
谷歌开源TimesFM:1000亿个时间点训练,入选ICML 2024
谷歌开源TimesFM:1000亿个时间点训练,入选ICML 2024在大语言模型突飞猛进的同时,谷歌的研究团队在时序预测方面也取得了突破性的成果——今年2月发表的模型TimesFM,而且放出了模型的代码和权重,让更多开发者体验这种「开箱即用」的零样本预测能力。
来自主题: AI资讯
10464 点击 2024-06-10 14:40
 搜索
搜索
在大语言模型突飞猛进的同时,谷歌的研究团队在时序预测方面也取得了突破性的成果——今年2月发表的模型TimesFM,而且放出了模型的代码和权重,让更多开发者体验这种「开箱即用」的零样本预测能力。

近日,来自密歇根大学的研究人员,开发了一款人工智能工具,可以区分不同含义的狗叫声,并识别狗的年龄、性别和品种。

从大规模网络爬取、精细过滤到去重技术,通过FineWeb的技术报告探索如何打造高质量数据集,为大型语言模型(LLM)预训练提供更优质的性能。
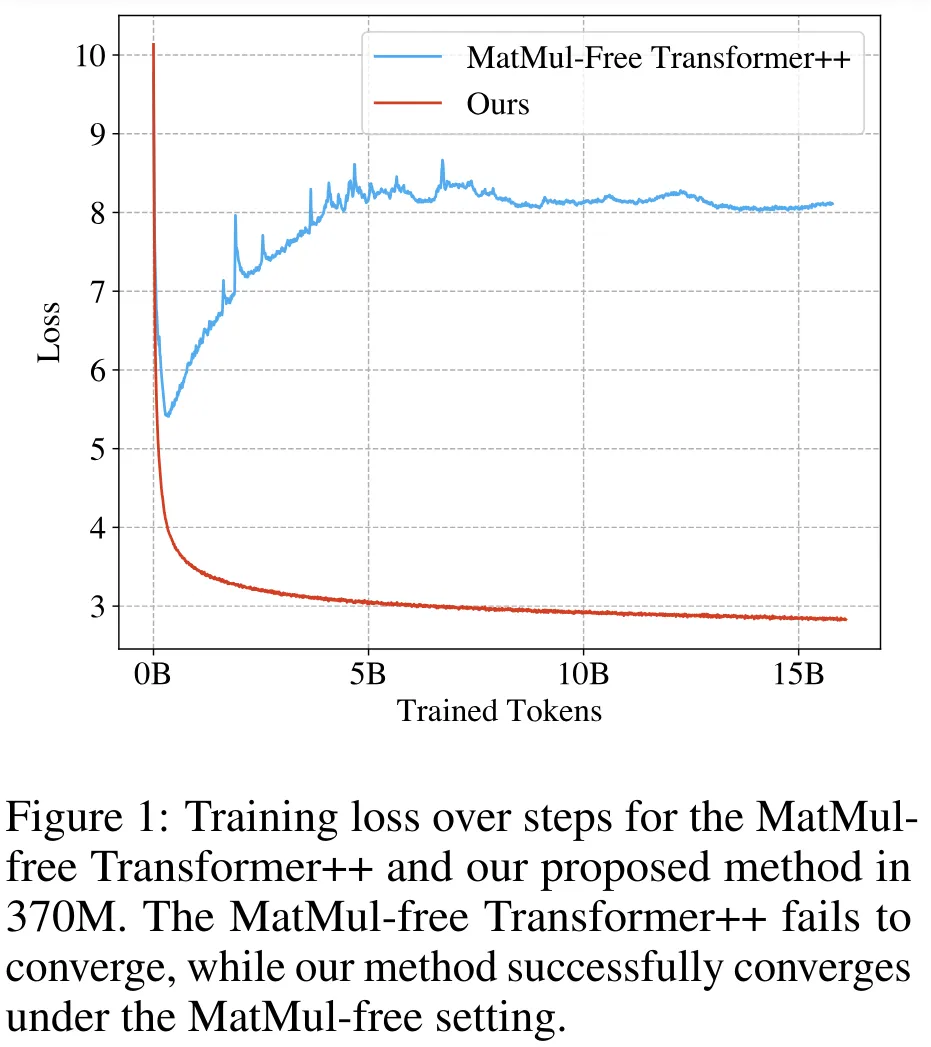
让语言模型「轻装上阵」。
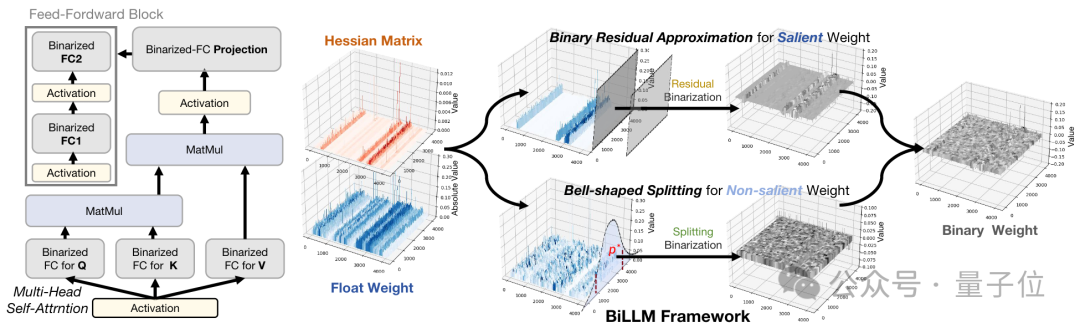
极限量化,把每个参数占用空间压缩到1.1bit!

使用大模型合成的数据,就能显著提升3D生成能力?

24点游戏、几何图形、一步将死问题,这些推理密集型任务,难倒了一片大模型,怎么破?北大、UC伯克利、斯坦福研究者最近提出了一种全新的BoT方法,用思维模板大幅增强了推理性能。而Llama3-8B在BoT的加持下,竟多次超越Llama3-70B!

大模型应用开卷,连一向保守的苹果,都已释放出发展端侧大模型的信号。

检索增强生成 (RAG) 是将检索模型与生成模型结合起来,以提高生成内容的质量和相关性的一种有效的方法。RAG 的核心思想是利用大量文档或知识库来获取相关信息。各种工具支持 RAG,包括 Langchain 和 LlamaIndex。

不使用外部工具也能让大语言模型(LLMs)实现严谨可信的推理,新国立提出 SymbCoT 推理框架:结合符号化逻辑(Symbolic Logical)表达式与思维链,极大提升推理质量,鲁棒性与可信度。