
37项SOTA!全模态预训练范式MiCo:理解任何模态并学习通用表示|港中文&中科院
37项SOTA!全模态预训练范式MiCo:理解任何模态并学习通用表示|港中文&中科院GPT-4o掀起一股全模态(Omni-modal)热潮,去年的热词多模态仿佛已经不够看了。
来自主题: AI技术研报
10937 点击 2024-06-16 17:50
 搜索
搜索
GPT-4o掀起一股全模态(Omni-modal)热潮,去年的热词多模态仿佛已经不够看了。

给人才充足的GPU,是很重要的!
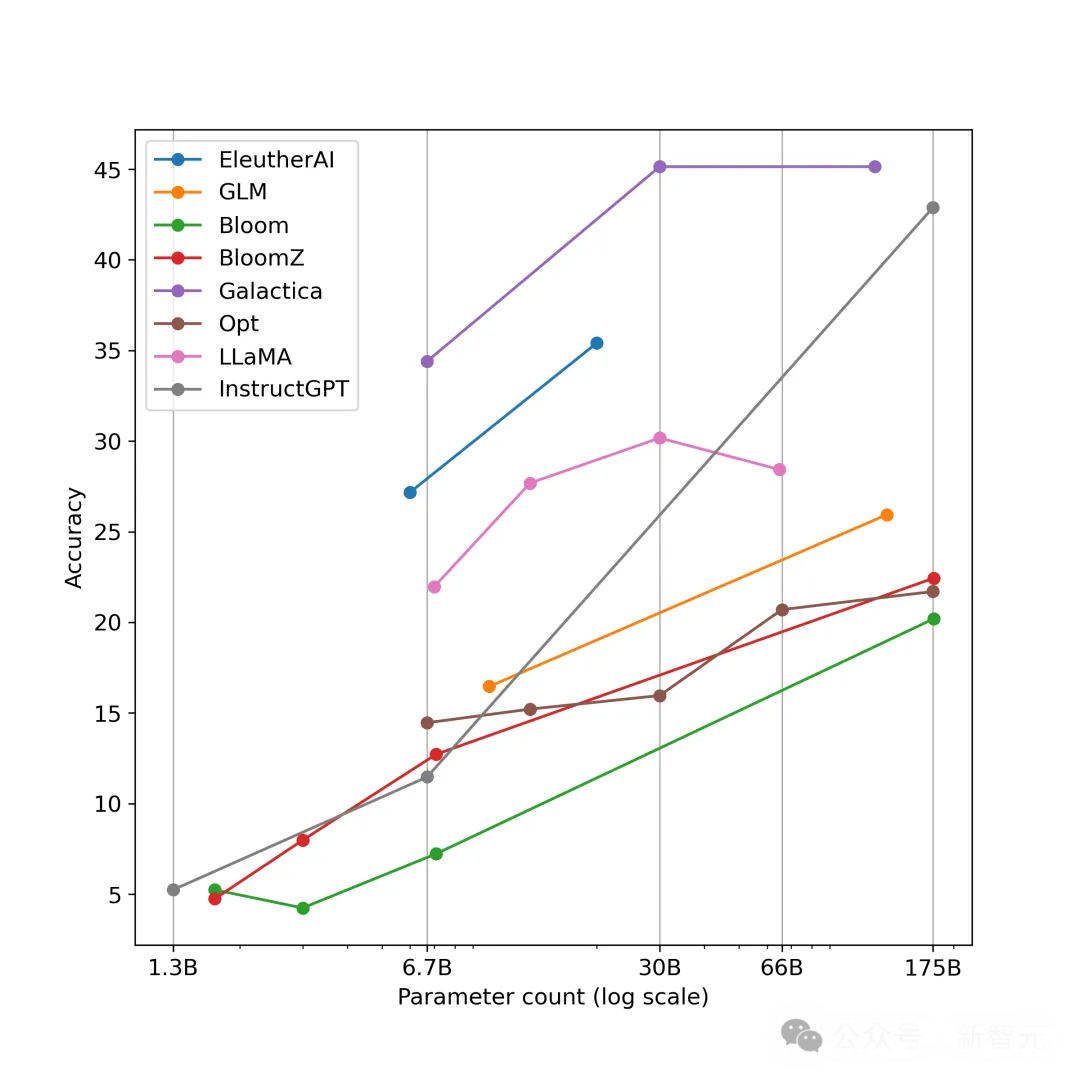
来自浙江大学和伊利诺伊大学厄巴纳-香槟分校的研究者发表了他们关于「表格语言模型」(Tabular Language Model)的研究成果

训练数据的数量和质量,对LLM性能的重要性已经是不言自明的事实。然而,Epoch AI近期的一篇论文却给正在疯狂扩展的AI模型们泼了冷水,他们预测,互联网上可用的人类文本数据将在四年后,即2028年耗尽。

刚刚,英伟达全新发布的开源模型Nemotron-4 340B,有可能彻底改变训练LLM的方式!从此,或许各行各业都不再需要昂贵的真实世界数据集了。而且,Nemotron-4 340B直接超越了Mixtral 8x22B、Claude sonnet、Llama3 70B、Qwen 2,甚至可以和GPT-4掰手腕!

