# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,大语言模型(Large Language Models, LLMs)受到学术界和工业界的广泛关注,得益于其在各种语言生成任务上的出色表现,大语言模型推动了各种人工智能应用(例如ChatGPT、Copilot等)的发展。然而,大语言模型的落地应用受到其较大的推理开销的限制,对部署资源、用户体验、经济成本都带来了巨大挑战。例如,将包含700亿参数量的LLaMA-2-70B模型进行部署推理,至少需要6张RTX 3090Ti显卡或2张NVIDIA A100显卡,以部署在A100显卡上为例,该模型生成512长度的词块(token)序列需要耗时超过50秒。
许多研究工作致力于设计优化大语言模型推理开销的技术,优化模型的推理延迟、吞吐、功耗和存储等指标,成为许多研究的重要目标。为了对这些优化技术有更全面、更系统的认知,为大语言模型的部署实践和未来研究提供建议和指南,来自清华大学电子工程系、无问芯穹和上海交通大学的研究团队对大语言模型的高效推理技术进行了一次全面的调研和整理,在《A Survey on Efficient Inference for Large Language Models》(简称LLM Eff-Inference)这篇万字长文综述将领域相关工作划分归类为三个优化层次(即数据层、模型层和系统层),并逐个层次地介绍和总结相关技术工作。此外,该工作还对造成大语言模型推理不高效的根本原因进行分析,并基于对当前已有工作的综述,深入探讨高效推理领域未来应关注的场景、挑战和路线,为研究者提供可行的未来研究方向。
图注:《A Survey on Efficient Inference for Large Language Models》(LLM Eff-Inference)
一、大模型推理效率瓶颈分析
