
ICML 2024 Oral|外部引导的深度聚类新范式
ICML 2024 Oral|外部引导的深度聚类新范式怎样才能将可爱又迷人的柯基与柴犬的图像进行区分?
来自主题: AI技术研报
9397 点击 2024-06-07 10:56
 搜索
搜索
怎样才能将可爱又迷人的柯基与柴犬的图像进行区分?

随着大型语言模型(LLM)规模不断增大,其性能也在不断提升。尽管如此,LLM 依然面临着一个关键难题:与人类的价值和意图对齐。在解决这一难题方面,一种强大的技术是根据人类反馈的强化学习(RLHF)。

CRATE-α是一种新型Transformer架构变体,通过设计改进提升了模型的可扩展性、性能和可解释性,CRATE-α-Base在ImageNet分类任务上的性能显著超过了之前最好的CRATE-B模型,其性能会随着模型和数据集规模扩大而继续提升。

天津大学与南京大学联合团队在CVPR 2024上发表了LPSNet项目,提出了一种端到端的无透镜成像下的3D人体姿态和形状估计框架,通过多尺度无透镜特征解码器和双头辅助监督机制,直接从编码后的无透镜成像数据中提取特征并提高姿态估计的准确度。

大模型价格战,这匹国产黑马又破纪录了!最低的GLM-4 Flash版本,百万token价格已经低至0.1元,可以说是击穿地心。MaaS 2.0大升级,让企业训练私有模型的成本无限降低。

本文介绍了KAN网络算法的原理和优势,探讨了其在深度学习领域可能引发的范式转变。 • ⚡ KAN网络将可学习的激活函数从神经元移到了神经网络的边上,表现出更高的准确性和更少的参数量 • ???? KAN在数学和物理领域的实验中展现了卓越性能,提供了一种新的科学发现的路径 • ???? KAN具有更快的神经缩放定律和可解释性,为AI领域带来了新的探索可能性
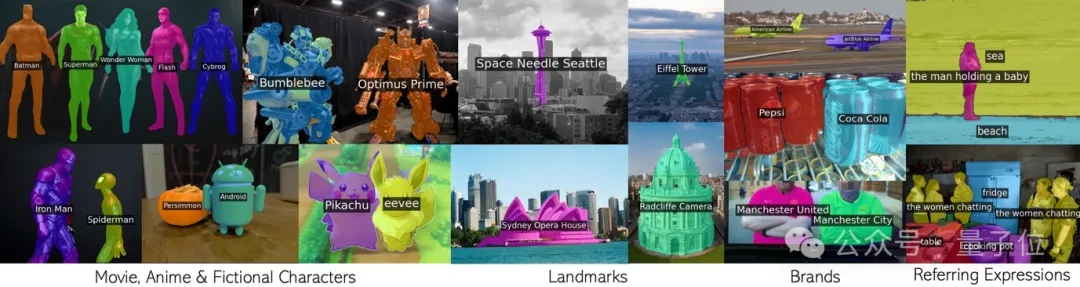
循环调用CLIP,无需额外训练就有效分割无数概念。 包括电影动漫人物,地标,品牌,和普通类别在内的任意短语。

过去十年间,基于随机梯度下降(SGD)的深度学习模型在许多领域都取得了极大的成功。与此同时各式各样的 SGD 替代品也如雨后春笋般涌现。在这些众多替代品中,Adam 及其变种最受追捧。无论是 SGD,还是 Adam,亦或是其他优化器,最核心的超参数非 Learning rate 莫属。因此如何调整好 Leanring rate 是炼丹师们从一开始就必学的技能。

抄袭框架和预训练数据的情况,是更狭义的套壳。

就算是 OpenAI 在舆论场也无法逃过版权保护的呼声。