人类的教育方式,对大模型而言也很适用。
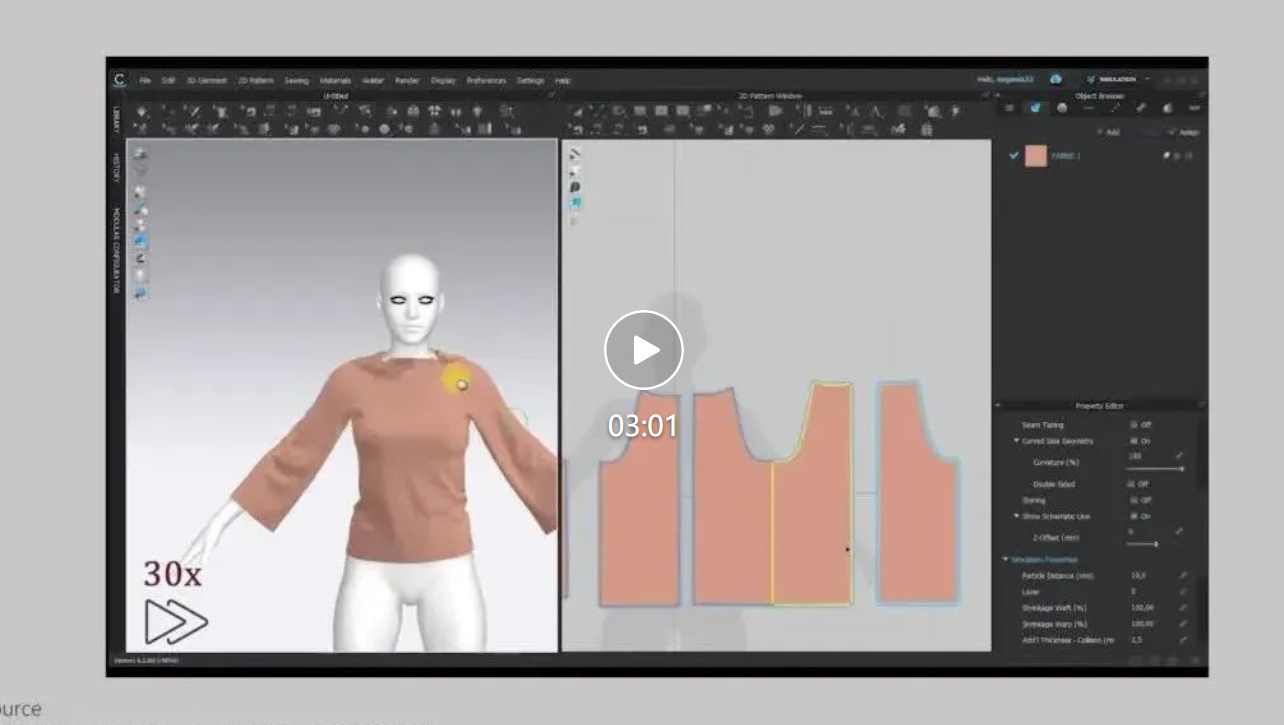
3D生成是生成式人工智能和计算机图形学领域最引人注目的话题之一,符合影视、游戏标准的3D生成尤其受产业界关注。在生产流程中,一般品类的3D资产往往通过手工建模或者扫描的方式制作。但作为3D资产的一个重要类别,服装资产的往往来源于平面板片与物理模拟等流程,而不是直接在3D上建模。
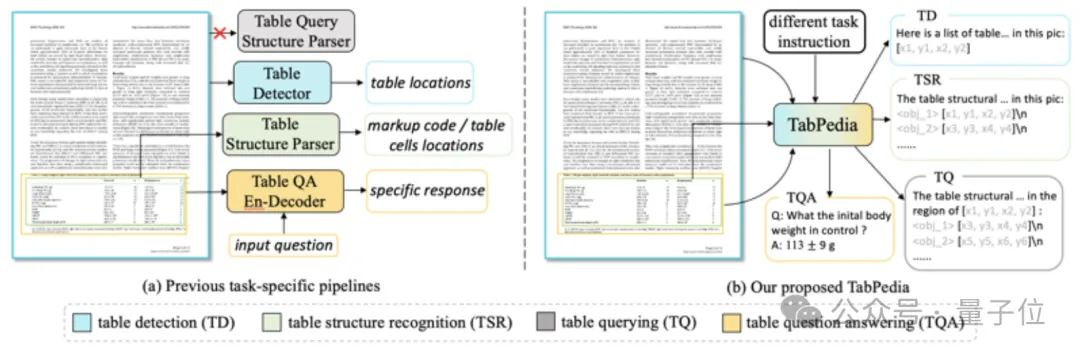
只要一个大模型,就能解决打工人遇到的表格难题!

