
6700万参数比肩万亿巨兽GPT-4!微软MIT等联手破解Transformer推理密码
6700万参数比肩万亿巨兽GPT-4!微软MIT等联手破解Transformer推理密码来自微软、MIT等机构的学者提出了一种创新的训练范式,攻破了大模型的推理缺陷。他们通过因果模型构建数据集,直接教模型学习公理,结果只有67M参数的微型Transformer竟能媲美GPT-4的推理能力。
来自主题: AI技术研报
10291 点击 2024-07-14 13:52
 搜索
搜索
来自微软、MIT等机构的学者提出了一种创新的训练范式,攻破了大模型的推理缺陷。他们通过因果模型构建数据集,直接教模型学习公理,结果只有67M参数的微型Transformer竟能媲美GPT-4的推理能力。

为什么说理解长视频难如 “大海捞针”?
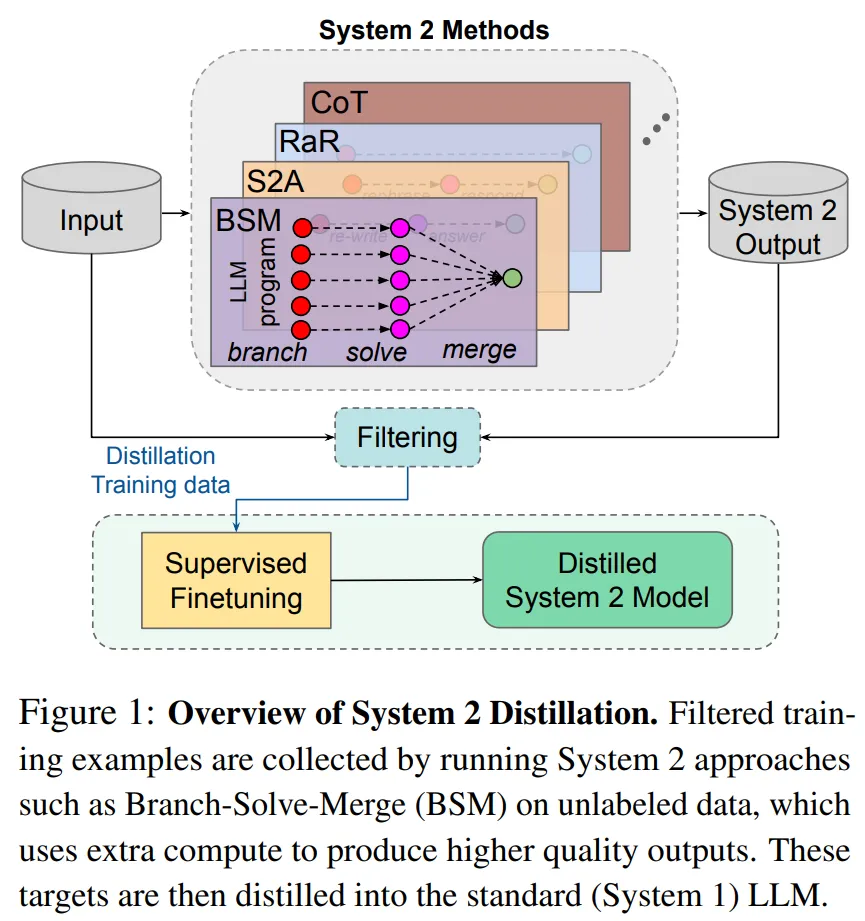
研究者表示,如果 Sytem 2 蒸馏可以成为未来持续学习 AI 系统的重要特征,则可以进一步提升 System 2 表现不那么好的推理任务的性能。

AI 代理得越来越重要,能够实现自主决策和解决问题。为了有效运作,这些代理需要一个确定最佳行动方案的规划过程,然后执行计划的行动。

当前的视觉语言模型(VLM)主要通过 QA 问答形式进行性能评测,而缺乏对模型基础理解能力的评测,例如 detail image caption 性能的可靠评测手段。

