
独家|ChatGPT核心贡献者姜旭归国创业:把LLM的Scaling带到具身智能
独家|ChatGPT核心贡献者姜旭归国创业:把LLM的Scaling带到具身智能姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。
来自主题: AI资讯
10614 点击 2026-05-22 10:26
 搜索
搜索
姜旭是少数完整参与过 OpenAI 大模型核心技术演进的华人创业者之一。2019 至 2023 年间,他经历了 GPT 系列能力爆发最关键的阶段,工作横跨底层训练 infra、大规模预训练、RLHF 对齐算法与数据构建等核心链路。

在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
近日, Anthropic 和斯坦福研究者 Neil Rathi 与这位传奇研究者联合发布了一篇新论文,并得到了一些相当惊人的新发现。在这项研究中,他们挑战了当前大模型安全领域的一个核心假设。长期以来,业界普遍认为要在模型发布后通过 RLHF 或微调来限制其危险行为。但 Neil Rathi 和 Alec Radford 提出了一种更本质的解法:

不要被AI的温柔表象欺骗! Anthropic最新研究刺穿了AGI的温情假象:你以为在和良师益友倾诉,其实是在悬崖边给「杀手」松绑。 当脆弱情感遇上激活值坍塌,RLHF防御层将瞬间溃缩。既然无法教化野兽,人类只能选择最冷酷的「赛博脑叶切除术」。

最近口述采样很火。如果您经常使用经过“对齐”训练(如RLHF)的LLM,您可能已经注意到一个现象:模型虽然变得听话、安全了,但也变得巨“无聊”。

结合RLHF+RLVR,8B小模型就能超越GPT-4o、媲美Claude-3.7-Sonnet。陈丹琦新作来了。他们提出了一个结合RLHF和RLVR优点的方法,RLMT(Reinforcement Learning with Model-rewarded Thinking,基于模型奖励思维的强化学习)。

一个月前,我们曾报道过清华姚班校友、普林斯顿教授陈丹琦似乎加入 Thinking Machines Lab 的消息。有些爆料认为她在休假一年后,会离开普林斯顿,全职加入 Thinking Machines Lab。
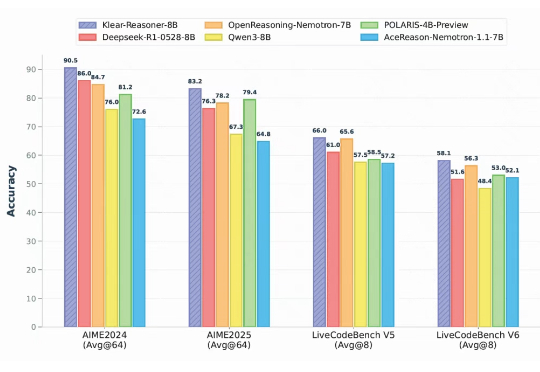
在大语言模型的竞争中,数学与代码推理能力已经成为最硬核的“分水岭”。从 OpenAI 最早将 RLHF 引入大模型训练,到 DeepSeek 提出 GRPO 算法,我们见证了强化学习在推理模型领域的巨大潜力。
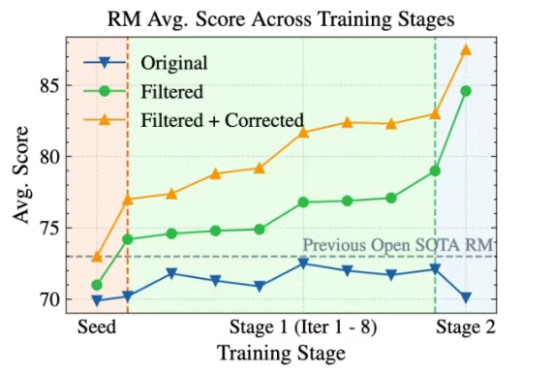
大语言模型(LLM)以生成能力强而著称,但如何能让它「听话」,是一门很深的学问。 基于人类反馈的强化学习(RLHF)就是用来解决这个问题的,其中的奖励模型 (Reward Model, RM)扮演着重要的裁判作用,它专门负责给 LLM 生成的内容打分,告诉模型什么是好,什么是不好,可以保证大模型的「三观」正确。
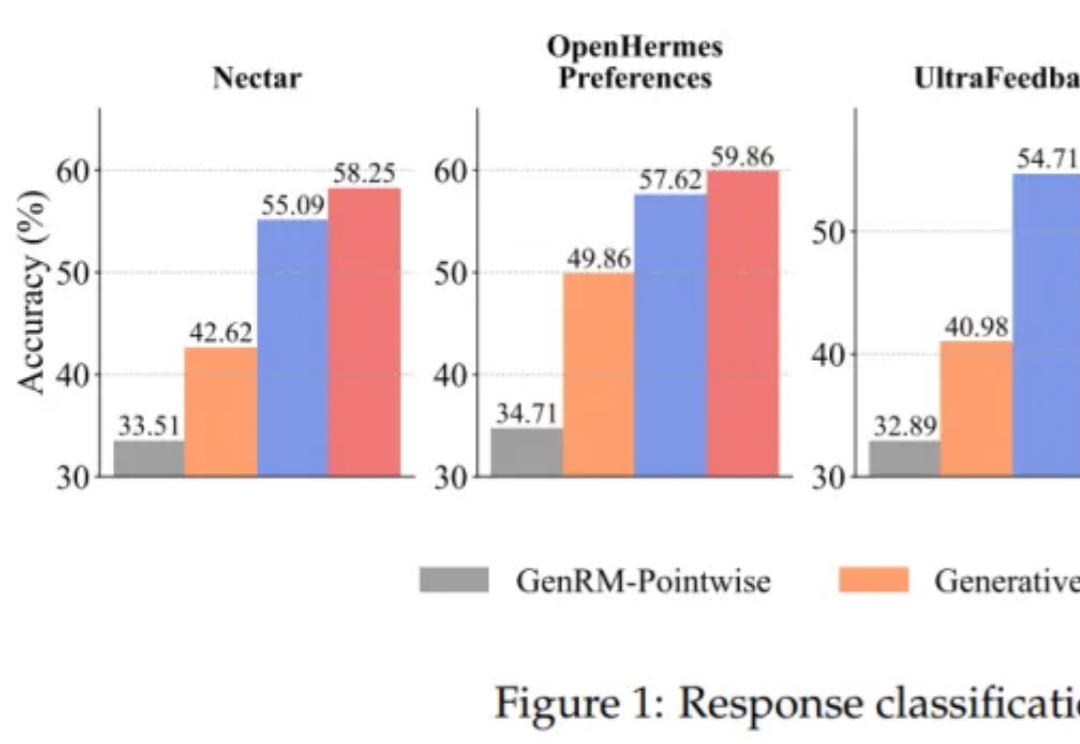
将大语言模型(LLMs)与复杂的人类价值观对齐,仍然是 AI 面临的一个核心挑战。当前主要的方法是基于人类反馈的强化学习(RLHF)。该流程依赖于一个通过人类偏好训练的奖励模型来对模型输出进行评分,最终对齐后的 LLM 的质量在根本上取决于该奖励模型的质量。