目前主流的大语言模型都是基于Transformer架构进行设计。通常来说,一个完整的模型架构由多个相同结构的Transformer块组成,每个Transformer块则包含多头自注意力(Multi-Head Self-Attention, MHSA)模块、前馈神经网络(Feed Forward Network, FFN)和层归一化(Layer Normalization,LN)操作。
大语言模型通常自回归(Auto-regressive)的方式生成输出序列,即模型逐个词块生成,且生成每个词块时需要将前序的所有词块(包括输入词块和前面已生成的词块)全部作为模型的输入。因此,随着输出序列的增长,推理过程的开销显著增大。为了解决该问题,KV缓存技术被提出,该技术通过存储和复用前序词块在计算注意力机制时产生的Key和Value向量,减少大量计算上的冗余,用一定的存储开销换取了显著的加速效果。基于KV缓存技术,通常可以将大语言模型的推理过程划分为两个阶段(分别如下图中(a)和(b)所示):
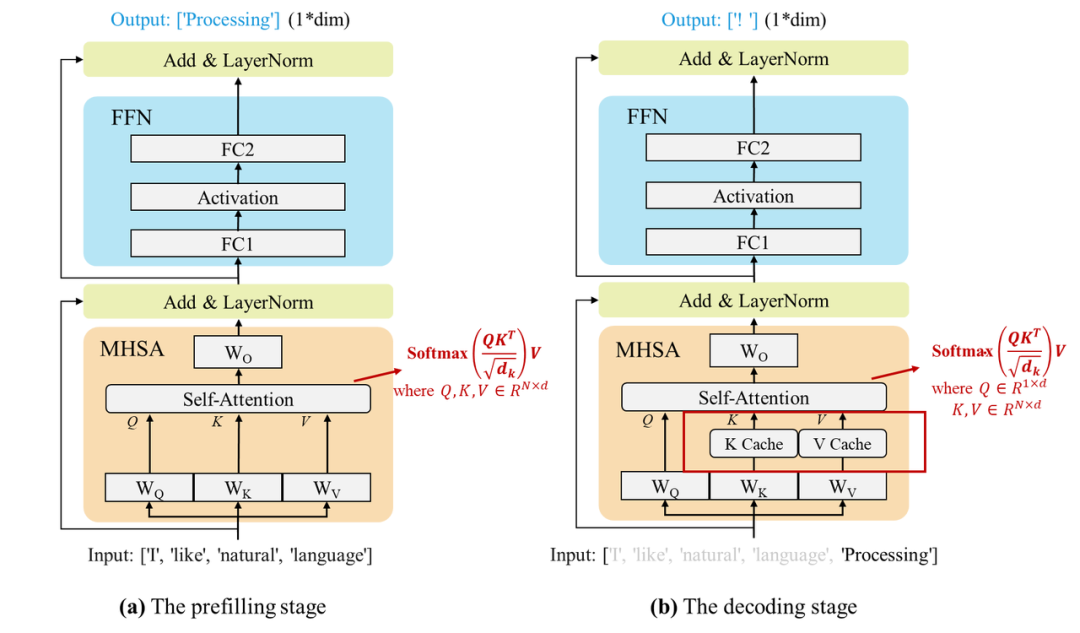
图注:大语言模型推理的两个阶段,即预填充阶段(a)和解码阶段(b)
大语言模型在实际部署应用中,我们通常关注其延时、吞吐、功耗和存储,而在大语言模型推理过程中,有三个重要因素会直接影响上述效率指标,分别是计算开销(Computational Cost)、访存开销(Memory Access Cost)和存储开销(Memory Cost)。进一步地,本综述深入分析探究,并总结归纳除出影响上述指标和因素三点根本因素,分别为:

图注:大语言模型推理效率瓶颈分析图示
二、大模型高效推理技术领域纵览
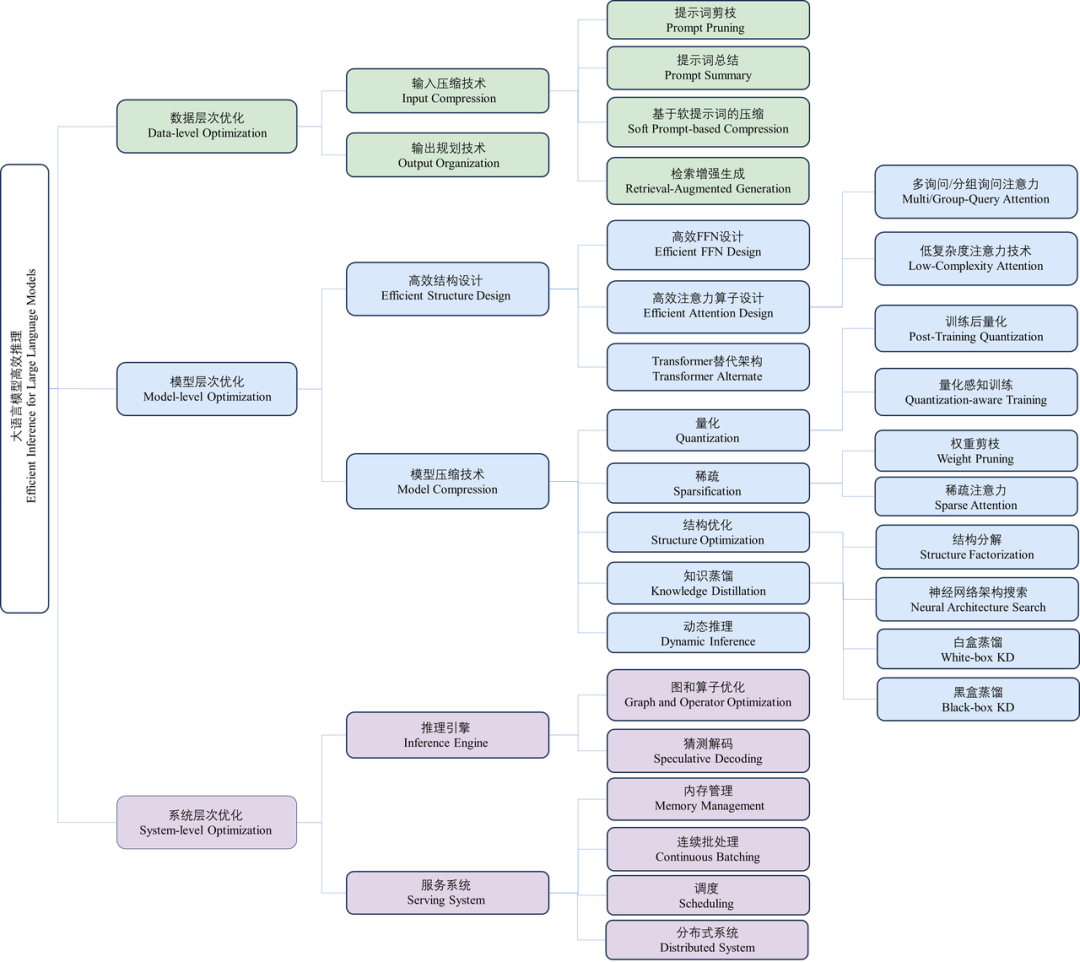
本综述将大语言模型高效推理领域的技术划分为三个层次,分别为:
