
2.5%KV缓存保持大模型90%性能,大模型金字塔式信息汇聚模式探秘|开源
2.5%KV缓存保持大模型90%性能,大模型金字塔式信息汇聚模式探秘|开源用KV缓存加速大模型的显存瓶颈,终于迎来突破。 北大、威斯康辛-麦迪逊、微软等联合团队提出了全新的缓存分配方案,只用2.5%的KV cache,就能保持大模型90%的性能。 这下再也不用担心KV占用的显存容量过高,导致显卡不够用了。
来自主题: AI技术研报
6748 点击 2024-06-13 21:21
 搜索
搜索
用KV缓存加速大模型的显存瓶颈,终于迎来突破。 北大、威斯康辛-麦迪逊、微软等联合团队提出了全新的缓存分配方案,只用2.5%的KV cache,就能保持大模型90%的性能。 这下再也不用担心KV占用的显存容量过高,导致显卡不够用了。

距上次Karpathy AI大课更新之后,又有了1个多月的时间。这次他带了超详细的4小时课程——从零开始实现1.24亿参数规模的GPT-2模型。

有了Adobe Firefly,对于专业人士而言显然不是个好消息。

Transformer很强,Transformer很好,但Transformer在处理时序数据时存在一定的局限性。

近些年,语言建模领域进展非凡。Llama 或 ChatGPT 等许多大型语言模型(LLM)有能力解决多种不同的任务,它们也正在成为越来越常用的工具。

大型语言模型(LLM)的一个主要特点是「大」,也因此其训练和部署成本都相当高,如何在保证 LLM 准确度的同时让其变小就成了非常重要且有价值的研究课题。

360 度场景生成是计算机视觉的重要任务,主流方法主要可分为两类,一类利用图像扩散模型分别生成 360 度场景的多个视角。由于图像扩散模型缺乏场景全局结构的先验知识,这类方法无法有效生成多样的 360 度视角,导致场景内主要的目标被多次重复生成,如图 1 的床和雕塑。

近年来兴起的第一人称视角视频研究为理解人类社交行为提供了无法取代的直观视角,然而,绝大多数的既往工作都侧重于分析与摄像机佩戴者相关的行为,并未关注处于社交场景中其他社交对象的状态。
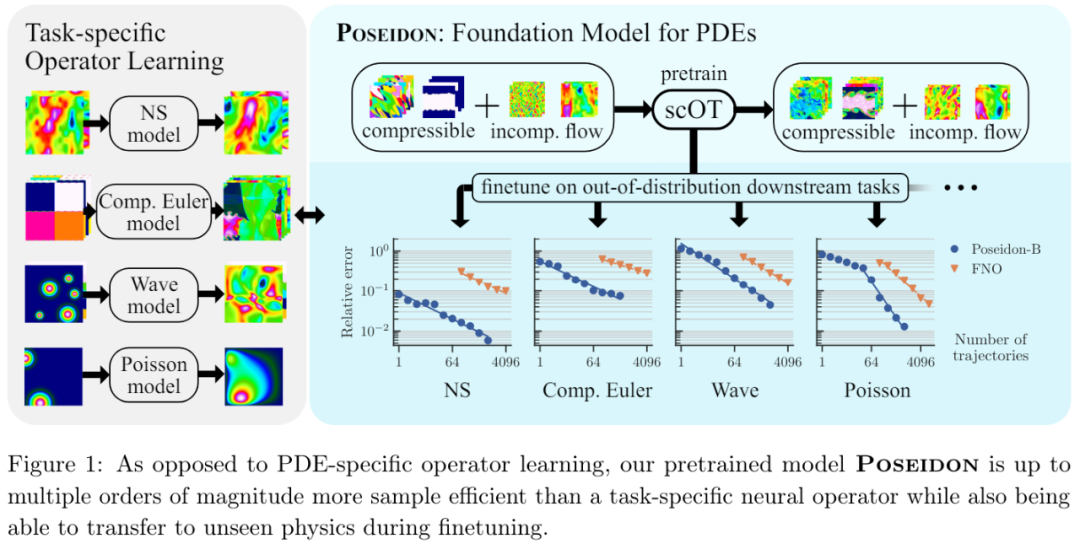
偏微分方程(PDEs)被称为物理学的语言,因为它们可以在广泛的时间 - 空间尺度上对各种各样的物理现象进行数学建模。常用的有限差分、有限元等数值方法通常用于近似或模拟偏微分方程。

AI 大牛 Andrej Karpathy 又「上新」了,这次一口气放出了长达四个小时的视频。