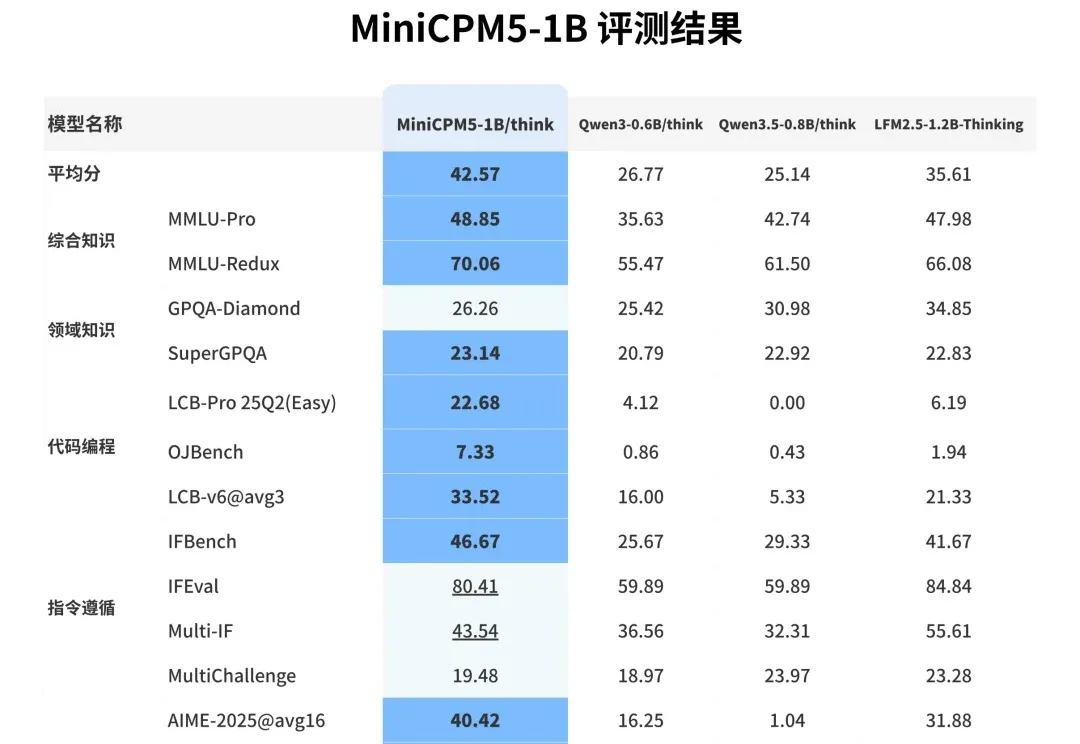
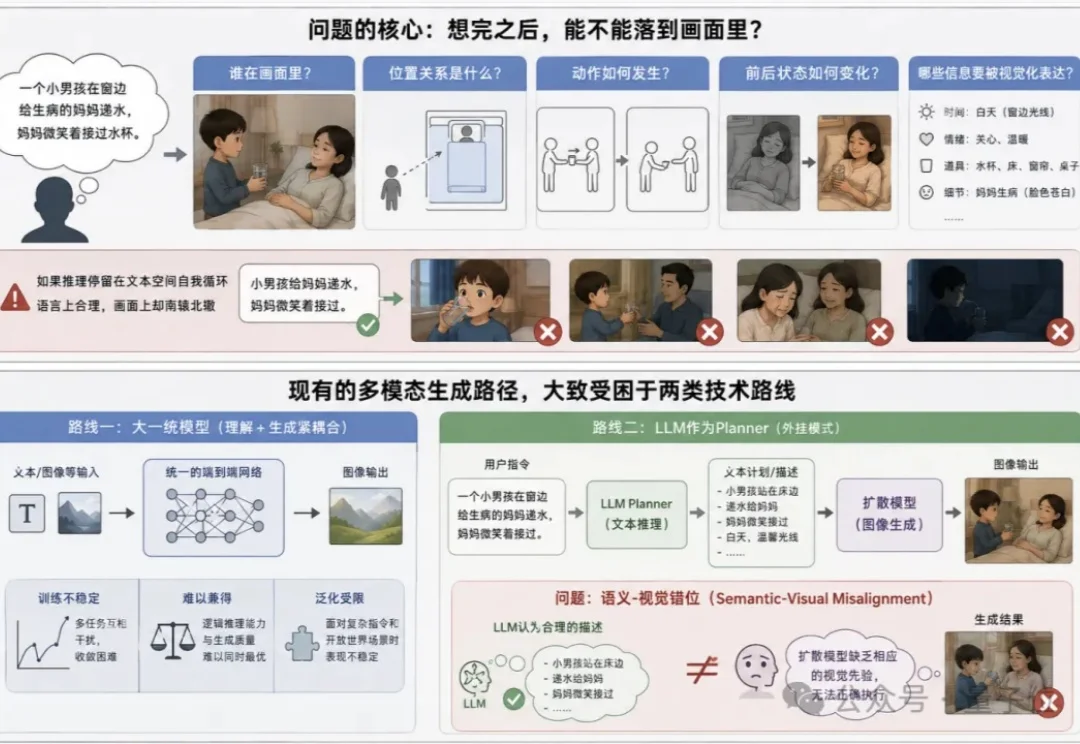
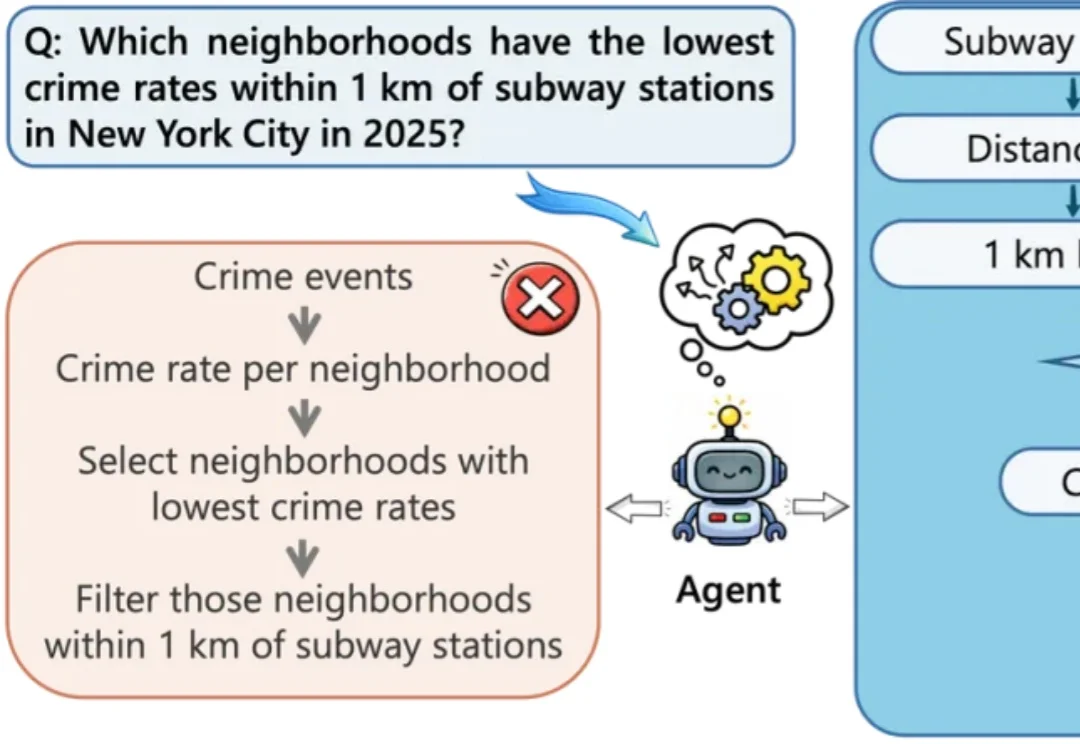
Claude Code和机器人背后的共同机制,UIUC、Meta、Stanford这篇最新综述讲清楚了
Claude Code和机器人背后的共同机制,UIUC、Meta、Stanford这篇最新综述讲清楚了说在前面:这又是一篇讲Harness的Survey,你最近可能已经看过了数篇讲Harness的文章、论文,其中还可能包括我上周解读的《Agent Harness Engineering:Agent的底盘工程综述|CMU、耶鲁、Amazon》。
来自主题: AI技术研报
11403 点击 2026-05-27 08:46