# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
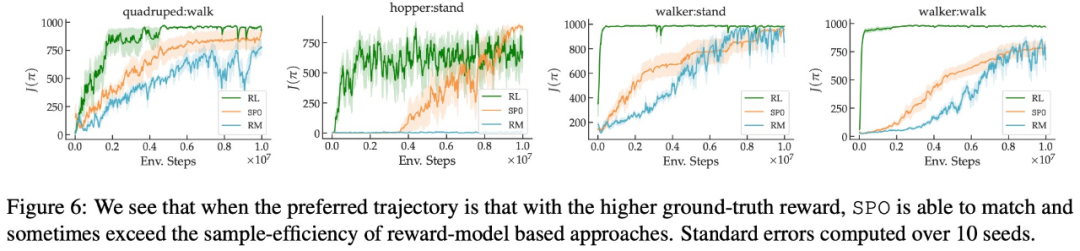
效果更稳定,实现更简单。
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。然后通过某种强化学习算法优化这个奖励函数。然而,奖励模型的关键要素可能会产生一些不良影响。
来自卡内基梅隆大学(CMU)和 Google Research 的研究者联合提出了一种简单的、理论上严格的、实验上有效的 RLHF 新方法 —— 自我博弈偏好优化(Self-Play Preference Optimization,SPO)。该方法消除了奖励模型,并且不需要对抗性训练。
论文:A Minimaximalist Approach to Reinforcement Learning from Human Feedback
论文地址:https://arxiv.org/abs/2401.04056