在CV、ML等领域经常用到的神经场网格模型,如今有了理论框架描述其训练动力学和泛化性能。
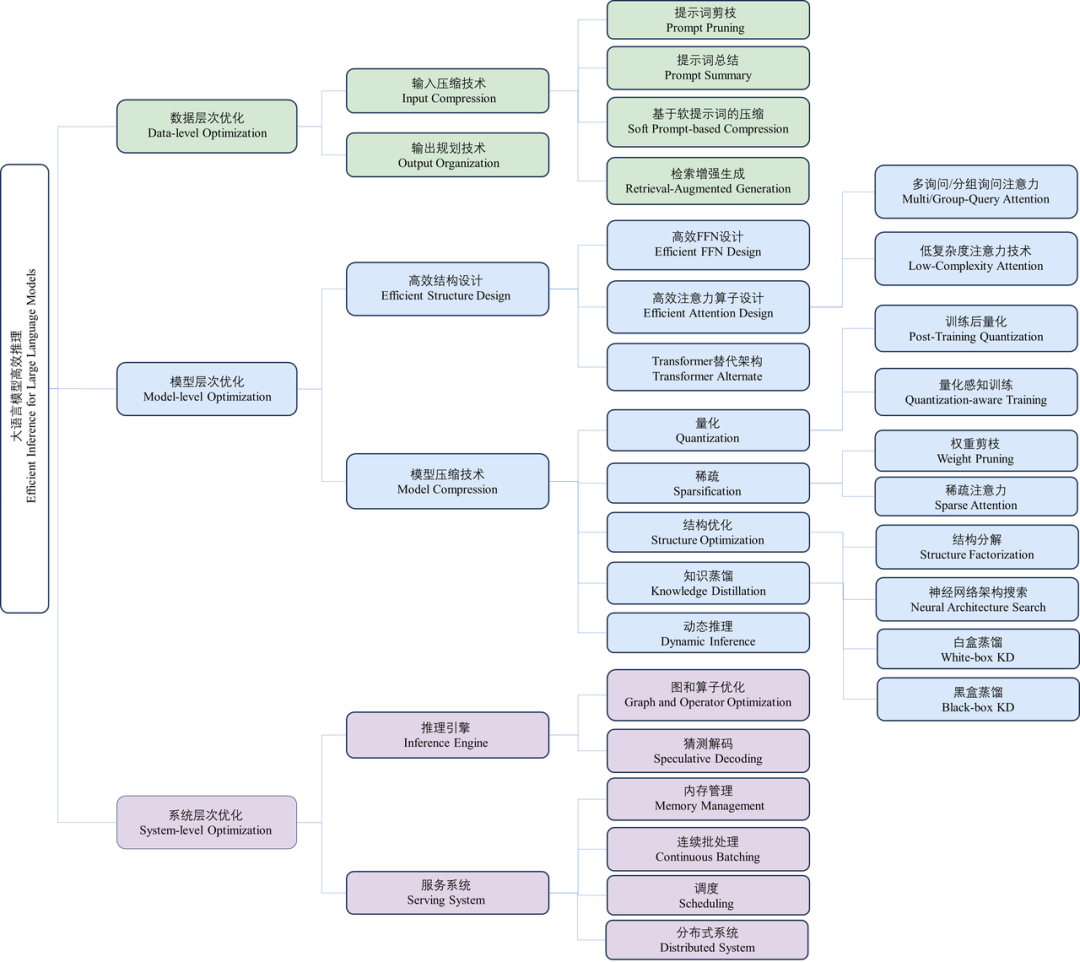
近年来,大语言模型(Large Language Models, LLMs)受到学术界和工业界的广泛关注,得益于其在各种语言生成任务上的出色表现,大语言模型推动了各种人工智能应用(例如ChatGPT、Copilot等)的发展。然而,大语言模型的落地应用受到其较大的推理开销的限制,对部署资源、用户体验、经济成本都带来了巨大挑战。