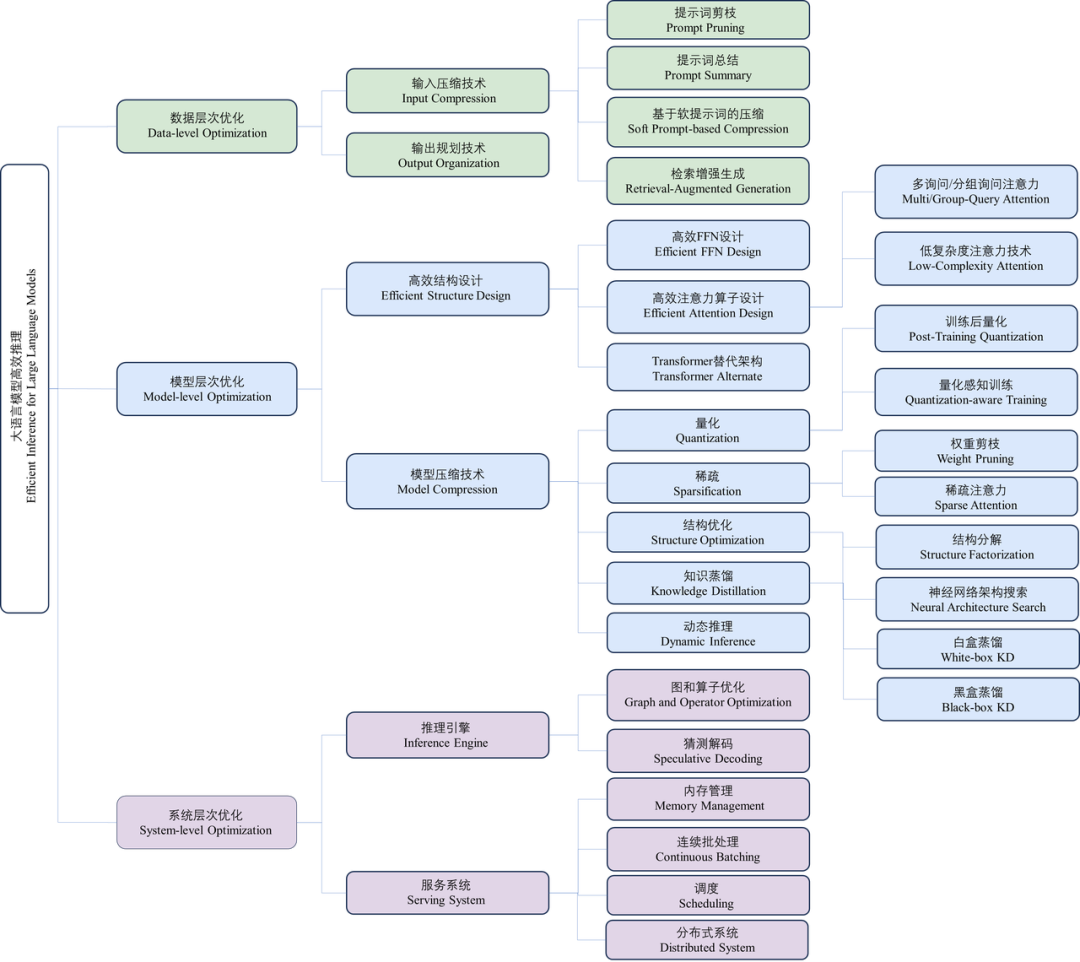
图注:本综述的分类体系
2.1 数据层优化技术
数据层优化技术可以划分为两大类:输入压缩(Input Compression)和输出规划(Output Organization)。
2.1.1 输入压缩技术
在实际利用大语言模型做回答时,通常会在输入提示词中加入一些辅助内容来增强模型的回答质量,例如,上下文学习技术(In-Context Learning,ICL)提出在输入中加入多个相关的问答例子来教模型如何作答。然而,这些技术不可避免地会增长输入词提示的长度,导致模型推理的开销增大。为了解决该问题,输入压缩技术通过直接减小输入的长度来优化模型的推理效率。
本综述将该类技术进一步划分为四个小类,分别为:
2.1.2 输出规划技术
传统的生成解码方式是完全串行的,输出规划技术通过规划输出内容,并行生成某些部分的的输出来降低端到端的推理延时。以该领域最早的工作“思维骨架”(Skeleton-of-Thought,以下简称SoT)[45](无问芯穹于2023年7月发布的工作,并被ICLR2024录用)为例,SoT技术的核心思想是让大语言模型自行规划输出的并行结构,并基于该结构进行并行解码,提升硬件利用率,减少端到端生成延时。
具体来说,如下图所示,SoT将大语言模型的生成分为两个阶段:在提纲阶段,SoT通过设计的提示词让大语言模型输出答案的大纲;在分点扩展阶段,SoT让大语言模型基于大纲中的每一个分点并行做扩展,最后将所有分点扩展的答案合并起来。SoT技术让包含LLaMA-2、Vicuna模型在内的9种主流大语言模型的生成过程加速1.9倍以上,最高可达2.39倍。在SoT技术发布后,一些研究工作通过微调大语言模型、前后端协同优化等方式优化输出规划技术,达到了更好的加速比和回答质量之间的权衡点。
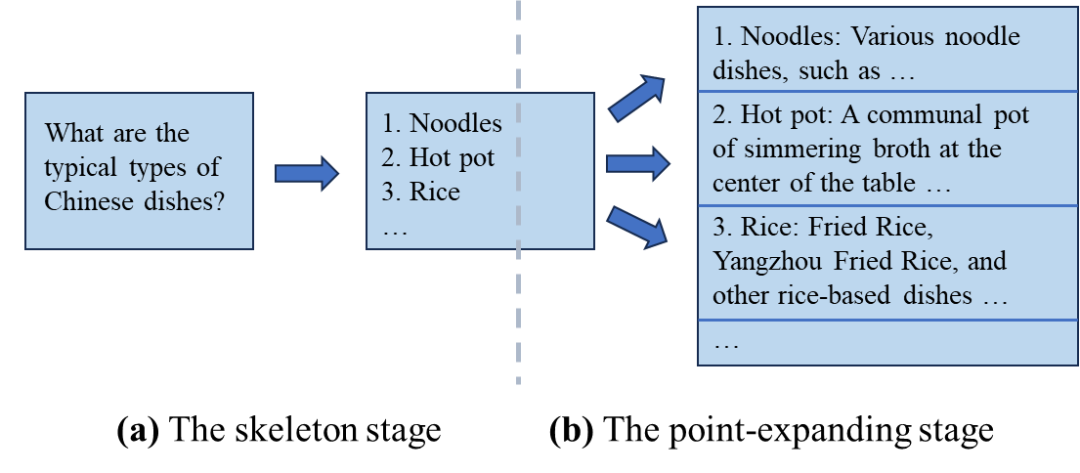