方法简介
SPO 方法主要包括两个方面。首先,该研究通过将 RLHF 构建为两者零和博弈(zero-sum game),真正消除了奖励模型,从而更有能力处理实践中经常出现的噪声、非马尔可夫偏好。其次,通过利用博弈的对称性,该研究证明可以简单地以自我博弈的方式训练单个智能体,从而消除了不稳定对抗训练的需要。
实际上,这相当于从智能体中采样多个轨迹,要求评估者或偏好模型比较每对轨迹,并将奖励设置为轨迹的获胜率。
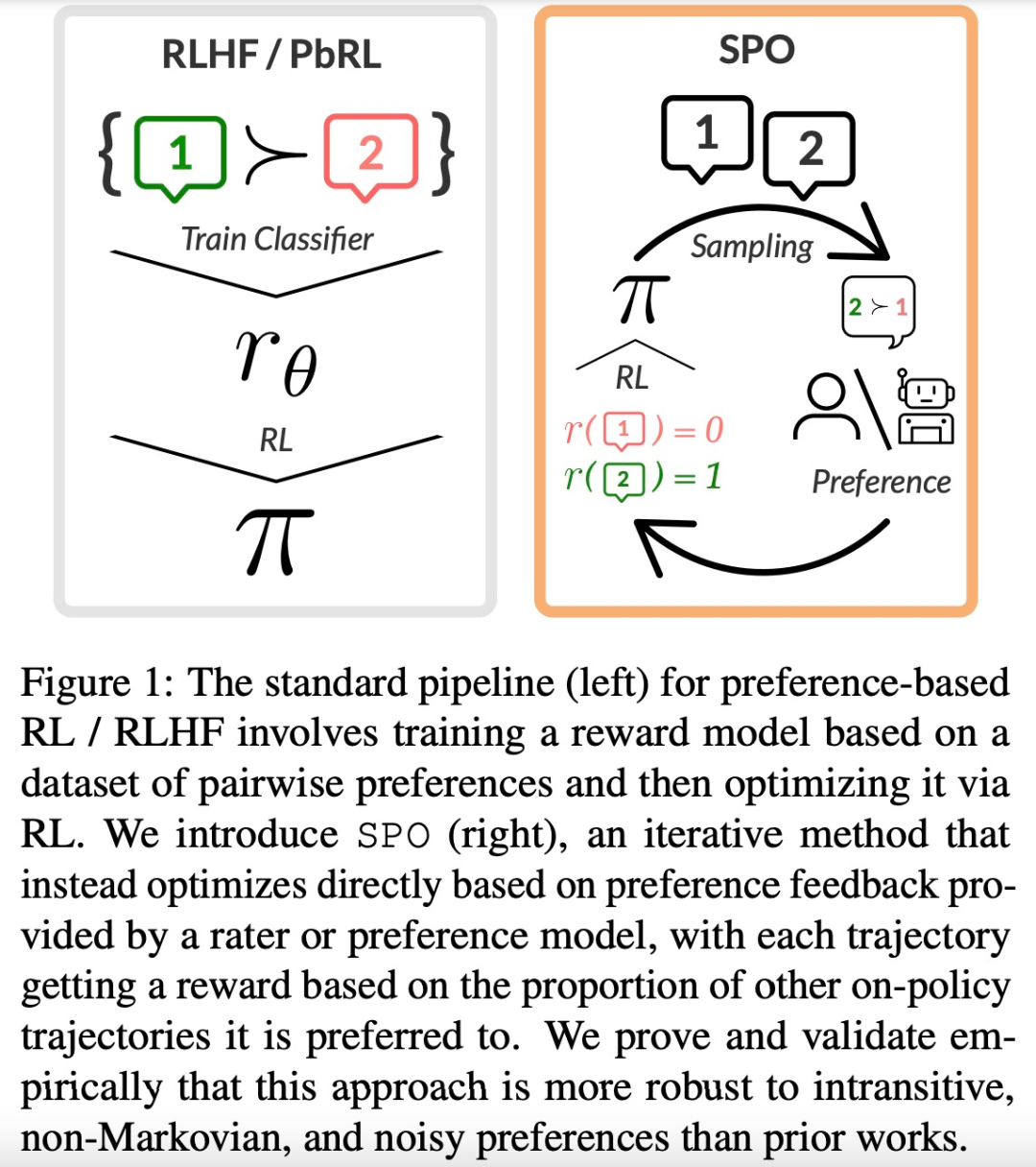
SPO 避免了奖励建模、复合 error 和对抗性训练。通过从社会选择理论(social choice theory)中建立最小最大获胜者的概念,该研究将 RLHF 构建为两者零和博弈,并利用该博弈支付矩阵的对称性来证明可以简单地训练单个智能体来对抗其自身。

该研究还分析了 SPO 的收敛特性,并证明在潜在奖励函数确实存在的情况下,SPO 能以与标准方法相媲美的快速速度收敛到最优策略。
实验
