单个4090可推理,2000亿稀疏大模型「天工MoE」开源
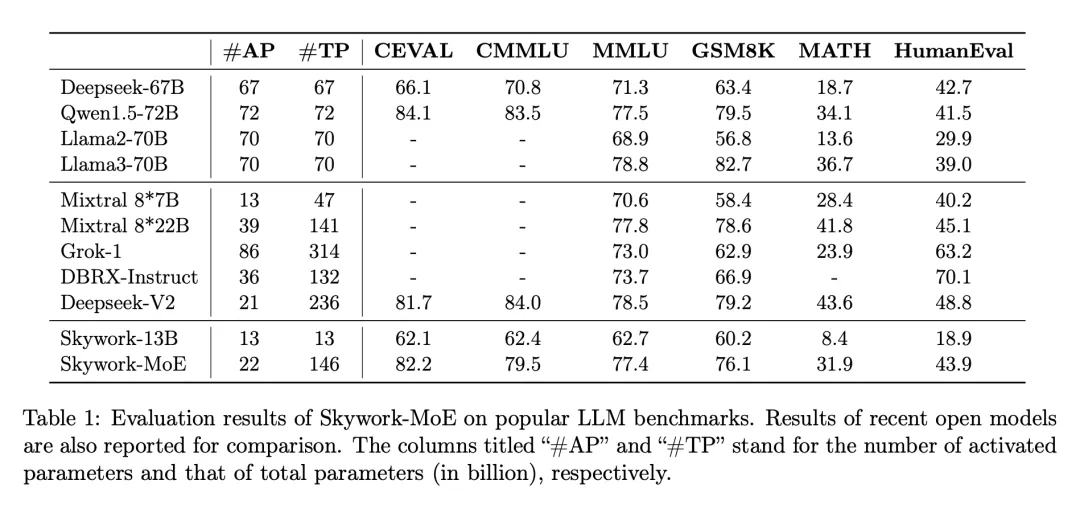
单个4090可推理,2000亿稀疏大模型「天工MoE」开源在大模型浪潮中,训练和部署最先进的密集 LLM 在计算需求和相关成本上带来了巨大挑战,尤其是在数百亿或数千亿参数的规模上。为了应对这些挑战,稀疏模型,如专家混合模型(MoE),已经变得越来越重要。这些模型通过将计算分配给各种专门的子模型或「专家」,提供了一种经济上更可行的替代方案,有可能以极低的资源需求达到甚至超过密集型模型的性能。
来自主题: AI技术研报
10538 点击 2024-06-04 17:59