图注:输出规划技术SoT[45]示意
2.1.3 知识、建议和未来方向
随着大语言模型需要处理的输入提示词和模型的输出结果越来越长,数据层的优化技术越来越重要。在这类技术中,输入压缩技术主要优化预填充阶段中注意力算子带来的平方量级的计算和存储开销,而输出规划技术则主要通过降低解码阶段中大量的访存开销,此外,一些研究尝试利用大语言模型本身做输出规划,并取得了不错的效果。
最近,各种各样新的提示词流程(Prompting Pipelines)和大语言模型智能体(LLM Agents)出现,这些新的框架在增强大语言模型能力的同时,也引入了更长的输入提示。利用输入压缩技术可以有效优化此类问题,同时,这些流程和智能体框架在输出内容中引入了更多可并行性,因此输出规划技术可能会在优化这类框架的效率上起到关键作用。除此之外,还有一些新工作关注如何直接设计更高效的智能体框架。
2.2 模型层优化技术
模型层优化技术可以划分为两大类:高效结构设计(Efficient Structure Design)和模型压缩(Model Compression)。前者通常需要将新设计的模型从头进行预训练,而后者通常只需要微调恢复精度即可。
2.2.1 高效结构设计
目前主流的大语言模型大多采用Transformer架构,从结构上看,参数量占比最多的前馈神经网络(以下简称FFN)和平方复杂度的注意力算子是导致模型推理效率低下的主要原因。基于此,本文将高效结构设计领域的技术进一步划分为三类:
????高效FFN设计(Efficient FFN):该领域的主流方法为混合 专家(Mixture-of-Experts,MoE)技术,其核心是为不同的输入词块分配不同数量的FFN(称为专家),减少推理过程中被激活的FFN权重数量。基于MoE的Transformer模型除了包含若干个专家FFN外,还包含一个负责分配专家的路由(Router)模型。该领域的研究工作主要关注三个方向:
????高效注意力算子设计(Efficient Attention):该领域的研究工作可以分为:
????Transformer替代架构(Transformer Alternates):最新的研究工作逐渐关注于设计新的模型架构来取代Transformer架构,这些新模型架构大多具有线性或近似线性的复杂度,在处理文本长度较长时有显著的性能优势。本综述将这类工作总结为两大类:

图注:典型Transformer替代架构的训练和推理复杂度(n表示序列长度,d表示隐表征维度)
2.2.2 模型压缩技术
本综述将大语言模型高效推理领域的技术划分为三个层次,分别为:
????模型量化(Model Quantization):模型量化是一类应用广泛的模型压缩技术,其通过将模型的权重从高比特数转换成低比特数来降低模型的计算和存储开销。值得注意的是,大模型在推理的不同阶段有不一样的效率瓶颈,因此需要适配不同的量化方法。在预填充阶段,推理效率主要受限于较高的计算量,因此通常采用权重激活量化(Weight-Activation Quantization)的方式;在解码阶段,推理效率主要受限于较高的访存量,因此通常采用仅权重量化(Weight-only Quantization)的方式。从量化流程来看,模型量化可以划分为:
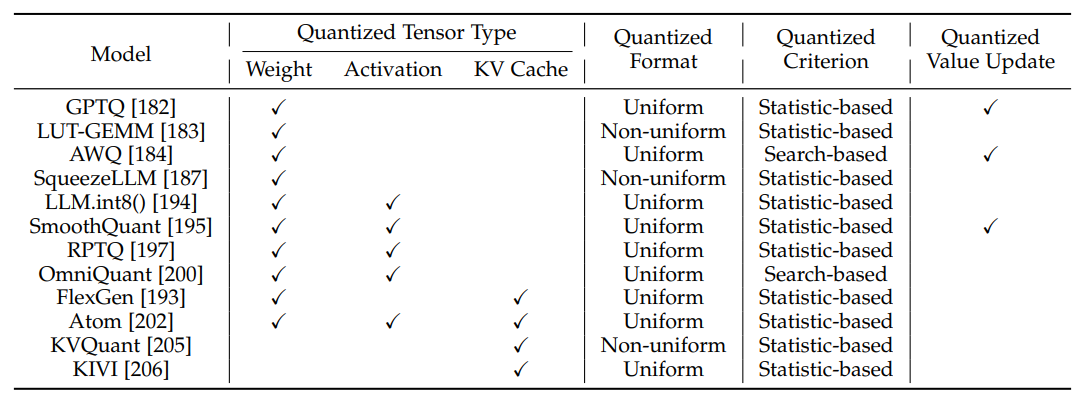
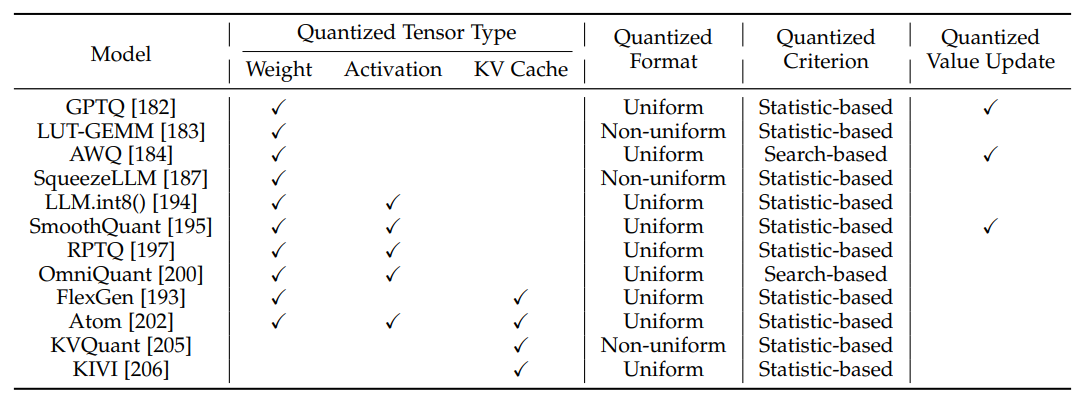
图注:典型的训练后量化算法的比较
????模型稀疏(Model Sparsification)。模型稀疏分为权重稀疏(即权重剪枝)和注意力稀疏(即稀疏注意力):
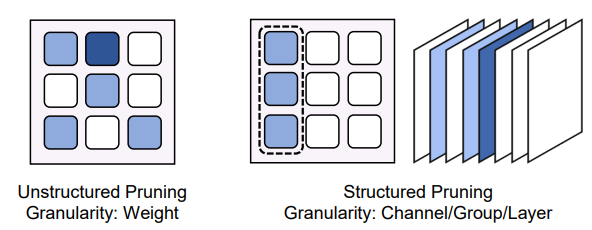
图注:非结构化剪枝和结构化剪枝比较
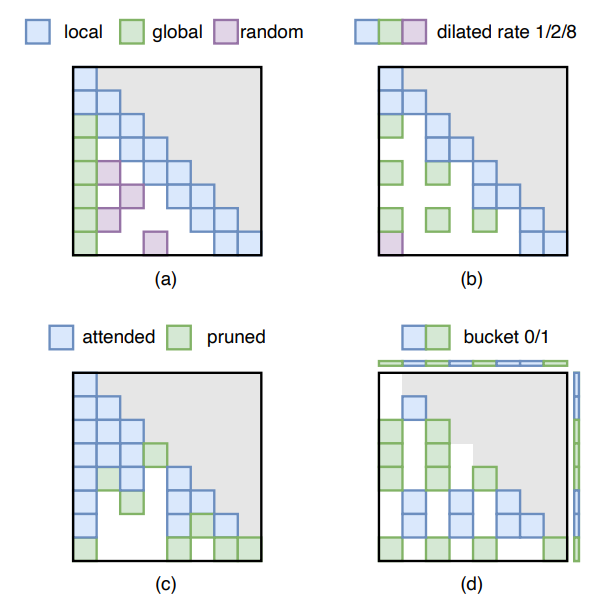