该研究在一系列具有现实偏好函数的连续控制任务上,证明了 SPO 比基于奖励模型的方法性能更好。SPO 在各种偏好设置中能够比基于奖励模型的方法更有效地学习样本,如下图 2 所示。
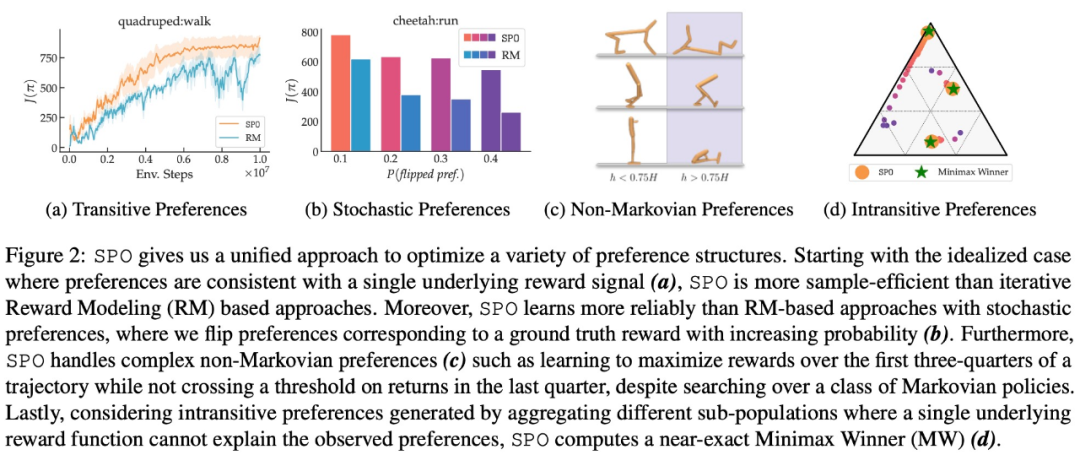
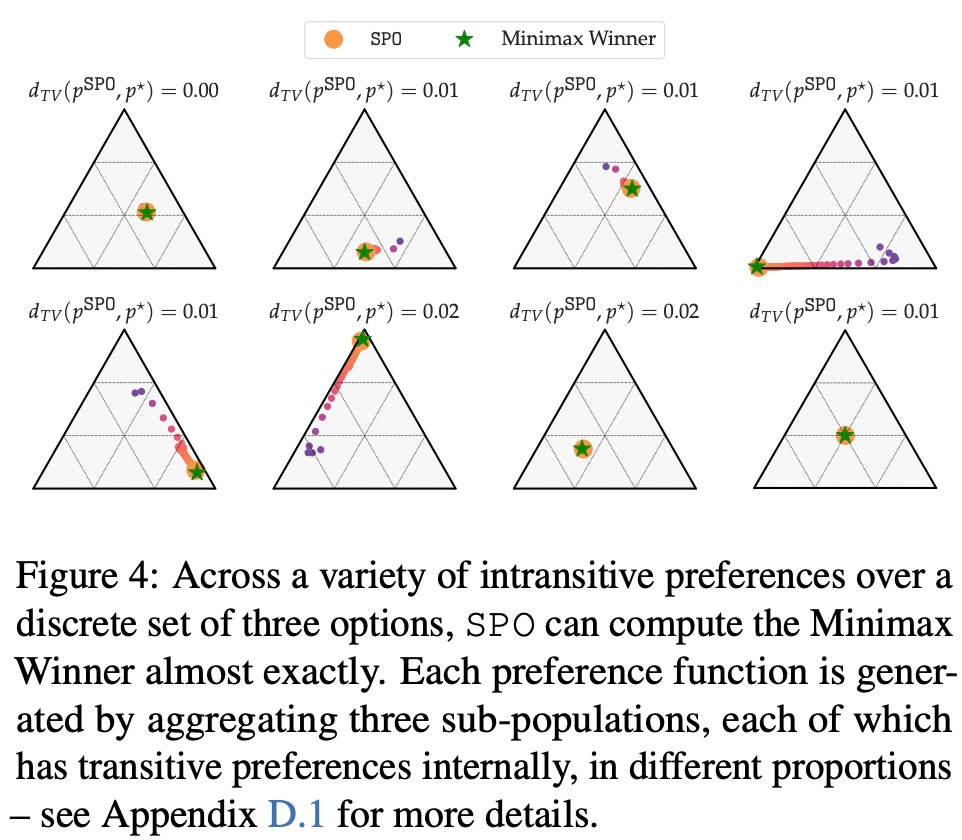
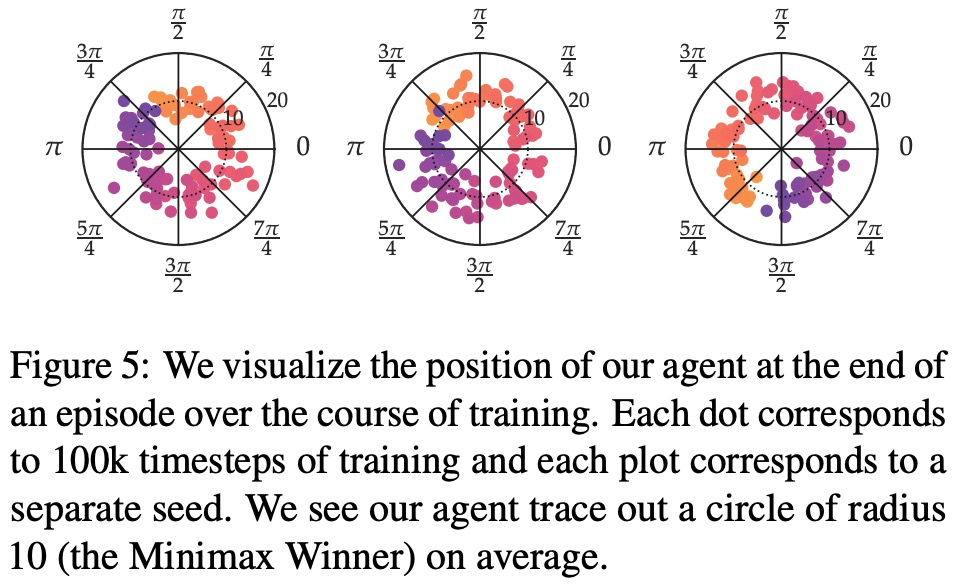
该研究从多个维度将 SPO 与迭代奖励建模 (RM) 方法进行比较,旨在回答 4 个问题:

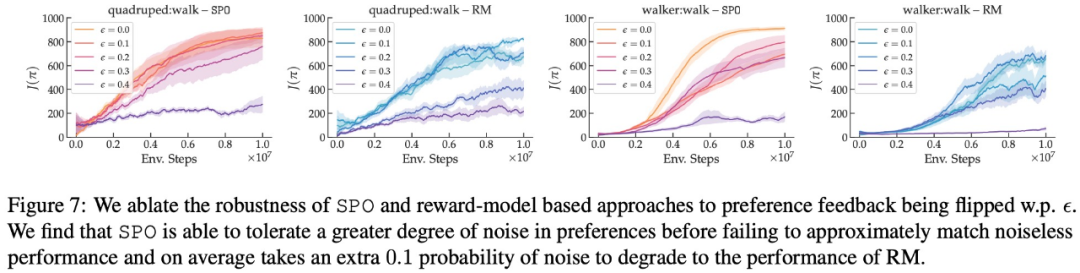
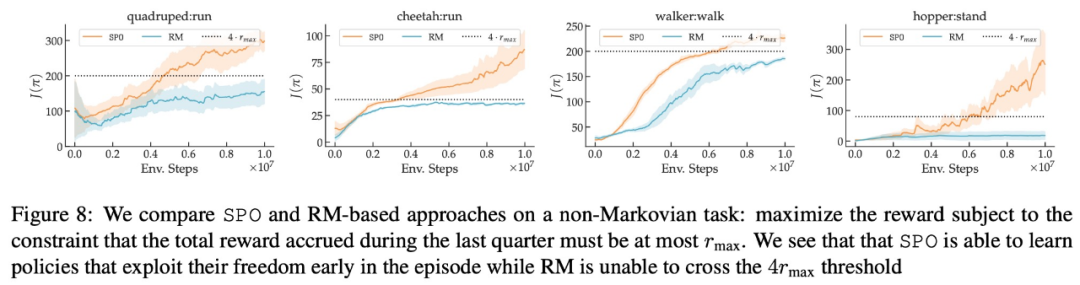
在最大奖励偏好、噪声偏好、非马尔可夫偏好方面,该研究的实验结果分别如下图 6、7、8 所示:
文章来自微信公众号 “ 机器之心 ”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