Mamba模型由于匹敌Transformer的巨大潜力,在推出半年多的时间内引起了巨大关注。但在大规模预训练的场景下,这两个架构还未有「一较高低」的机会。最近,英伟达、CMU、普林斯顿等机构联合发表的实证研究论文填补了这个空白。
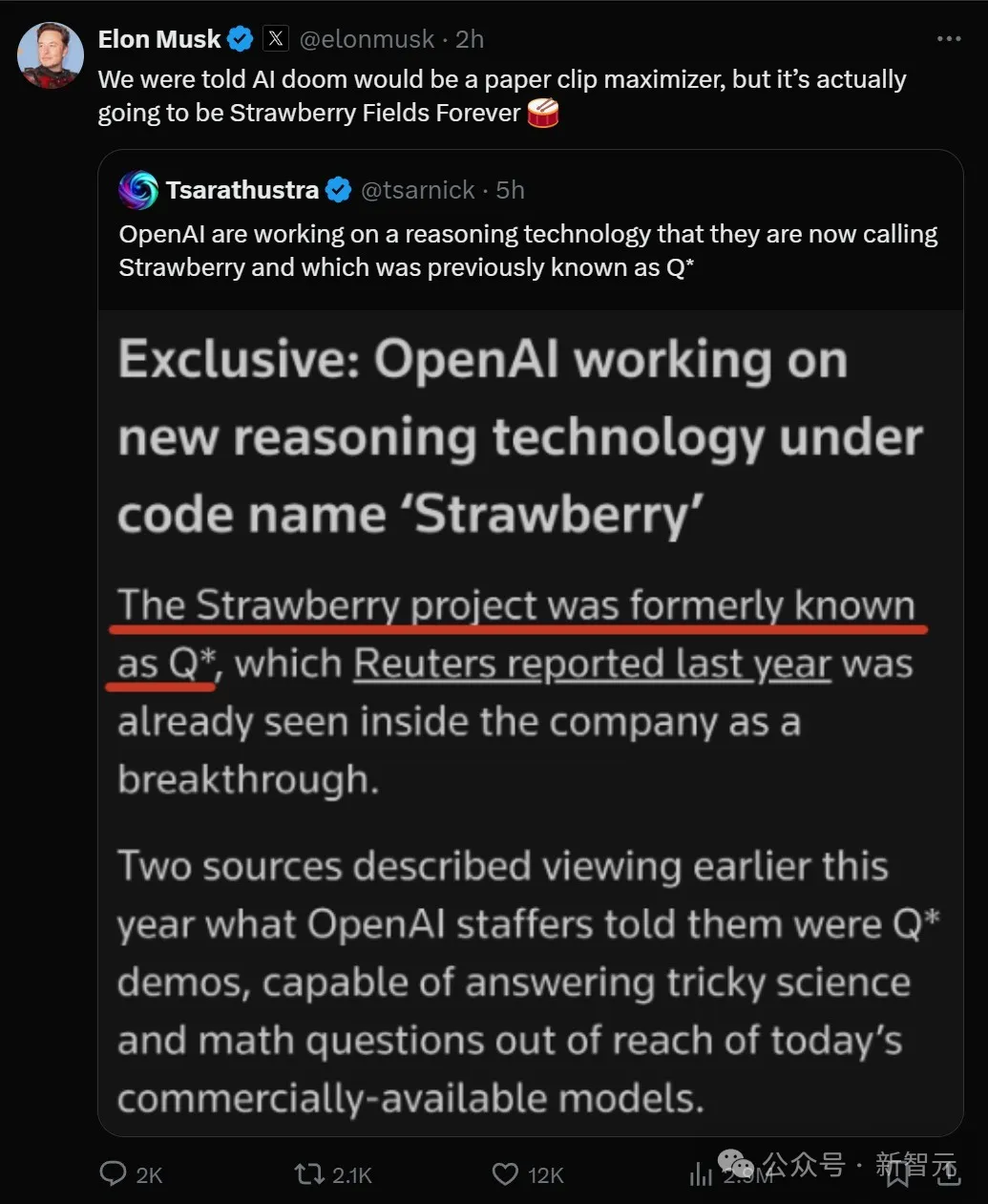
OpenAI被曝出了新项目「草莓」,据悉能提前计划,自主浏览网页,还能进行深度研究。草莓由大量通用数据上后训练而成,推理能力显著提高。根据OpenAI最近的AGI路线图,草莓疑似已达Level 2。

文生图、文生视频,视觉生成赛道火热,但仍存在亟需解决的问题。
OpenAI最新绝密项目曝光!

自从大型 Transformer 模型逐渐成为各个领域的统一架构,微调就成为了将预训练大模型应用到下游任务的重要手段