图注:典型注意力稀疏模式比较
????结构优化(Structure Optimization):结构优化技术指通过修改模型的架构或结构来达到更好的精度-效率之间的权衡。在该领域有两类代表性的技术:
????知识蒸馏(Knowledge Distillation):知识蒸馏指用一个大模型(教师模型)来辅助训练一个小模型(学生模型),从而将大模型的知识传递给小模型,通过小模型更小的开销达到相似的精度效果。知识蒸馏主要分为白盒(White-box)和黑盒(Black-box),前者可以获得教师模型的架构和权重,因此可以利用更多的信息(例如特征、输出概率等)训练学生模型,而后者多针对基于API接口访问的大模型,这类模型的架构和权重无法获取,因此仅能通过构造数据来训练学生模型。在知识蒸馏领域,当前的研究工作主要关注设计更有效的蒸馏损失函数,以及构造更有效的蒸馏数据来辅助学生模型的学习。
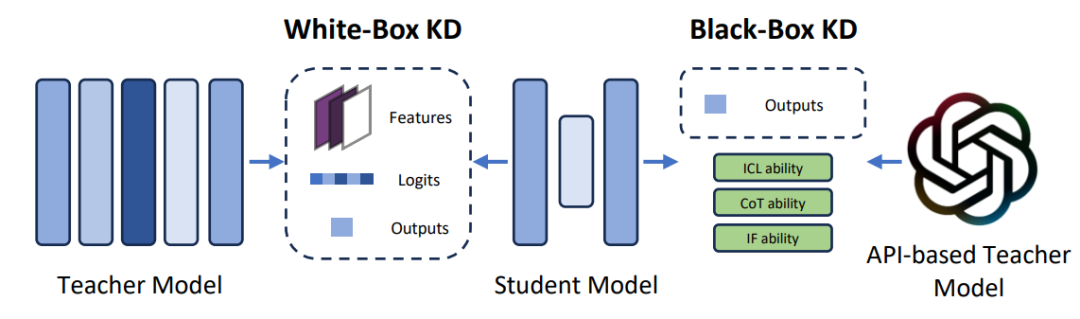
图注:白盒蒸馏和黑盒蒸馏比较
????动态推理(Dynamic Inference):动态推理技术指在推理过程中,基于输入数据的不同,动态决定最合适的推理结构。根据所依赖的输入数据维度,可以进一步将该领域的技术分为样本级别(Sample-level)和词块级别(Token-level)的动态推理。该领域的研究方向主要聚焦于设计更有效的退出模块,以及解决大语言模型解码过程中并行推理和KV缓存的问题。
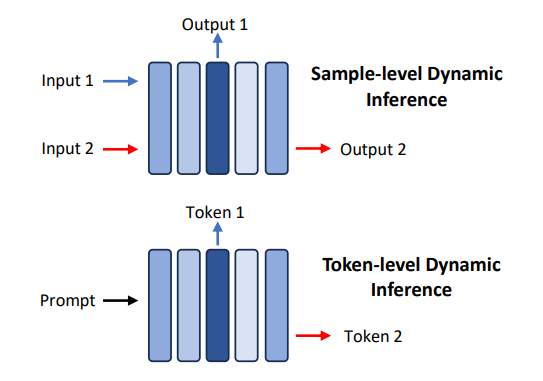
图注:样本级别和词块级别的动态推理比较
2.2.3 知识、建议和未来方向
在高效结构设计领域,Transformer的替代架构受到了许多研究者们的关注,诸如Mamba[73]、RWKV[60]以及它们的变体架构都在各类任务上验证了它们高效的推理能力。然而,这些新架构相比Transformer架构在某些方面是否仍然存在缺陷还并未被探究清楚。此外,本文认为将新架构和传统的Transformer架构做融合,可以达到效率和精度之间更好的权衡,是一个有潜力的研究方向。
在模型压缩领域:
2.3 系统层优化技术
大语言模型推理的系统层优化主要集中在优化模型的前向推理过程。在大语言模型的前向推理计算图中,注意力算子和线性算子占据了大部分运行时间。系统层优化技术包含对这两种算子的优化,同时还会考虑设计更高效的大语言模型解码方式。此外,在在线服务的场景中,请求通常来自多个用户。因此,除了前述优化之外,在线服务还面临与异步请求相关的内存、批处理和调度方面的挑战。总的来说,本综述将系统层优化技术分为高效的推理引擎(Inference Engine)和服务系统(Serving System)。
2.3.1 推理引擎
图和算子优化(Graph and Operator Optimization)是高效推理引擎技术中重要的一类方法,其中,算子优化还进一步包含对注意力算子和线性算子的优化。无问芯穹于2023年11月发布的工作FlashDecoding++[231](已被MLSys2024录用),通过对注意力和线性算子的针对性优化和计算图层面的深度算子融合技术,显著提高了大语言模型推理效率,在NVIDIA和AMD GPU上,吞吐率相较HuggingFace提升分别达到4.86和4.35倍。
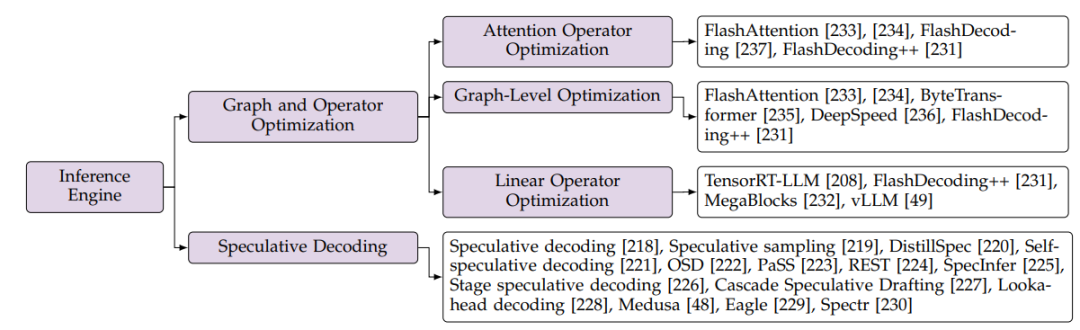
图注:高效推理引擎领域研究总结
猜测解码(Speculative Decoding)是一类通过并行解码来加速大模型解码过程的技术,其核心思想是使用一个小模型来预测未来的若干个词块,再用大模型并行地验证这些词块是否准确。具体来说,猜测解码可以大致分为两个阶段:猜测阶段和验证阶段。
猜测阶段,对于当前的输入文本,猜测解码方法首先利用一个“便宜”的草稿模型(Draft Model)生成连续的若干个草稿词块(Draft Token),值得注意的是,该草稿模型往往具有相比于大语言模型小得多的参数量和计算量,因此这一过程带来的开销非常小。
验证阶段,猜测编码使用大语言模型对草稿词块进行并行验证,并接收通过验证的草稿词块作为解码结果。猜测编码的加速效果与草稿模型的预测准确率和验证接收方式有关,现有大多研究工作关注于设计更好的草稿模型,或设计更有效的验证接收方式。下表对比了典型的猜测解码算法。

图注:典型猜测解码算法比较
2.3.2 服务系统
服务系统的优化旨在提升系统处理异步请求的效率。这类优化技术主要包括:内存管理(Memory Management)、连续批处理(Continuous Batching )、调度策略(Scheduling Strategy)和分布式系统( Distributed Systems)。此外,本文还比较了市面上常见的开源推理框架的推理延时和系统吞吐,如下表所示。
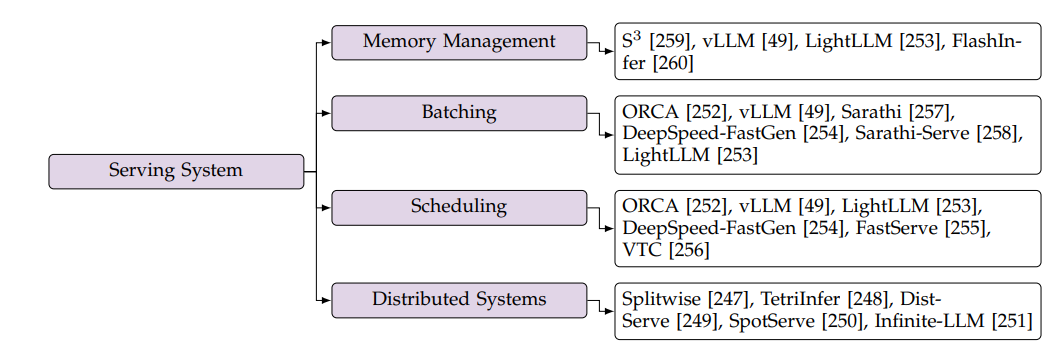
图注:高效服务系统领域研究总结

图注:开源推理框架比较
2.3.3 知识、建议和未来方向
系统层优化技术在不降低准确性的情况下提高了推理效率,因此在大语言模型的时间部署中非常普遍。在最近的研究中,算子优化已经与实际的服务场景密切结合,例如,RadixAttention[50]专门被设计用于前缀缓存,而tree attention技术[225]用于加速猜测解码的验证。应用和场景的更迭将继续为算子的发展提出新的要求和挑战。
三、未来研究展望
本文进一步总结了未来的四个关键应用场景,并讨论了高效性研究在这些场景中的重要性:
文章来源于“机器之心”,作者“宁雪妃、周紫轩(无问芯穹TechView)”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
